 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniQL: Towards Dialect-Universal Benchmarking for Text-to-SQL
Jun 06, 2026Existing text-to-SQL benchmarks are largely centered on SQLite, making it difficult to evaluate whether models can generalize across heterogeneous SQL dialects. However, real-world database systems differ substantially in syntax, functions, type systems, and execution semantics, so the same natural language intent often requires dialect-specific SQL realizations. We introduce UniQL, a human-verified benchmark for cross-dialect text-to-SQL evaluation. UniQL aligns 1,534 natural language questions with executable SQL annotations across 16 SQL dialects, yielding 24,544 dialect-specific queries. All dialects share the same intents, aligned schemas and database contents, enabling controlled evaluation of dialect generalization. UniQL is constructed through a hybrid pipeline combining database migration, SQL translation, execution-guided verification, iterative rule summarization, and human validation. Experiments on both open-source and closed-source LLMs show that current models remain far from dialect-universal, with substantial performance variation across database systems and limited transfer from SQLite success to other dialects. These findings highlight the need for aligned cross-dialect benchmarks and more dialect-aware text-to-SQL methods. Code and data are available at https://github.com/JerryGao818/UniQL
Unsat Core Prediction through Polarity-Aware Representation Learning over Clause-Literal Hypergraphs
May 06, 2026Graph neural networks have been widely used in Boolean satisfiability (SAT) tasks to learn structural information from SAT formulas. The goal of these studies is to solve SAT instances or to enhance SAT solvers, including tasks such as unsat-core prediction. However, most existing approaches model a SAT formula as a bipartite graph or a directed acyclic graph, which are less expressive in capturing higher-order interactions among literals and clauses. Moreover, these approaches are limited in modeling intrinsic polarity-related properties of SAT, such as the complementary relationship between the positive and negative literals of a variable. To address these limitations, we propose a polarity-aware representation learning framework over clause-literal hypergraphs. We model SAT formulas as clause-literal hypergraphs augmented with a clause incidence graph to capture higher-order structural interactions. We then introduce a polarity-aware decomposed mechanism that separates variable representations into polarity invariant and equivariant components, explicitly modeling the relationship between positive and negative literals, with the resulting literal representations propagated along the hypergraph structure. We further incorporate a polarity-inversion consistency regularization to reinforce polarity-consistent representations during training. Experimental results on multiple SAT datasets demonstrate the effectiveness of the proposed approach.
Breaking Block Boundaries: Anchor-based History-stable Decoding for Diffusion Large Language Models
Apr 10, 2026Diffusion Large Language Models (dLLMs) have recently become a promising alternative to autoregressive large language models (ARMs). Semi-autoregressive (Semi-AR) decoding is widely employed in base dLLMs and advanced decoding strategies due to its superior performance. However, our observations reveal that Semi-AR decoding suffers from inherent block constraints, which cause the decoding of many cross-block stable tokens to be unnecessarily delayed. To address this challenge, we systematically investigate the identification of stable tokens and present three key findings: (1) naive lookahead decoding is unreliable, (2) token stability closely correlates with convergence trend, and (3) historical information is isolated. Building on these insights, we propose Anchor-based History-stable Decoding (AHD), a training-free, plug-and-play dynamic decoding strategy. Specifically, AHD monitors the stability trend of tokens in real time through dynamic anchors. Once a token reaches stability, it initiates early cross-block decoding to enhance efficiency and performance. Extensive experiments across language, vision-language, and audio-language domains demonstrate that AHD simultaneously improves both performance and inference efficiency. Notably, AHD effectively reverses the performance degradation typically observed in existing advanced decoding acceleration strategies. For instance, on the BBH benchmark, our approach reduces decoding steps by 80% while improving performance by 3.67%.
EvolSQL: Structure-Aware Evolution for Scalable Text-to-SQL Data Synthesis
Jan 08, 2026Training effective Text-to-SQL models remains challenging due to the scarcity of high-quality, diverse, and structurally complex datasets. Existing methods either rely on limited human-annotated corpora, or synthesize datasets directly by simply prompting LLMs without explicit control over SQL structures, often resulting in limited structural diversity and complexity. To address this, we introduce EvolSQL, a structure-aware data synthesis framework that evolves SQL queries from seed data into richer and more semantically diverse forms. EvolSQL starts with an exploratory Query-SQL expansion to broaden question diversity and improve schema coverage, and then applies an adaptive directional evolution strategy using six atomic transformation operators derived from the SQL Abstract Syntax Tree to progressively increase query complexity across relational, predicate, aggregation, and nesting dimensions. An execution-grounded SQL refinement module and schema-aware deduplication further ensure the creation of high-quality, structurally diverse mapping pairs. Experimental results show that a 7B model fine-tuned on our data outperforms one trained on the much larger SynSQL dataset using only 1/18 of the data.
AIR: Post-training Data Selection for Reasoning via Attention Head Influence
Dec 15, 2025LLMs achieve remarkable multi-step reasoning capabilities, yet effectively transferring these skills via post-training distillation remains challenging. Existing data selection methods, ranging from manual curation to heuristics based on length, entropy, or overall loss, fail to capture the causal importance of individual reasoning steps, limiting distillation efficiency. To address this, we propose Attention Influence for Reasoning (AIR), a principled, unsupervised and training-free framework that leverages mechanistic insights of the retrieval head to select high-value post-training data. AIR first identifies reasoning-critical attention heads of an off-the-shelf model, then constructs a weakened reference model with disabled head influence, and finally quantifies the resulting loss divergence as the Attention Influence Score. This score enables fine-grained assessment at both the step and sample levels, supporting step-level weighted fine-tuning and global sample selection. Experiments across multiple reasoning benchmarks show that AIR consistently improves reasoning accuracy, surpassing heuristic baselines and effectively isolating the most critical steps and samples. Our work establishes a mechanism-driven, data-efficient approach for reasoning distillation in LLMs.
PROPHET: An Inferable Future Forecasting Benchmark with Causal Intervened Likelihood Estimation
Apr 02, 2025Predicting future events stands as one of the ultimate aspirations of artificial intelligence. Recent advances in large language model (LLM)-based systems have shown remarkable potential in forecasting future events, thereby garnering significant interest in the research community. Currently, several benchmarks have been established to evaluate the forecasting capabilities by formalizing the event prediction as a retrieval-augmented generation (RAG) and reasoning task. In these benchmarks, each prediction question is answered with relevant retrieved news articles. However, because there is no consideration on whether the questions can be supported by valid or sufficient supporting rationales, some of the questions in these benchmarks may be inherently noninferable. To address this issue, we introduce a new benchmark, PROPHET, which comprises inferable forecasting questions paired with relevant news for retrieval. To ensure the inferability of the benchmark, we propose Causal Intervened Likelihood (CIL), a statistical measure that assesses inferability through causal inference. In constructing this benchmark, we first collected recent trend forecasting questions and then filtered the data using CIL, resulting in an inferable benchmark for event prediction. Through extensive experiments, we first demonstrate the validity of CIL and in-depth investigations into event prediction with the aid of CIL. Subsequently, we evaluate several representative prediction systems on PROPHET, drawing valuable insights for future directions.
LLMs are Also Effective Embedding Models: An In-depth Overview
Dec 17, 2024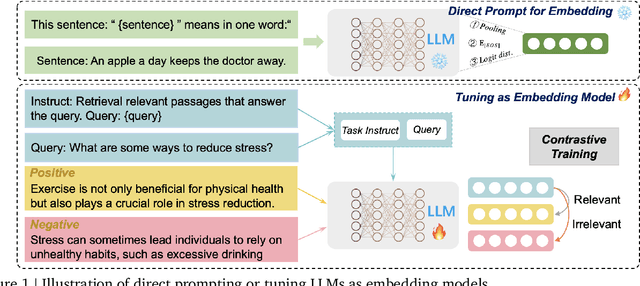

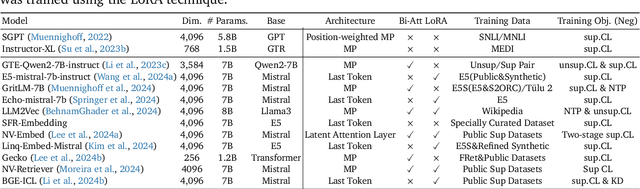
Large language models (LLMs) have revolutionized natural language processing by achieving state-of-the-art performance across various tasks. Recently, their effectiveness as embedding models has gained attention, marking a paradigm shift from traditional encoder-only models like ELMo and BERT to decoder-only, large-scale LLMs such as GPT, LLaMA, and Mistral. This survey provides an in-depth overview of this transition, beginning with foundational techniques before the LLM era, followed by LLM-based embedding models through two main strategies to derive embeddings from LLMs. 1) Direct prompting: We mainly discuss the prompt designs and the underlying rationale for deriving competitive embeddings. 2) Data-centric tuning: We cover extensive aspects that affect tuning an embedding model, including model architecture, training objectives, data constructions, etc. Upon the above, we also cover advanced methods, such as handling longer texts, and multilingual and cross-modal data. Furthermore, we discuss factors affecting choices of embedding models, such as performance/efficiency comparisons, dense vs sparse embeddings, pooling strategies, and scaling law. Lastly, the survey highlights the limitations and challenges in adapting LLMs for embeddings, including cross-task embedding quality, trade-offs between efficiency and accuracy, low-resource, long-context, data bias, robustness, etc. This survey serves as a valuable resource for researchers and practitioners by synthesizing current advancements, highlighting key challenges, and offering a comprehensive framework for future work aimed at enhancing the effectiveness and efficiency of LLMs as embedding models.
A Comprehensive Evaluation on Event Reasoning of Large Language Models
Apr 26, 2024



Event reasoning is a fundamental ability that underlies many applications. It requires event schema knowledge to perform global reasoning and needs to deal with the diversity of the inter-event relations and the reasoning paradigms. How well LLMs accomplish event reasoning on various relations and reasoning paradigms remains unknown. To mitigate this disparity, we comprehensively evaluate the abilities of event reasoning of LLMs. We introduce a novel benchmark EV2 for EValuation of EVent reasoning. EV2 consists of two levels of evaluation of schema and instance and is comprehensive in relations and reasoning paradigms. We conduct extensive experiments on EV2. We find that LLMs have abilities to accomplish event reasoning but their performances are far from satisfactory. We also notice the imbalance of event reasoning abilities in LLMs. Besides, LLMs have event schema knowledge, however, they're not aligned with humans on how to utilize the knowledge. Based on these findings, we introduce two methods to guide the LLMs to utilize the event schema knowledge. Both methods achieve improvements.
MEEL: Multi-Modal Event Evolution Learning
Apr 16, 2024



Multi-modal Event Reasoning (MMER) endeavors to endow machines with the ability to comprehend intricate event relations across diverse data modalities. MMER is fundamental and underlies a wide broad of applications. Despite extensive instruction fine-tuning, current multi-modal large language models still fall short in such ability. The disparity stems from that existing models are insufficient to capture underlying principles governing event evolution in various scenarios. In this paper, we introduce Multi-Modal Event Evolution Learning (MEEL) to enable the model to grasp the event evolution mechanism, yielding advanced MMER ability. Specifically, we commence with the design of event diversification to gather seed events from a rich spectrum of scenarios. Subsequently, we employ ChatGPT to generate evolving graphs for these seed events. We propose an instruction encapsulation process that formulates the evolving graphs into instruction-tuning data, aligning the comprehension of event reasoning to humans. Finally, we observe that models trained in this way are still struggling to fully comprehend event evolution. In such a case, we propose the guiding discrimination strategy, in which models are trained to discriminate the improper evolution direction. We collect and curate a benchmark M-EV2 for MMER. Extensive experiments on M-EV2 validate the effectiveness of our approach, showcasing competitive performance in open-source multi-modal LLMs.
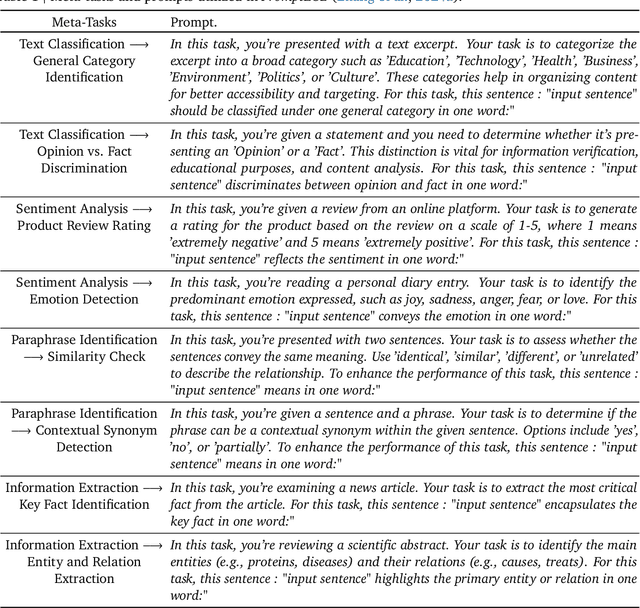
Meta-Task Prompting Elicits Embedding from Large Language Models
Feb 28, 2024In this work, we introduce a new unsupervised embedding method, Meta-Task Prompting with Explicit One-Word Limitation (MetaEOL), for generating high-quality sentence embeddings from Large Language Models (LLMs) without the need for model fine-tuning or task-specific engineering. Leveraging meta-task prompting, MetaEOL guides LLMs to produce embeddings through a series of carefully designed prompts that address multiple representational aspects. Our comprehensive experiments demonstrate that embeddings averaged from various meta-tasks yield competitive performance on Semantic Textual Similarity (STS) benchmarks and excel in downstream tasks, surpassing contrastive-trained models. Our findings suggest a new scaling law for embedding generation, offering a versatile, resource-efficient approach for embedding extraction across diverse sentence-centric scenarios.