 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024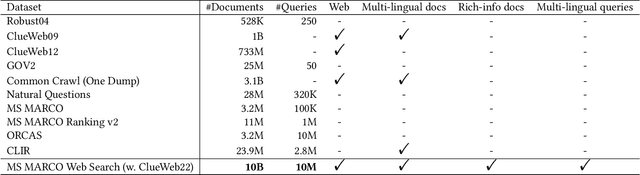
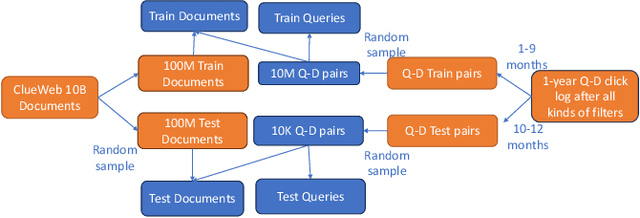
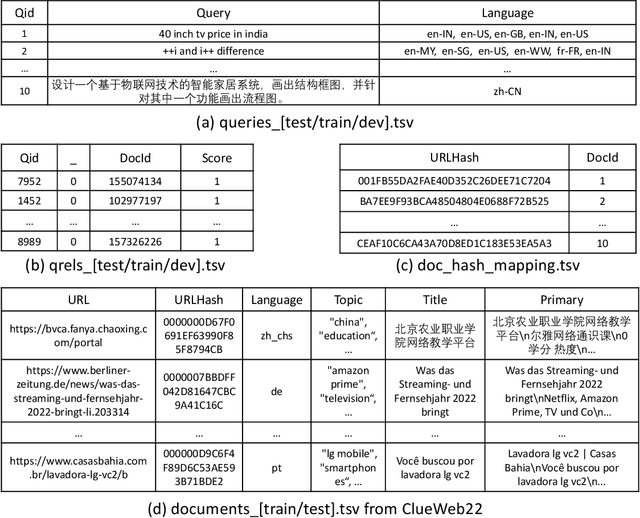
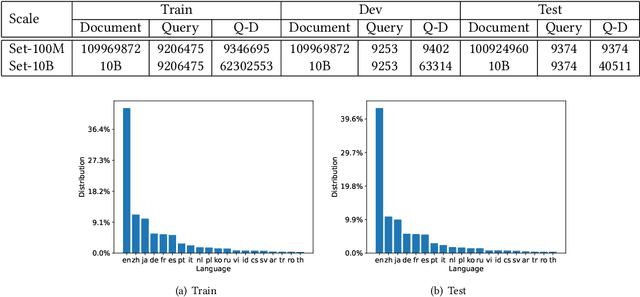
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
Good Questions Help Zero-Shot Image Reasoning
Dec 04, 2023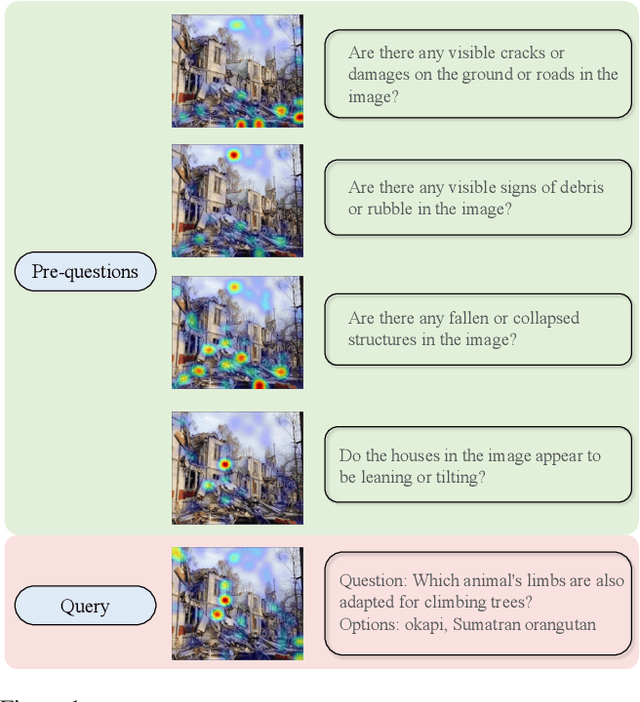
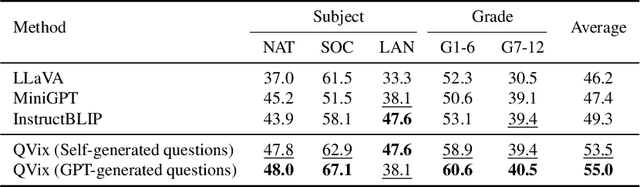
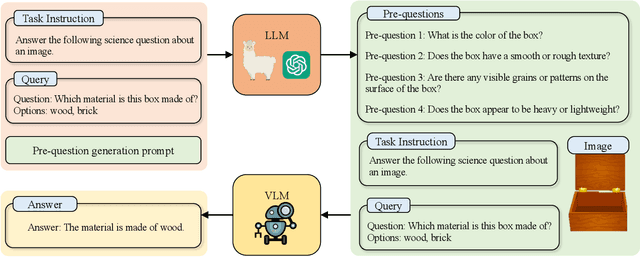
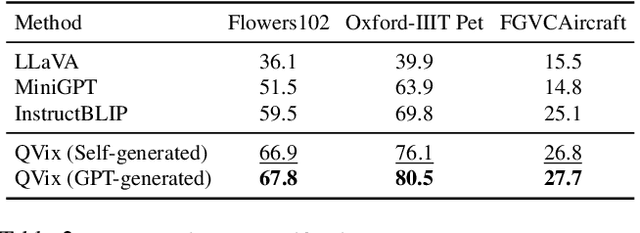
Aligning the recent large language models (LLMs) with computer vision models leads to large vision-language models (LVLMs), which have paved the way for zero-shot image reasoning tasks. However, LVLMs are usually trained on short high-level captions only referring to sparse focus regions in images. Such a ``tunnel vision'' limits LVLMs to exploring other relevant contexts in complex scenes. To address this challenge, we introduce Question-Driven Visual Exploration (QVix), a novel prompting strategy that enhances the exploratory capabilities of LVLMs in zero-shot reasoning tasks. QVix leverages LLMs' strong language prior to generate input-exploratory questions with more details than the original query, guiding LVLMs to explore visual content more comprehensively and uncover subtle or peripheral details. QVix enables a wider exploration of visual scenes, improving the LVLMs' reasoning accuracy and depth in tasks such as visual question answering and visual entailment. Our evaluations on various challenging zero-shot vision-language benchmarks, including ScienceQA and fine-grained visual classification, demonstrate that QVix significantly outperforms existing methods, highlighting its effectiveness in bridging the gap between complex visual data and LVLMs' exploratory abilities.
Thread of Thought Unraveling Chaotic Contexts
Nov 15, 2023



Large Language Models (LLMs) have ushered in a transformative era in the field of natural language processing, excelling in tasks related to text comprehension and generation. Nevertheless, they encounter difficulties when confronted with chaotic contexts (e.g., distractors rather than long irrelevant context), leading to the inadvertent omission of certain details within the chaotic context. In response to these challenges, we introduce the "Thread of Thought" (ThoT) strategy, which draws inspiration from human cognitive processes. ThoT systematically segments and analyzes extended contexts while adeptly selecting pertinent information. This strategy serves as a versatile "plug-and-play" module, seamlessly integrating with various LLMs and prompting techniques. In the experiments, we utilize the PopQA and EntityQ datasets, as well as a Multi-Turn Conversation Response dataset (MTCR) we collected, to illustrate that ThoT significantly improves reasoning performance compared to other prompting techniques.
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
Aug 18, 2023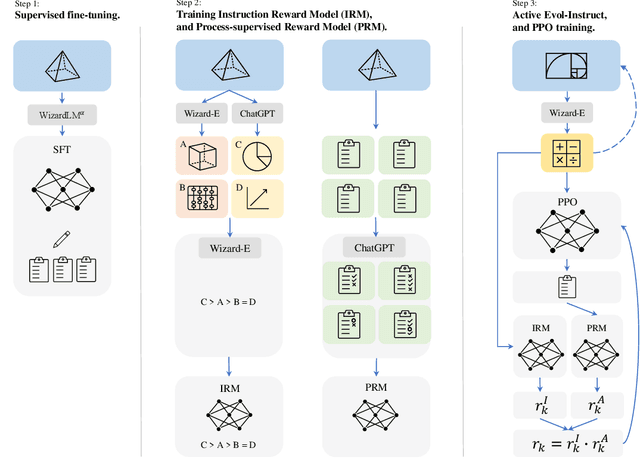
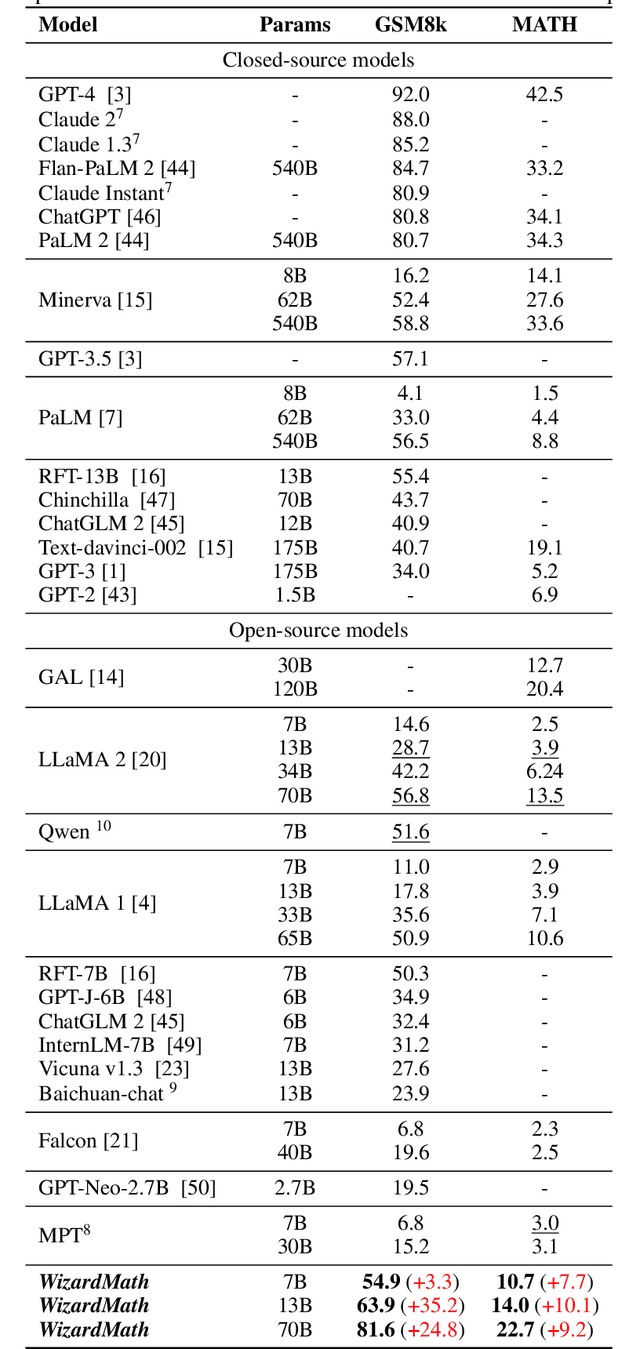
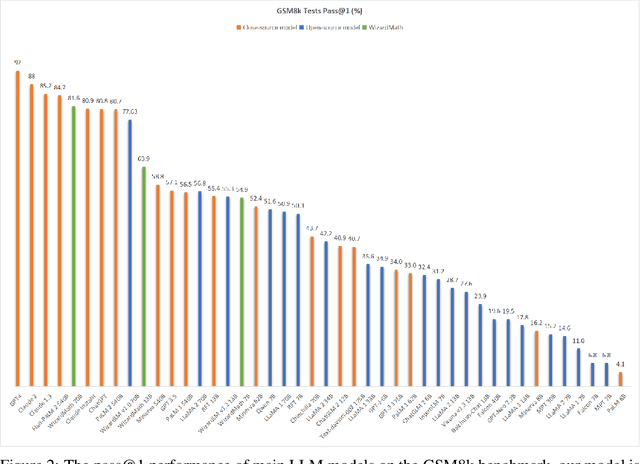

Large language models (LLMs), such as GPT-4, have shown remarkable performance in natural language processing (NLP) tasks, including challenging mathematical reasoning. However, most existing open-source models are only pre-trained on large-scale internet data and without math-related optimization. In this paper, we present WizardMath, which enhances the mathematical reasoning abilities of Llama-2, by applying our proposed Reinforcement Learning from Evol-Instruct Feedback (RLEIF) method to the domain of math. Through extensive experiments on two mathematical reasoning benchmarks, namely GSM8k and MATH, we reveal the extraordinary capabilities of our model. WizardMath surpasses all other open-source LLMs by a substantial margin. Furthermore, our model even outperforms ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, simultaneously surpasses Text-davinci-002, PaLM-1 and GPT-3 on MATH. More details and model weights are public at https://github.com/nlpxucan/WizardLM and https://huggingface.co/WizardLM.
Investigating the Learning Behaviour of In-context Learning: A Comparison with Supervised Learning
Aug 01, 2023Large language models (LLMs) have shown remarkable capacity for in-context learning (ICL), where learning a new task from just a few training examples is done without being explicitly pre-trained. However, despite the success of LLMs, there has been little understanding of how ICL learns the knowledge from the given prompts. In this paper, to make progress toward understanding the learning behaviour of ICL, we train the same LLMs with the same demonstration examples via ICL and supervised learning (SL), respectively, and investigate their performance under label perturbations (i.e., noisy labels and label imbalance) on a range of classification tasks. First, via extensive experiments, we find that gold labels have significant impacts on the downstream in-context performance, especially for large language models; however, imbalanced labels matter little to ICL across all model sizes. Second, when comparing with SL, we show empirically that ICL is less sensitive to label perturbations than SL, and ICL gradually attains comparable performance to SL as the model size increases.
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
Jun 14, 2023Code Large Language Models (Code LLMs), such as StarCoder, have demonstrated exceptional performance in code-related tasks. However, most existing models are solely pre-trained on extensive raw code data without instruction fine-tuning. In this paper, we introduce WizardCoder, which empowers Code LLMs with complex instruction fine-tuning, by adapting the Evol-Instruct method to the domain of code. Through comprehensive experiments on four prominent code generation benchmarks, namely HumanEval, HumanEval+, MBPP, and DS-1000, we unveil the exceptional capabilities of our model. It surpasses all other open-source Code LLMs by a substantial margin. Moreover, our model even outperforms the largest closed LLMs, Anthropic's Claude and Google's Bard, on HumanEval and HumanEval+. Our code, model weights, and data are public at https://github.com/nlpxucan/WizardLM
Knowledge Refinement via Interaction Between Search Engines and Large Language Models
May 21, 2023



Information retrieval (IR) plays a crucial role in locating relevant resources from vast amounts of data, and its applications have evolved from traditional knowledge bases to modern search engines (SEs). The emergence of large language models (LLMs) has further revolutionized the IR field by enabling users to interact with search systems in natural language. In this paper, we explore the advantages and disadvantages of LLMs and SEs, highlighting their respective strengths in understanding user-issued queries and retrieving up-to-date information. To leverage the benefits of both paradigms while circumventing their limitations, we propose InteR, a novel framework that facilitates knowledge refinement through interaction between SEs and LLMs. InteR allows SEs to expand knowledge in queries using LLM-generated knowledge collections and enables LLMs to enhance prompt formulation using SE-retrieved documents. This iterative refinement process augments the inputs of SEs and LLMs, leading to more accurate retrieval. Experiments on large-scale retrieval benchmarks involving web search and low-resource retrieval tasks demonstrate that InteR achieves overall superior zero-shot retrieval performance compared to state-of-the-art methods, even those using relevance judgment. Source code is available at https://github.com/Cyril-JZ/InteR
Augmented Large Language Models with Parametric Knowledge Guiding
May 18, 2023Large Language Models (LLMs) have significantly advanced natural language processing (NLP) with their impressive language understanding and generation capabilities. However, their performance may be suboptimal for domain-specific tasks that require specialized knowledge due to limited exposure to the related data. Additionally, the lack of transparency of most state-of-the-art (SOTA) LLMs, which can only be accessed via APIs, impedes further fine-tuning with domain custom data. Moreover, providing private data to the LLMs' owner leads to data privacy problems. To address these challenges, we propose the novel Parametric Knowledge Guiding (PKG) framework, which equips LLMs with a knowledge-guiding module to access relevant knowledge without altering the LLMs' parameters. Our PKG is based on open-source "white-box" language models, allowing offline memory of any knowledge that LLMs require. We demonstrate that our PKG framework can enhance the performance of "black-box" LLMs on a range of domain knowledge-intensive tasks that require factual (+7.9%), tabular (+11.9%), medical (+3.0%), and multimodal (+8.1%) knowledge.
Large Language Models are Strong Zero-Shot Retriever
Apr 27, 2023

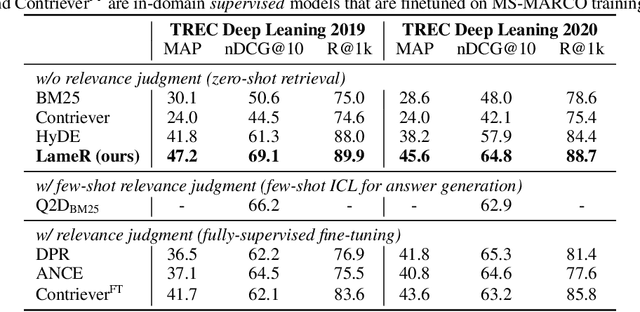
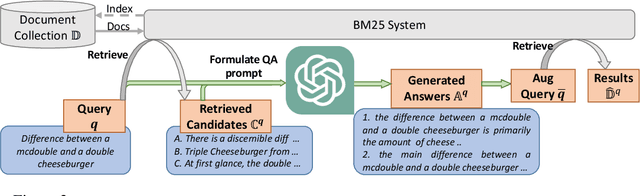
In this work, we propose a simple method that applies a large language model (LLM) to large-scale retrieval in zero-shot scenarios. Our method, Language language model as Retriever (LameR) is built upon no other neural models but an LLM, while breaking up brute-force combinations of retrievers with LLMs and lifting the performance of zero-shot retrieval to be very competitive on benchmark datasets. Essentially, we propose to augment a query with its potential answers by prompting LLMs with a composition of the query and the query's in-domain candidates. The candidates, regardless of correct or wrong, are obtained by a vanilla retrieval procedure on the target collection. Such candidates, as a part of prompts, are likely to help LLM generate more precise answers by pattern imitation or candidate summarization. Even if all the candidates are wrong, the prompts at least make LLM aware of in-collection patterns and genres. Moreover, due to the low performance of a self-supervised retriever, the LLM-based query augmentation becomes less effective as the retriever bottlenecks the whole pipeline. So, we propose to leverage a non-parametric lexicon-based method (e.g., BM25) as the retrieval module to capture query-document overlap in a literal fashion. As such, LameR makes the retrieval procedure transparent to the LLM, so it circumvents the performance bottleneck.
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Apr 24, 2023



Training large language models (LLM) with open-domain instruction following data brings colossal success. However, manually creating such instruction data is very time-consuming and labor-intensive. Moreover, humans may struggle to produce high-complexity instructions. In this paper, we show an avenue for creating large amounts of instruction data with varying levels of complexity using LLM instead of humans. Starting with an initial set of instructions, we use our proposed Evol-Instruct to rewrite them step by step into more complex instructions. Then, we mix all generated instruction data to fine-tune LLaMA. We call the resulting model WizardLM. Human evaluations on a complexity-balanced test bed show that instructions from Evol-Instruct are superior to human-created ones. By analyzing the human evaluation results of the high complexity part, we demonstrate that outputs from our WizardLM model are preferred to outputs from OpenAI ChatGPT. Even though WizardLM still lags behind ChatGPT in some aspects, our findings suggest that fine-tuning with AI-evolved instructions is a promising direction for enhancing large language models. Our codes and generated data are public at https://github.com/nlpxucan/WizardLM