 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents
Jan 26, 2026Deep research agents have shown remarkable potential in handling long-horizon tasks. However, state-of-the-art performance typically relies on online reinforcement learning (RL), which is financially expensive due to extensive API calls. While offline training offers a more efficient alternative, its progress is hindered by the scarcity of high-quality research trajectories. In this paper, we demonstrate that expensive online reinforcement learning is not all you need to build powerful research agents. To bridge this gap, we introduce a fully open-source suite designed for effective offline training. Our core contributions include DeepForge, a ready-to-use task synthesis framework that generates large-scale research queries without heavy preprocessing; and a curated collection of 66k QA pairs, 33k SFT trajectories, and 21k DPO pairs. Leveraging these resources, we train OffSeeker (8B), a model developed entirely offline. Extensive evaluations across six benchmarks show that OffSeeker not only leads among similar-sized agents but also remains competitive with 30B-parameter systems trained via heavy online RL.
What Drives Length of Stay After Elective Spine Surgery? Insights from a Decade of Predictive Modeling
Jan 24, 2026Objective: Predicting length of stay after elective spine surgery is essential for optimizing patient outcomes and hospital resource use. This systematic review synthesizes computational methods used to predict length of stay in this patient population, highlighting model performance and key predictors. Methods: Following PRISMA guidelines, we systematically searched PubMed, Google Scholar, and ACM Digital Library for studies published between December 1st, 2015, and December 1st, 2024. Eligible studies applied statistical or machine learning models to predict length of stay for elective spine surgery patients. Three reviewers independently screened studies and extracted data. Results: Out of 1,263 screened studies, 29 studies met inclusion criteria. Length of stay was predicted as a continuous, binary, or percentile-based outcome. Models included logistic regression, random forest, boosting algorithms, and neural networks. Machine learning models consistently outperformed traditional statistical models, with AUCs ranging from 0.94 to 0.99. K-Nearest Neighbors and Naive Bayes achieved top performance in some studies. Common predictors included age, comorbidities (notably hypertension and diabetes), BMI, type and duration of surgery, and number of spinal levels. However, external validation and reporting practices varied widely across studies. Discussion: There is growing interest in artificial intelligence and machine learning in length of stay prediction, but lack of standardization and external validation limits clinical utility. Future studies should prioritize standardized outcome definitions and transparent reporting needed to advance real-world deployment. Conclusion: Machine learning models offer strong potential for length of stay prediction after elective spine surgery, highlighting their potential for improving discharge planning and hospital resource management.
ReWeaver: Towards Simulation-Ready and Topology-Accurate Garment Reconstruction
Jan 23, 2026High-quality 3D garment reconstruction plays a crucial role in mitigating the sim-to-real gap in applications such as digital avatars, virtual try-on and robotic manipulation. However, existing garment reconstruction methods typically rely on unstructured representations, such as 3D Gaussian Splats, struggling to provide accurate reconstructions of garment topology and sewing structures. As a result, the reconstructed outputs are often unsuitable for high-fidelity physical simulation. We propose ReWeaver, a novel framework for topology-accurate 3D garment and sewing pattern reconstruction from sparse multi-view RGB images. Given as few as four input views, ReWeaver predicts seams and panels as well as their connectivities in both the 2D UV space and the 3D space. The predicted seams and panels align precisely with the multi-view images, yielding structured 2D--3D garment representations suitable for 3D perception, high-fidelity physical simulation, and robotic manipulation. To enable effective training, we construct a large-scale dataset GCD-TS, comprising multi-view RGB images, 3D garment geometries, textured human body meshes and annotated sewing patterns. The dataset contains over 100,000 synthetic samples covering a wide range of complex geometries and topologies. Extensive experiments show that ReWeaver consistently outperforms existing methods in terms of topology accuracy, geometry alignment and seam-panel consistency.
ParaMaP: Parallel Mapping and Collision-free Motion Planning for Reactive Robot Manipulation
Dec 27, 2025Real-time and collision-free motion planning remains challenging for robotic manipulation in unknown environments due to continuous perception updates and the need for frequent online replanning. To address these challenges, we propose a parallel mapping and motion planning framework that tightly integrates Euclidean Distance Transform (EDT)-based environment representation with a sampling-based model predictive control (SMPC) planner. On the mapping side, a dense distance-field-based representation is constructed using a GPU-based EDT and augmented with a robot-masked update mechanism to prevent false self-collision detections during online perception. On the planning side, motion generation is formulated as a stochastic optimization problem with a unified objective function and efficiently solved by evaluating large batches of candidate rollouts in parallel within a SMPC framework, in which a geometrically consistent pose tracking metric defined on SE(3) is incorporated to ensure fast and accurate convergence to the target pose. The entire mapping and planning pipeline is implemented on the GPU to support high-frequency replanning. The effectiveness of the proposed framework is validated through extensive simulations and real-world experiments on a 7-DoF robotic manipulator. More details are available at: https://zxw610.github.io/ParaMaP.
AgentMath: Empowering Mathematical Reasoning for Large Language Models via Tool-Augmented Agent
Dec 23, 2025Large Reasoning Models (LRMs) like o3 and DeepSeek-R1 have achieved remarkable progress in natural language reasoning with long chain-of-thought. However, they remain computationally inefficient and struggle with accuracy when solving problems requiring complex mathematical operations. In this work, we present AgentMath, an agent framework that seamlessly integrates language models' reasoning capabilities with code interpreters' computational precision to efficiently tackle complex mathematical problems. Our approach introduces three key innovations: (1) An automated method that converts natural language chain-of-thought into structured tool-augmented trajectories, generating high-quality supervised fine-tuning (SFT) data to alleviate data scarcity; (2) A novel agentic reinforcement learning (RL) paradigm that dynamically interleaves natural language generation with real-time code execution. This enables models to autonomously learn optimal tool-use strategies through multi-round interactive feedback, while fostering emergent capabilities in code refinement and error correction; (3) An efficient training system incorporating innovative techniques, including request-level asynchronous rollout scheduling, agentic partial rollout, and prefix-aware weighted load balancing, achieving 4-5x speedup and making efficient RL training feasible on ultra-long sequences with scenarios with massive tool calls.Extensive evaluations show that AgentMath achieves state-of-the-art performance on challenging mathematical competition benchmarks including AIME24, AIME25, and HMMT25. Specifically, AgentMath-30B-A3B attains 90.6%, 86.4%, and 73.8% accuracy respectively, achieving advanced capabilities.These results validate the effectiveness of our approach and pave the way for building more sophisticated and scalable mathematical reasoning agents.
Understanding Stigmatizing Language Lexicons: A Comparative Analysis in Clinical Contexts
Sep 09, 2025Stigmatizing language results in healthcare inequities, yet there is no universally accepted or standardized lexicon defining which words, terms, or phrases constitute stigmatizing language in healthcare. We conducted a systematic search of the literature to identify existing stigmatizing language lexicons and then analyzed them comparatively to examine: 1) similarities and discrepancies between these lexicons, and 2) the distribution of positive, negative, or neutral terms based on an established sentiment dataset. Our search identified four lexicons. The analysis results revealed moderate semantic similarity among them, and that most stigmatizing terms are related to judgmental expressions by clinicians to describe perceived negative behaviors. Sentiment analysis showed a predominant proportion of negatively classified terms, though variations exist across lexicons. Our findings underscore the need for a standardized lexicon and highlight challenges in defining stigmatizing language in clinical texts.
InverTwin: Solving Inverse Problems via Differentiable Radio Frequency Digital Twin
Aug 19, 2025Digital twins (DTs), virtual simulated replicas of physical scenes, are transforming various industries. However, their potential in radio frequency (RF) sensing applications has been limited by the unidirectional nature of conventional RF simulators. In this paper, we present InverTwin, an optimization-driven framework that creates RF digital twins by enabling bidirectional interaction between virtual and physical realms. InverTwin overcomes the fundamental differentiability challenges of RF optimization problems through novel design components, including path-space differentiation to address discontinuity in complex simulation functions, and a radar surrogate model to mitigate local non-convexity caused by RF signal periodicity. These techniques enable smooth gradient propagation and robust optimization of the DT model. Our implementation and experiments demonstrate InverTwin's versatility and effectiveness in augmenting both data-driven and model-driven RF sensing systems for DT reconstruction.
E3-Rewrite: Learning to Rewrite SQL for Executability, Equivalence,and Efficiency
Aug 12, 2025SQL query rewriting aims to reformulate a query into a more efficient form while preserving equivalence. Most existing methods rely on predefined rewrite rules. However, such rule-based approaches face fundamental limitations: (1) fixed rule sets generalize poorly to novel query patterns and struggle with complex queries; (2) a wide range of effective rewriting strategies cannot be fully captured by declarative rules. To overcome these issues, we propose using large language models (LLMs) to generate rewrites. LLMs can capture complex strategies, such as evaluation reordering and CTE rewriting. Despite this potential, directly applying LLMs often results in suboptimal or non-equivalent rewrites due to a lack of execution awareness and semantic grounding. To address these challenges, We present E3-Rewrite, an LLM-based SQL rewriting framework that produces executable, equivalent, and efficient queries. It integrates two core components: a context construction module and a reinforcement learning framework. First, the context module leverages execution plans and retrieved demonstrations to build bottleneck-aware prompts that guide inference-time rewriting. Second, we design a reward function targeting executability, equivalence, and efficiency, evaluated via syntax checks, equivalence verification, and cost estimation. Third, to ensure stable multi-objective learning, we adopt a staged curriculum that first emphasizes executability and equivalence, then gradually incorporates efficiency. Extensive experiments show that E3-Rewrite achieves up to a 25.6\% reduction in query execution time compared to state-of-the-art methods across multiple SQL benchmarks. Moreover, it delivers up to 24.4\% more successful rewrites, expanding coverage to complex queries that previous systems failed to handle.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Unified Generative Search and Recommendation
Apr 10, 2025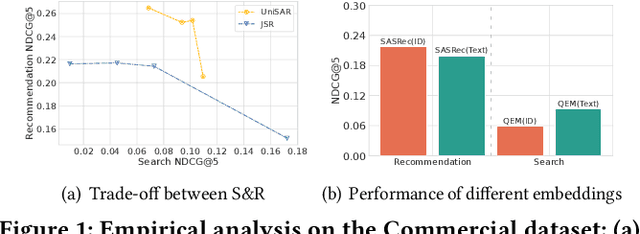
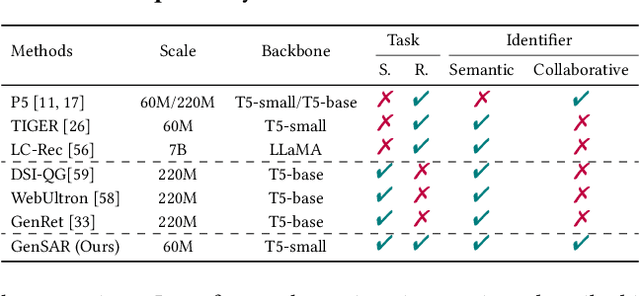
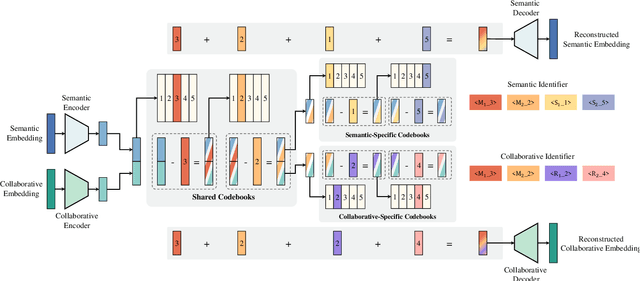

Modern commercial platforms typically offer both search and recommendation functionalities to serve diverse user needs, making joint modeling of these tasks an appealing direction. While prior work has shown that integrating search and recommendation can be mutually beneficial, it also reveals a performance trade-off: enhancements in one task often come at the expense of the other. This challenge arises from their distinct information requirements: search emphasizes semantic relevance between queries and items, whereas recommendation depends more on collaborative signals among users and items. Effectively addressing this trade-off requires tackling two key problems: (1) integrating both semantic and collaborative signals into item representations, and (2) guiding the model to distinguish and adapt to the unique demands of search and recommendation. The emergence of generative retrieval with Large Language Models (LLMs) presents new possibilities. This paradigm encodes items as identifiers and frames both search and recommendation as sequential generation tasks, offering the flexibility to leverage multiple identifiers and task-specific prompts. In light of this, we introduce GenSAR, a unified generative framework for balanced search and recommendation. Our approach designs dual-purpose identifiers and tailored training strategies to incorporate complementary signals and align with task-specific objectives. Experiments on both public and commercial datasets demonstrate that GenSAR effectively reduces the trade-off and achieves state-of-the-art performance on both tasks.