 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Quality Criteria and Distance-Aware Score Modeling for Image Editing Assessment
Apr 14, 2026Recent advances in image editing have heightened the need for reliable Image Editing Quality Assessment (IEQA). Unlike traditional methods, IEQA requires complex reasoning over multimodal inputs and multi-dimensional assessments. Existing MLLM-based approaches often rely on human heuristic prompting, leading to two key limitations: rigid metric prompting and distance-agnostic score modeling. These issues hinder alignment with implicit human criteria and fail to capture the continuous structure of score spaces. To address this, we propose Define-and-Score Image Editing Quality Assessment (DS-IEQA), a unified framework that jointly learns evaluation criteria and score representations. Specifically, we introduce Feedback-Driven Metric Prompt Optimization (FDMPO) to automatically refine metric definitions via probabilistic feedback. Furthermore, we propose Token-Decoupled Distance Regression Loss (TDRL), which decouples numerical tokens from language modeling to explicitly model score continuity through expected distance minimization. Extensive experiments show our method's superior performance; it ranks 4th in the 2026 NTIRE X-AIGC Quality Assessment Track 2 without any additional training data.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
SwiftGS: Episodic Priors for Immediate Satellite Surface Recovery
Mar 19, 2026Rapid, large-scale 3D reconstruction from multi-date satellite imagery is vital for environmental monitoring, urban planning, and disaster response, yet remains difficult due to illumination changes, sensor heterogeneity, and the cost of per-scene optimization. We introduce SwiftGS, a meta-learned system that reconstructs 3D surfaces in a single forward pass by predicting geometry-radiation-decoupled Gaussian primitives together with a lightweight SDF, replacing expensive per-scene fitting with episodic training that captures transferable priors. The model couples a differentiable physics graph for projection, illumination, and sensor response with spatial gating that blends sparse Gaussian detail and global SDF structure, and incorporates semantic-geometric fusion, conditional lightweight task heads, and multi-view supervision from a frozen geometric teacher under an uncertainty-aware multi-task loss. At inference, SwiftGS operates zero-shot with optional compact calibration and achieves accurate DSM reconstruction and view-consistent rendering at significantly reduced computational cost, with ablations highlighting the benefits of the hybrid representation, physics-aware rendering, and episodic meta-training.
SphUnc: Hyperspherical Uncertainty Decomposition and Causal Identification via Information Geometry
Mar 01, 2026Reliable decision-making in complex multi-agent systems requires calibrated predictions and interpretable uncertainty. We introduce SphUnc, a unified framework combining hyperspherical representation learning with structural causal modeling. The model maps features to unit hypersphere latents using von Mises-Fisher distributions, decomposing uncertainty into epistemic and aleatoric components through information-geometric fusion. A structural causal model on spherical latents enables directed influence identification and interventional reasoning via sample-based simulation. Empirical evaluations on social and affective benchmarks demonstrate improved accuracy, better calibration, and interpretable causal signals, establishing a geometric-causal foundation for uncertainty-aware reasoning in multi-agent settings with higher-order interactions.
DAV-GSWT: Diffusion-Active-View Sampling for Data-Efficient Gaussian Splatting Wang Tiles
Feb 17, 2026The emergence of 3D Gaussian Splatting has fundamentally redefined the capabilities of photorealistic neural rendering by enabling high-throughput synthesis of complex environments. While procedural methods like Wang Tiles have recently been integrated to facilitate the generation of expansive landscapes, these systems typically remain constrained by a reliance on densely sampled exemplar reconstructions. We present DAV-GSWT, a data-efficient framework that leverages diffusion priors and active view sampling to synthesize high-fidelity Gaussian Splatting Wang Tiles from minimal input observations. By integrating a hierarchical uncertainty quantification mechanism with generative diffusion models, our approach autonomously identifies the most informative viewpoints while hallucinating missing structural details to ensure seamless tile transitions. Experimental results indicate that our system significantly reduces the required data volume while maintaining the visual integrity and interactive performance necessary for large-scale virtual environments.
GaiaFlow: Semantic-Guided Diffusion Tuning for Carbon-Frugal Search
Feb 17, 2026As the burgeoning power requirements of sophisticated neural architectures escalate, the information retrieval community has recognized ecological sustainability as a pivotal priority that necessitates a fundamental paradigm shift in model design. While contemporary neural rankers have attained unprecedented accuracy, the substantial environmental externalities associated with their computational intensity often remain overlooked in large-scale deployments. We present GaiaFlow, an innovative framework engineered to facilitate carbon-frugal search by operationalizing semantic-guided diffusion tuning. Our methodology orchestrates the convergence of retrieval-guided Langevin dynamics and a hardware-independent performance modeling strategy to optimize the trade-off between search precision and environmental preservation. By incorporating adaptive early exit protocols and precision-aware quantized inference, the proposed architecture significantly mitigates operational carbon footprints while maintaining robust retrieval quality across heterogeneous computing infrastructures. Extensive experimental evaluations demonstrate that GaiaFlow achieves a superior equilibrium between effectiveness and energy efficiency, offering a scalable and sustainable pathway for next-generation neural search systems.
Chimera: Neuro-Symbolic Attention Primitives for Trustworthy Dataplane Intelligence
Feb 13, 2026Deploying expressive learning models directly on programmable dataplanes promises line-rate, low-latency traffic analysis but remains hindered by strict hardware constraints and the need for predictable, auditable behavior. Chimera introduces a principled framework that maps attention-oriented neural computations and symbolic constraints onto dataplane primitives, enabling trustworthy inference within the match-action pipeline. Chimera combines a kernelized, linearized attention approximation with a two-layer key-selection hierarchy and a cascade fusion mechanism that enforces hard symbolic guarantees while preserving neural expressivity. The design includes a hardware-aware mapping protocol and a two-timescale update scheme that together permit stable, line-rate operation under realistic dataplane budgets. The paper presents the Chimera architecture, a hardware mapping strategy, and empirical evidence showing that neuro-symbolic attention primitives can achieve high-fidelity inference within the resource envelope of commodity programmable switches.
Cott-ADNet: Lightweight Real-Time Cotton Boll and Flower Detection Under Field Conditions
Sep 15, 2025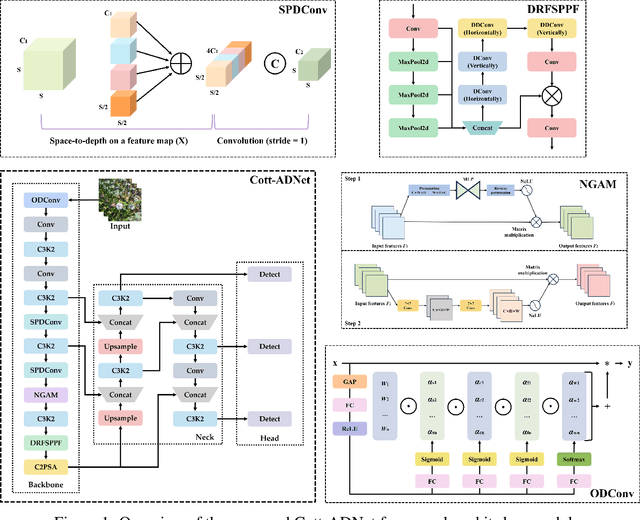
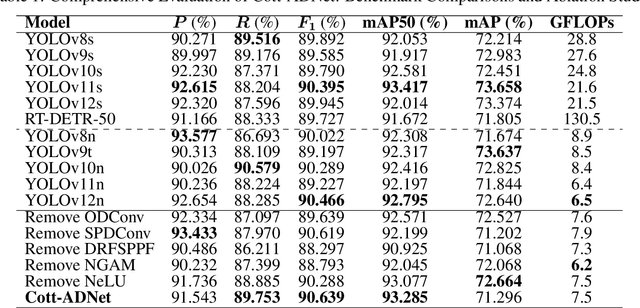

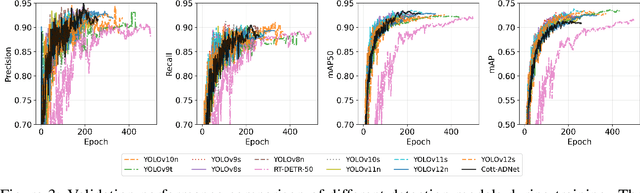
Cotton is one of the most important natural fiber crops worldwide, yet harvesting remains limited by labor-intensive manual picking, low efficiency, and yield losses from missing the optimal harvest window. Accurate recognition of cotton bolls and their maturity is therefore essential for automation, yield estimation, and breeding research. We propose Cott-ADNet, a lightweight real-time detector tailored to cotton boll and flower recognition under complex field conditions. Building on YOLOv11n, Cott-ADNet enhances spatial representation and robustness through improved convolutional designs, while introducing two new modules: a NeLU-enhanced Global Attention Mechanism to better capture weak and low-contrast features, and a Dilated Receptive Field SPPF to expand receptive fields for more effective multi-scale context modeling at low computational cost. We curate a labeled dataset of 4,966 images, and release an external validation set of 1,216 field images to support future research. Experiments show that Cott-ADNet achieves 91.5% Precision, 89.8% Recall, 93.3% mAP50, 71.3% mAP, and 90.6% F1-Score with only 7.5 GFLOPs, maintaining stable performance under multi-scale and rotational variations. These results demonstrate Cott-ADNet as an accurate and efficient solution for in-field deployment, and thus provide a reliable basis for automated cotton harvesting and high-throughput phenotypic analysis. Code and dataset is available at https://github.com/SweefongWong/Cott-ADNet.
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
Aug 27, 2025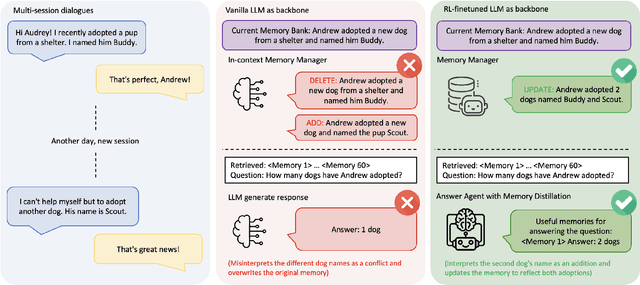
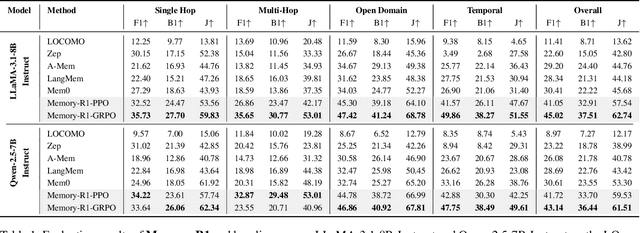
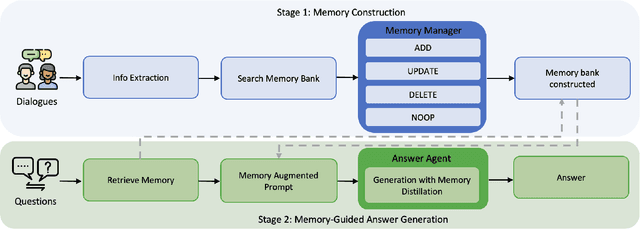

Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. Recent efforts to address this limitation often augment LLMs with an external memory bank, yet most existing pipelines are static and heuristic-driven, lacking any learned mechanism for deciding what to store, update, or retrieve. We present Memory-R1, a reinforcement learning (RL) framework that equips LLMs with the ability to actively manage and utilize external memory through two specialized agents: a Memory Manager that learns to perform structured memory operations {ADD, UPDATE, DELETE, NOOP}, and an Answer Agent that selects the most relevant entries and reasons over them to produce an answer. Both agents are fine-tuned with outcome-driven RL (PPO and GRPO), enabling adaptive memory management and use with minimal supervision. With as few as 152 question-answer pairs and a corresponding temporal memory bank for training, Memory-R1 outperforms the most competitive existing baseline and demonstrates strong generalization across diverse question types and LLM backbones. Beyond presenting an effective approach, this work provides insights into how RL can unlock more agentic, memory-aware behaviors in LLMs, pointing toward richer, more persistent reasoning systems.
Contrastive Prompt Clustering for Weakly Supervised Semantic Segmentation
Aug 23, 2025



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has gained attention for its cost-effectiveness. Most existing methods emphasize inter-class separation, often neglecting the shared semantics among related categories and lacking fine-grained discrimination. To address this, we propose Contrastive Prompt Clustering (CPC), a novel WSSS framework. CPC exploits Large Language Models (LLMs) to derive category clusters that encode intrinsic inter-class relationships, and further introduces a class-aware patch-level contrastive loss to enforce intra-class consistency and inter-class separation. This hierarchical design leverages clusters as coarse-grained semantic priors while preserving fine-grained boundaries, thereby reducing confusion among visually similar categories. Experiments on PASCAL VOC 2012 and MS COCO 2014 demonstrate that CPC surpasses existing state-of-the-art methods in WSSS.