 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthSeg-Agents: Multi-Agent Synthetic Data Generation for Zero-Shot Weakly Supervised Semantic Segmentation
Dec 17, 2025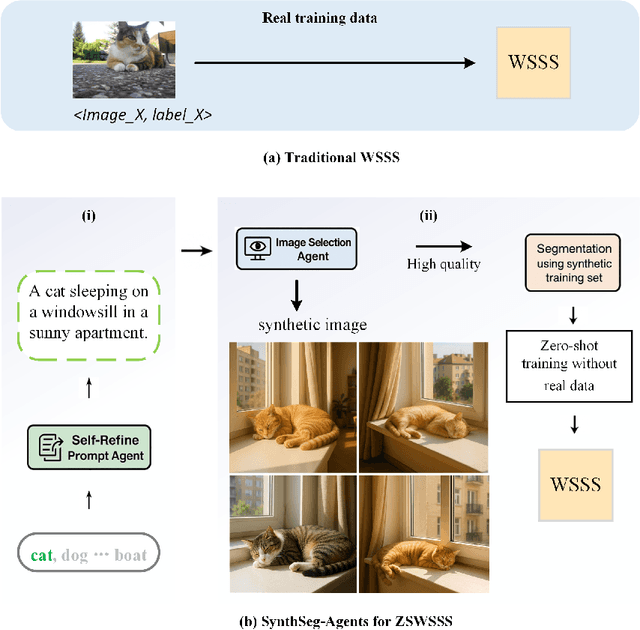
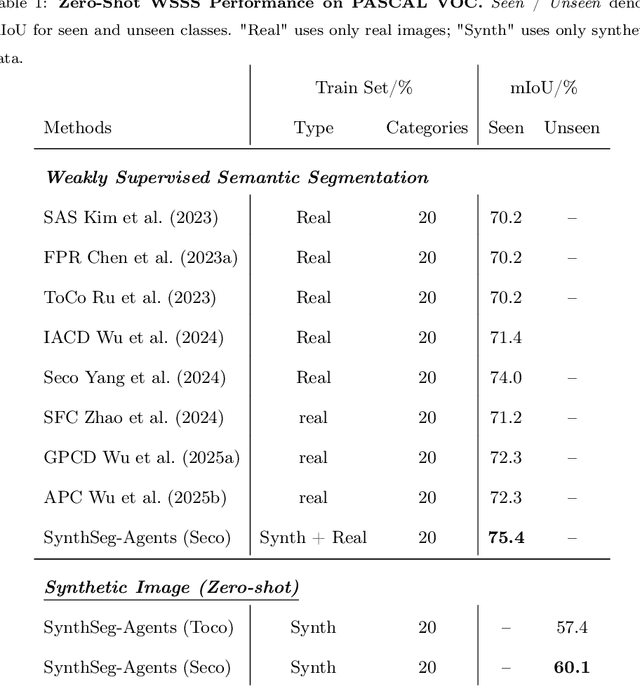
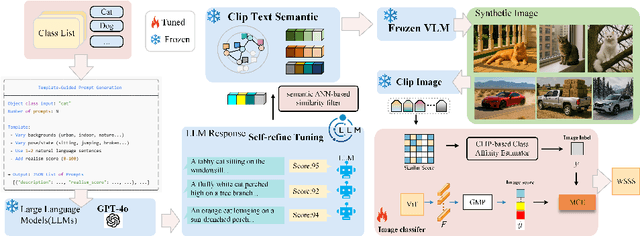
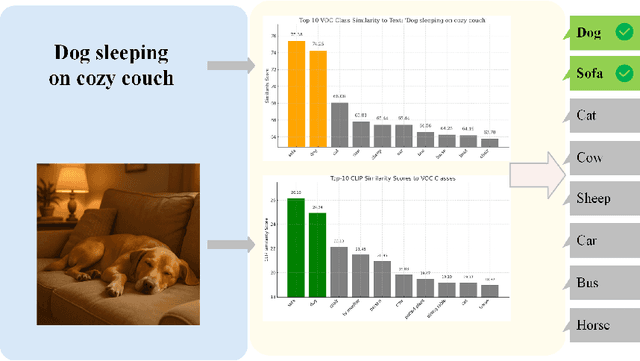
Weakly Supervised Semantic Segmentation (WSSS) with image level labels aims to produce pixel level predictions without requiring dense annotations. While recent approaches have leveraged generative models to augment existing data, they remain dependent on real world training samples. In this paper, we introduce a novel direction, Zero Shot Weakly Supervised Semantic Segmentation (ZSWSSS), and propose SynthSeg Agents, a multi agent framework driven by Large Language Models (LLMs) to generate synthetic training data entirely without real images. SynthSeg Agents comprises two key modules, a Self Refine Prompt Agent and an Image Generation Agent. The Self Refine Prompt Agent autonomously crafts diverse and semantically rich image prompts via iterative refinement, memory mechanisms, and prompt space exploration, guided by CLIP based similarity and nearest neighbor diversity filtering. These prompts are then passed to the Image Generation Agent, which leverages Vision Language Models (VLMs) to synthesize candidate images. A frozen CLIP scoring model is employed to select high quality samples, and a ViT based classifier is further trained to relabel the entire synthetic dataset with improved semantic precision. Our framework produces high quality training data without any real image supervision. Experiments on PASCAL VOC 2012 and COCO 2014 show that SynthSeg Agents achieves competitive performance without using real training images. This highlights the potential of LLM driven agents in enabling cost efficient and scalable semantic segmentation.
Contrastive Prompt Clustering for Weakly Supervised Semantic Segmentation
Aug 23, 2025



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has gained attention for its cost-effectiveness. Most existing methods emphasize inter-class separation, often neglecting the shared semantics among related categories and lacking fine-grained discrimination. To address this, we propose Contrastive Prompt Clustering (CPC), a novel WSSS framework. CPC exploits Large Language Models (LLMs) to derive category clusters that encode intrinsic inter-class relationships, and further introduces a class-aware patch-level contrastive loss to enforce intra-class consistency and inter-class separation. This hierarchical design leverages clusters as coarse-grained semantic priors while preserving fine-grained boundaries, thereby reducing confusion among visually similar categories. Experiments on PASCAL VOC 2012 and MS COCO 2014 demonstrate that CPC surpasses existing state-of-the-art methods in WSSS.
Hierarchical Attention Fusion of Visual and Textual Representations for Cross-Domain Sequential Recommendation
Apr 21, 2025Cross-Domain Sequential Recommendation (CDSR) predicts user behavior by leveraging historical interactions across multiple domains, focusing on modeling cross-domain preferences through intra- and inter-sequence item relationships. Inspired by human cognitive processes, we propose Hierarchical Attention Fusion of Visual and Textual Representations (HAF-VT), a novel approach integrating visual and textual data to enhance cognitive modeling. Using the frozen CLIP model, we generate image and text embeddings, enriching item representations with multimodal data. A hierarchical attention mechanism jointly learns single-domain and cross-domain preferences, mimicking human information integration. Evaluated on four e-commerce datasets, HAF-VT outperforms existing methods in capturing cross-domain user interests, bridging cognitive principles with computational models and highlighting the role of multimodal data in sequential decision-making.
Image Augmentation Agent for Weakly Supervised Semantic Segmentation
Dec 29, 2024Weakly-supervised semantic segmentation (WSSS) has achieved remarkable progress using only image-level labels. However, most existing WSSS methods focus on designing new network structures and loss functions to generate more accurate dense labels, overlooking the limitations imposed by fixed datasets, which can constrain performance improvements. We argue that more diverse trainable images provides WSSS richer information and help model understand more comprehensive semantic pattern. Therefore in this paper, we introduce a novel approach called Image Augmentation Agent (IAA) which shows that it is possible to enhance WSSS from data generation perspective. IAA mainly design an augmentation agent that leverages large language models (LLMs) and diffusion models to automatically generate additional images for WSSS. In practice, to address the instability in prompt generation by LLMs, we develop a prompt self-refinement mechanism. It allow LLMs to re-evaluate the rationality of generated prompts to produce more coherent prompts. Additionally, we insert an online filter into diffusion generation process to dynamically ensure the quality and balance of generated images. Experimental results show that our method significantly surpasses state-of-the-art WSSS approaches on the PASCAL VOC 2012 and MS COCO 2014 datasets.
APC: Adaptive Patch Contrast for Weakly Supervised Semantic Segmentation
Jul 15, 2024



Weakly Supervised Semantic Segmentation (WSSS) using only image-level labels has gained significant attention due to its cost-effectiveness. The typical framework involves using image-level labels as training data to generate pixel-level pseudo-labels with refinements. Recently, methods based on Vision Transformers (ViT) have demonstrated superior capabilities in generating reliable pseudo-labels, particularly in recognizing complete object regions, compared to CNN methods. However, current ViT-based approaches have some limitations in the use of patch embeddings, being prone to being dominated by certain abnormal patches, as well as many multi-stage methods being time-consuming and lengthy in training, thus lacking efficiency. Therefore, in this paper, we introduce a novel ViT-based WSSS method named \textit{Adaptive Patch Contrast} (APC) that significantly enhances patch embedding learning for improved segmentation effectiveness. APC utilizes an Adaptive-K Pooling (AKP) layer to address the limitations of previous max pooling selection methods. Additionally, we propose a Patch Contrastive Learning (PCL) to enhance patch embeddings, thereby further improving the final results. Furthermore, we improve upon the existing multi-stage training framework without CAM by transforming it into an end-to-end single-stage training approach, thereby enhancing training efficiency. The experimental results show that our approach is effective and efficient, outperforming other state-of-the-art WSSS methods on the PASCAL VOC 2012 and MS COCO 2014 dataset within a shorter training duration.