 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACDC: Adaptive Curriculum Planning with Dynamic Contrastive Control for Goal-Conditioned Reinforcement Learning in Robotic Manipulation
Mar 02, 2026Goal-conditioned reinforcement learning has shown considerable potential in robotic manipulation; however, existing approaches remain limited by their reliance on prioritizing collected experience, resulting in suboptimal performance across diverse tasks. Inspired by human learning behaviors, we propose a more comprehensive learning paradigm, ACDC, which integrates multidimensional Adaptive Curriculum (AC) Planning with Dynamic Contrastive (DC) Control to guide the agent along a well-designed learning trajectory. More specifically, at the planning level, the AC component schedules the learning curriculum by dynamically balancing diversity-driven exploration and quality-driven exploitation based on the agent's success rate and training progress. At the control level, the DC component implements the curriculum plan through norm-constrained contrastive learning, enabling magnitude-guided experience selection aligned with the current curriculum focus. Extensive experiments on challenging robotic manipulation tasks demonstrate that ACDC consistently outperforms the state-of-the-art baselines in both sample efficiency and final task success rate.
APC: Adaptive Patch Contrast for Weakly Supervised Semantic Segmentation
Jul 15, 2024



Weakly Supervised Semantic Segmentation (WSSS) using only image-level labels has gained significant attention due to its cost-effectiveness. The typical framework involves using image-level labels as training data to generate pixel-level pseudo-labels with refinements. Recently, methods based on Vision Transformers (ViT) have demonstrated superior capabilities in generating reliable pseudo-labels, particularly in recognizing complete object regions, compared to CNN methods. However, current ViT-based approaches have some limitations in the use of patch embeddings, being prone to being dominated by certain abnormal patches, as well as many multi-stage methods being time-consuming and lengthy in training, thus lacking efficiency. Therefore, in this paper, we introduce a novel ViT-based WSSS method named \textit{Adaptive Patch Contrast} (APC) that significantly enhances patch embedding learning for improved segmentation effectiveness. APC utilizes an Adaptive-K Pooling (AKP) layer to address the limitations of previous max pooling selection methods. Additionally, we propose a Patch Contrastive Learning (PCL) to enhance patch embeddings, thereby further improving the final results. Furthermore, we improve upon the existing multi-stage training framework without CAM by transforming it into an end-to-end single-stage training approach, thereby enhancing training efficiency. The experimental results show that our approach is effective and efficient, outperforming other state-of-the-art WSSS methods on the PASCAL VOC 2012 and MS COCO 2014 dataset within a shorter training duration.
Active Label Refinement for Robust Training of Imbalanced Medical Image Classification Tasks in the Presence of High Label Noise
Jul 08, 2024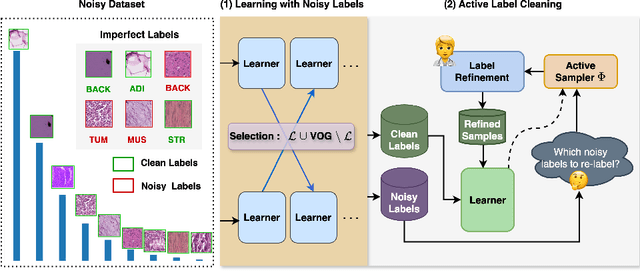

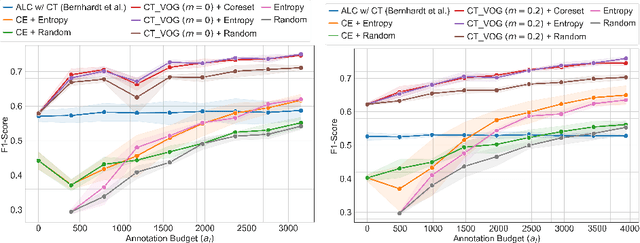
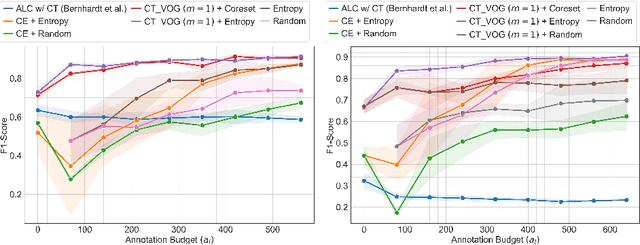
The robustness of supervised deep learning-based medical image classification is significantly undermined by label noise. Although several methods have been proposed to enhance classification performance in the presence of noisy labels, they face some challenges: 1) a struggle with class-imbalanced datasets, leading to the frequent overlooking of minority classes as noisy samples; 2) a singular focus on maximizing performance using noisy datasets, without incorporating experts-in-the-loop for actively cleaning the noisy labels. To mitigate these challenges, we propose a two-phase approach that combines Learning with Noisy Labels (LNL) and active learning. This approach not only improves the robustness of medical image classification in the presence of noisy labels, but also iteratively improves the quality of the dataset by relabeling the important incorrect labels, under a limited annotation budget. Furthermore, we introduce a novel Variance of Gradients approach in LNL phase, which complements the loss-based sample selection by also sampling under-represented samples. Using two imbalanced noisy medical classification datasets, we demonstrate that that our proposed technique is superior to its predecessors at handling class imbalance by not misidentifying clean samples from minority classes as mostly noisy samples.
Cross Domain Policy Transfer with Effect Cycle-Consistency
Mar 04, 2024
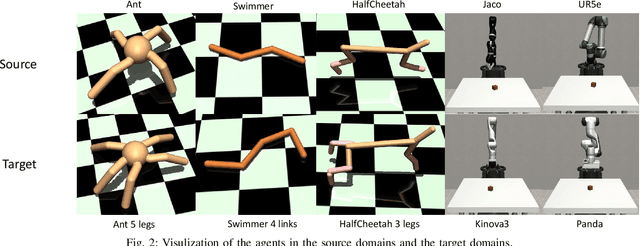
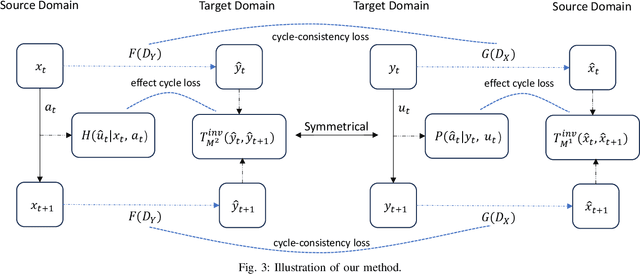
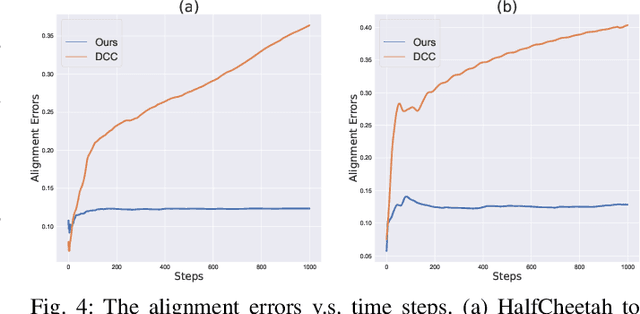
Training a robotic policy from scratch using deep reinforcement learning methods can be prohibitively expensive due to sample inefficiency. To address this challenge, transferring policies trained in the source domain to the target domain becomes an attractive paradigm. Previous research has typically focused on domains with similar state and action spaces but differing in other aspects. In this paper, our primary focus lies in domains with different state and action spaces, which has broader practical implications, i.e. transfer the policy from robot A to robot B. Unlike prior methods that rely on paired data, we propose a novel approach for learning the mapping functions between state and action spaces across domains using unpaired data. We propose effect cycle consistency, which aligns the effects of transitions across two domains through a symmetrical optimization structure for learning these mapping functions. Once the mapping functions are learned, we can seamlessly transfer the policy from the source domain to the target domain. Our approach has been tested on three locomotion tasks and two robotic manipulation tasks. The empirical results demonstrate that our method can reduce alignment errors significantly and achieve better performance compared to the state-of-the-art method.
Image Augmentation with Controlled Diffusion for Weakly-Supervised Semantic Segmentation
Oct 15, 2023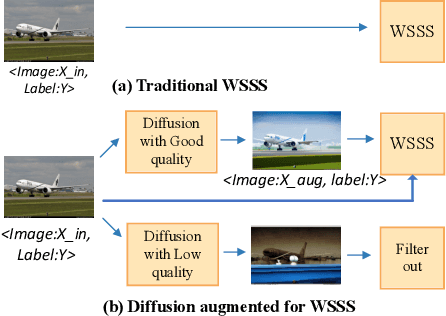
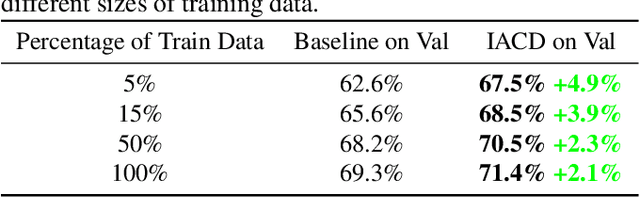
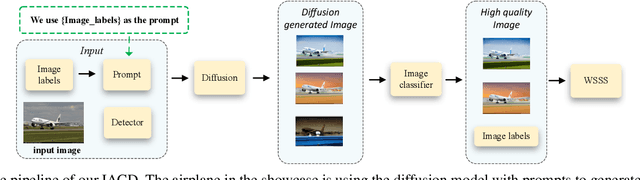

Weakly-supervised semantic segmentation (WSSS), which aims to train segmentation models solely using image-level labels, has achieved significant attention. Existing methods primarily focus on generating high-quality pseudo labels using available images and their image-level labels. However, the quality of pseudo labels degrades significantly when the size of available dataset is limited. Thus, in this paper, we tackle this problem from a different view by introducing a novel approach called Image Augmentation with Controlled Diffusion (IACD). This framework effectively augments existing labeled datasets by generating diverse images through controlled diffusion, where the available images and image-level labels are served as the controlling information. Moreover, we also propose a high-quality image selection strategy to mitigate the potential noise introduced by the randomness of diffusion models. In the experiments, our proposed IACD approach clearly surpasses existing state-of-the-art methods. This effect is more obvious when the amount of available data is small, demonstrating the effectiveness of our method.
Top-K Pooling with Patch Contrastive Learning for Weakly-Supervised Semantic Segmentation
Oct 15, 2023



Weakly Supervised Semantic Segmentation (WSSS) using only image-level labels has gained significant attention due to cost-effectiveness. Recently, Vision Transformer (ViT) based methods without class activation map (CAM) have shown greater capability in generating reliable pseudo labels than previous methods using CAM. However, the current ViT-based methods utilize max pooling to select the patch with the highest prediction score to map the patch-level classification to the image-level one, which may affect the quality of pseudo labels due to the inaccurate classification of the patches. In this paper, we introduce a novel ViT-based WSSS method named top-K pooling with patch contrastive learning (TKP-PCL), which employs a top-K pooling layer to alleviate the limitations of previous max pooling selection. A patch contrastive error (PCE) is also proposed to enhance the patch embeddings to further improve the final results. The experimental results show that our approach is very efficient and outperforms other state-of-the-art WSSS methods on the PASCAL VOC 2012 dataset.
Learning to Solve Tasks with Exploring Prior Behaviours
Jul 06, 2023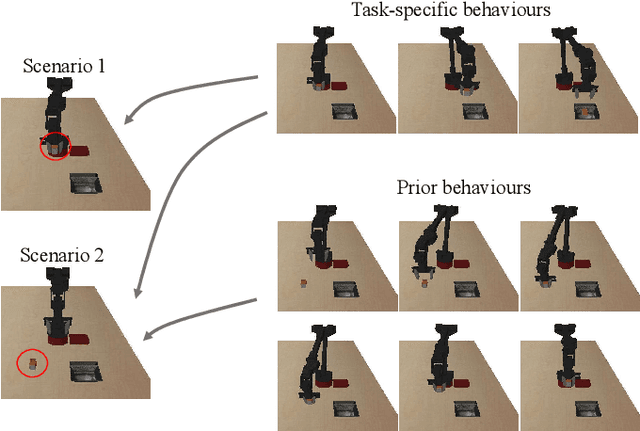
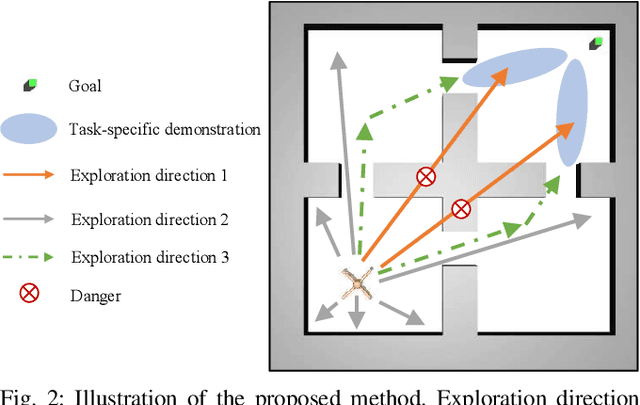
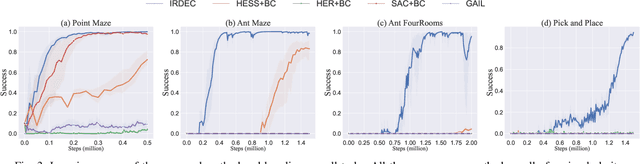
Demonstrations are widely used in Deep Reinforcement Learning (DRL) for facilitating solving tasks with sparse rewards. However, the tasks in real-world scenarios can often have varied initial conditions from the demonstration, which would require additional prior behaviours. For example, consider we are given the demonstration for the task of \emph{picking up an object from an open drawer}, but the drawer is closed in the training. Without acquiring the prior behaviours of opening the drawer, the robot is unlikely to solve the task. To address this, in this paper we propose an Intrinsic Rewards Driven Example-based Control \textbf{(IRDEC)}. Our method can endow agents with the ability to explore and acquire the required prior behaviours and then connect to the task-specific behaviours in the demonstration to solve sparse-reward tasks without requiring additional demonstration of the prior behaviours. The performance of our method outperforms other baselines on three navigation tasks and one robotic manipulation task with sparse rewards. Codes are available at https://github.com/Ricky-Zhu/IRDEC.
SJ-HD^2R: Selective Joint High Dynamic Range and Denoising Imaging for Dynamic Scenes
Jun 20, 2022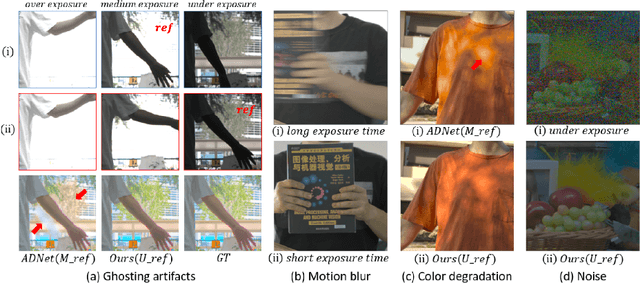
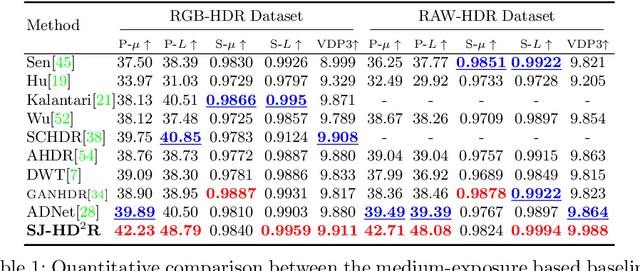
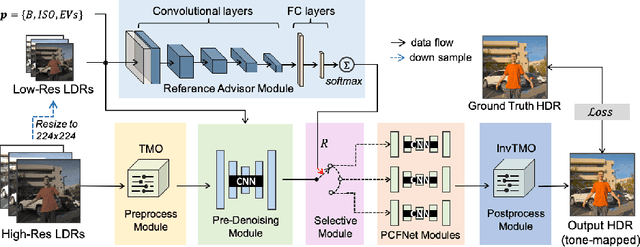
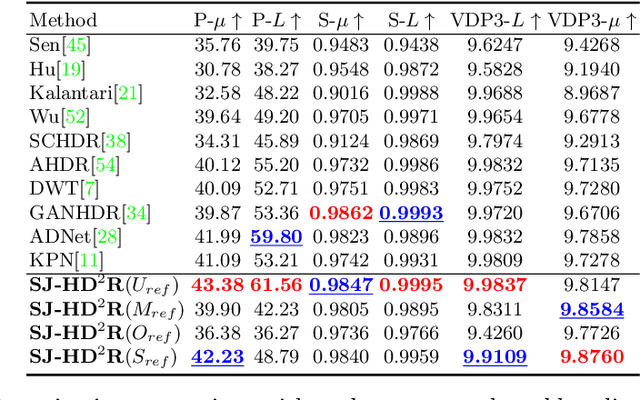
Ghosting artifacts, motion blur, and low fidelity in highlight are the main challenges in High Dynamic Range (HDR) imaging from multiple Low Dynamic Range (LDR) images. These issues come from using the medium-exposed image as the reference frame in previous methods. To deal with them, we propose to use the under-exposed image as the reference to avoid these issues. However, the heavy noise in dark regions of the under-exposed image becomes a new problem. Therefore, we propose a joint HDR and denoising pipeline, containing two sub-networks: (i) a pre-denoising network (PreDNNet) to adaptively denoise input LDRs by exploiting exposure priors; (ii) a pyramid cascading fusion network (PCFNet), introducing an attention mechanism and cascading structure in a multi-scale manner. To further leverage these two paradigms, we propose a selective and joint HDR and denoising (SJ-HD$^2$R) imaging framework, utilizing scenario-specific priors to conduct the path selection with an accuracy of more than 93.3$\%$. We create the first joint HDR and denoising benchmark dataset, which contains a variety of challenging HDR and denoising scenes and supports the switching of the reference image. Extensive experiment results show that our method achieves superior performance to previous methods.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022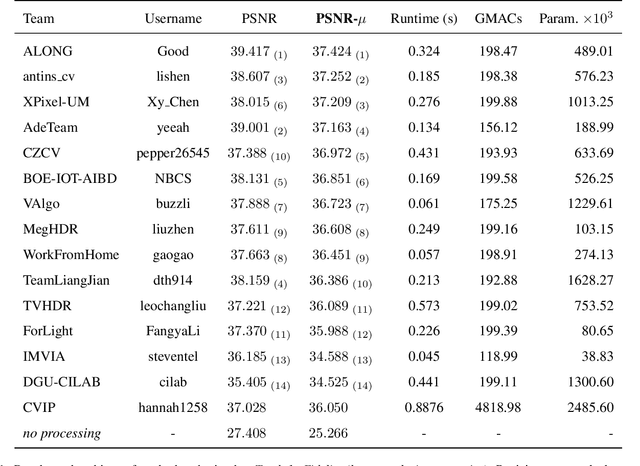
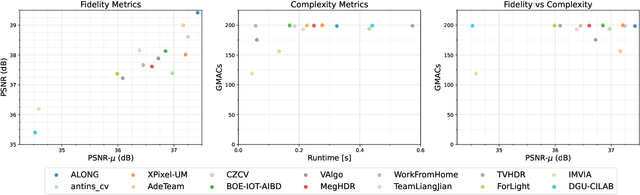
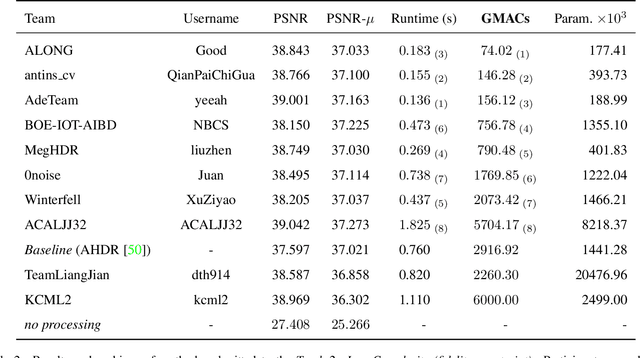
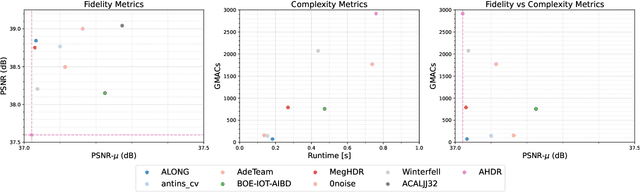
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Diversity-based Trajectory and Goal Selection with Hindsight Experience Replay
Aug 17, 2021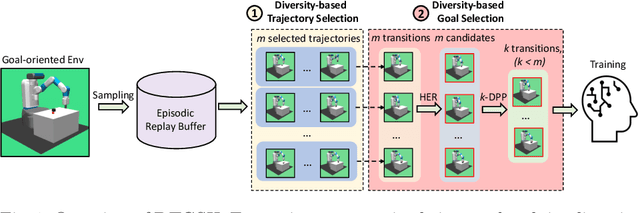
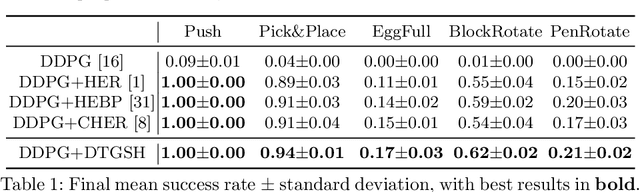
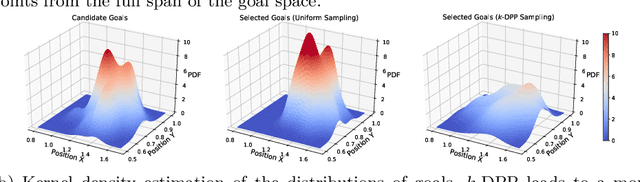

Hindsight experience replay (HER) is a goal relabelling technique typically used with off-policy deep reinforcement learning algorithms to solve goal-oriented tasks; it is well suited to robotic manipulation tasks that deliver only sparse rewards. In HER, both trajectories and transitions are sampled uniformly for training. However, not all of the agent's experiences contribute equally to training, and so naive uniform sampling may lead to inefficient learning. In this paper, we propose diversity-based trajectory and goal selection with HER (DTGSH). Firstly, trajectories are sampled according to the diversity of the goal states as modelled by determinantal point processes (DPPs). Secondly, transitions with diverse goal states are selected from the trajectories by using k-DPPs. We evaluate DTGSH on five challenging robotic manipulation tasks in simulated robot environments, where we show that our method can learn more quickly and reach higher performance than other state-of-the-art approaches on all tasks.