 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Continual Adaptation of Pretrained Robotic Policy with Online Meta-Learned Adapters
Mar 27, 2025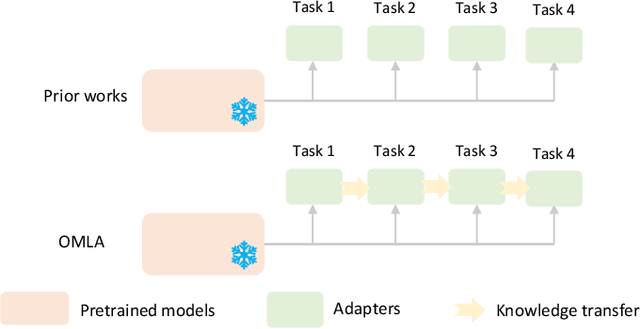
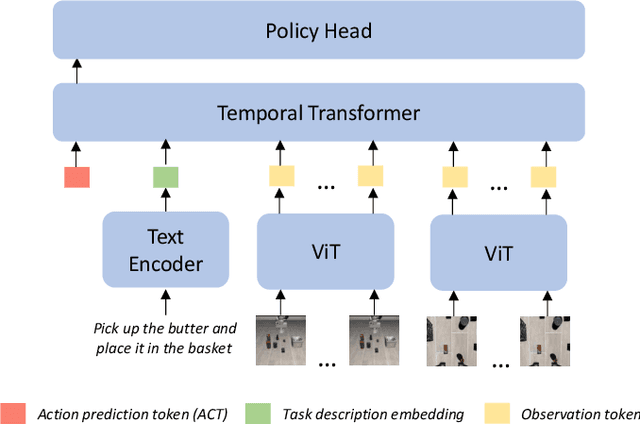
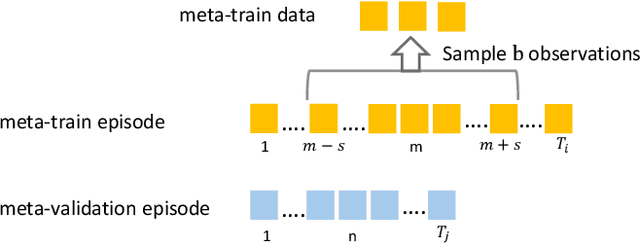

Continual adaptation is essential for general autonomous agents. For example, a household robot pretrained with a repertoire of skills must still adapt to unseen tasks specific to each household. Motivated by this, building upon parameter-efficient fine-tuning in language models, prior works have explored lightweight adapters to adapt pretrained policies, which can preserve learned features from the pretraining phase and demonstrate good adaptation performances. However, these approaches treat task learning separately, limiting knowledge transfer between tasks. In this paper, we propose Online Meta-Learned adapters (OMLA). Instead of applying adapters directly, OMLA can facilitate knowledge transfer from previously learned tasks to current learning tasks through a novel meta-learning objective. Extensive experiments in both simulated and real-world environments demonstrate that OMLA can lead to better adaptation performances compared to the baseline methods. The project link: https://ricky-zhu.github.io/OMLA/.
Efficient Bilinear Attention-based Fusion for Medical Visual Question Answering
Oct 28, 2024Medical Visual Question Answering (MedVQA) has gained increasing attention at the intersection of computer vision and natural language processing. Its capability to interpret radiological images and deliver precise answers to clinical inquiries positions MedVQA as a valuable tool for supporting diagnostic decision-making for physicians and alleviating the workload on radiologists. While recent approaches focus on using unified pre-trained large models for multi-modal fusion like cross-modal Transformers, research on more efficient fusion methods remains relatively scarce within this discipline. In this paper, we introduce a novel fusion model that integrates Orthogonality loss, Multi-head attention and Bilinear Attention Network (OMniBAN) to achieve high computational efficiency and strong performance without the need for pre-training. We conduct comprehensive experiments and clarify aspects of how to enhance bilinear attention fusion to achieve performance comparable to that of large models. Experimental results show that OMniBAN outperforms traditional models on key MedVQA benchmarks while maintaining a lower computational cost, which indicates its potential for efficient clinical application in radiology and pathology image question answering.
CorMulT: A Semi-supervised Modality Correlation-aware Multimodal Transformer for Sentiment Analysis
Jul 09, 2024Multimodal sentiment analysis is an active research area that combines multiple data modalities, e.g., text, image and audio, to analyze human emotions and benefits a variety of applications. Existing multimodal sentiment analysis methods can be classified as modality interaction-based methods, modality transformation-based methods and modality similarity-based methods. However, most of these methods highly rely on the strong correlations between modalities, and cannot fully uncover and utilize the correlations between modalities to enhance sentiment analysis. Therefore, these methods usually achieve bad performance for identifying the sentiment of multimodal data with weak correlations. To address this issue, we proposed a two-stage semi-supervised model termed Correlation-aware Multimodal Transformer (CorMulT) which consists pre-training stage and prediction stage. At the pre-training stage, a modality correlation contrastive learning module is designed to efficiently learn modality correlation coefficients between different modalities. At the prediction stage, the learned correlation coefficients are fused with modality representations to make the sentiment prediction. According to the experiments on the popular multimodal dataset CMU-MOSEI, CorMulT obviously surpasses state-of-the-art multimodal sentiment analysis methods.
Cross Domain Policy Transfer with Effect Cycle-Consistency
Mar 04, 2024
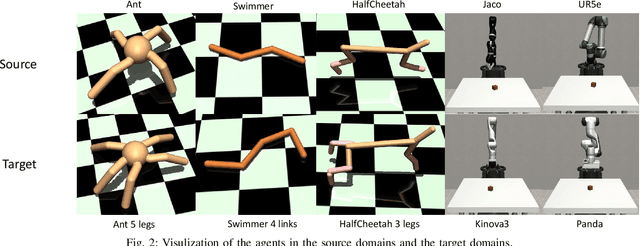
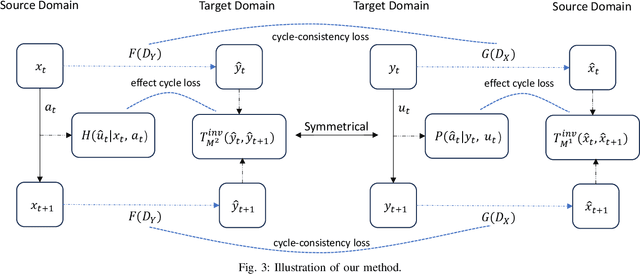
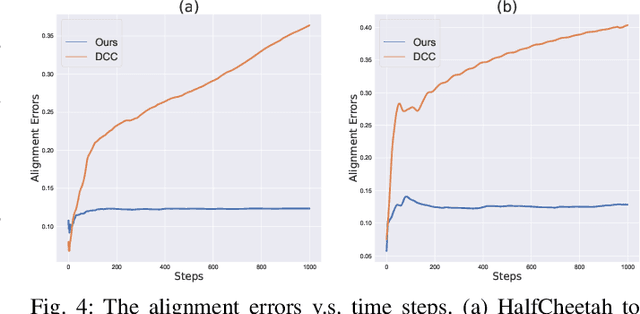
Training a robotic policy from scratch using deep reinforcement learning methods can be prohibitively expensive due to sample inefficiency. To address this challenge, transferring policies trained in the source domain to the target domain becomes an attractive paradigm. Previous research has typically focused on domains with similar state and action spaces but differing in other aspects. In this paper, our primary focus lies in domains with different state and action spaces, which has broader practical implications, i.e. transfer the policy from robot A to robot B. Unlike prior methods that rely on paired data, we propose a novel approach for learning the mapping functions between state and action spaces across domains using unpaired data. We propose effect cycle consistency, which aligns the effects of transitions across two domains through a symmetrical optimization structure for learning these mapping functions. Once the mapping functions are learned, we can seamlessly transfer the policy from the source domain to the target domain. Our approach has been tested on three locomotion tasks and two robotic manipulation tasks. The empirical results demonstrate that our method can reduce alignment errors significantly and achieve better performance compared to the state-of-the-art method.
Learning to Solve Tasks with Exploring Prior Behaviours
Jul 06, 2023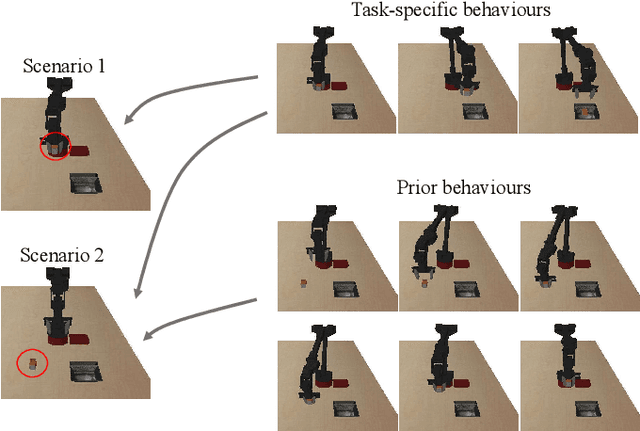
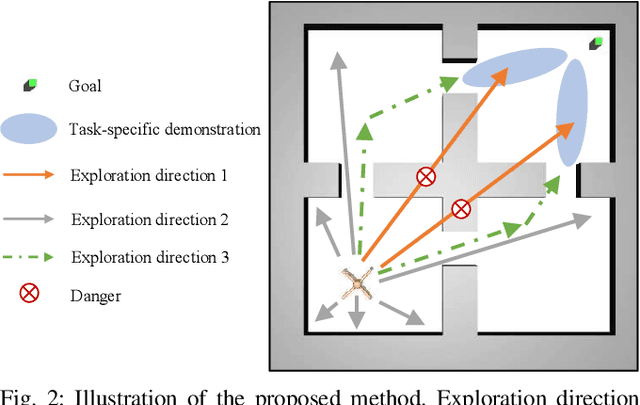
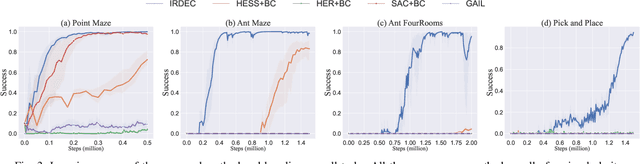
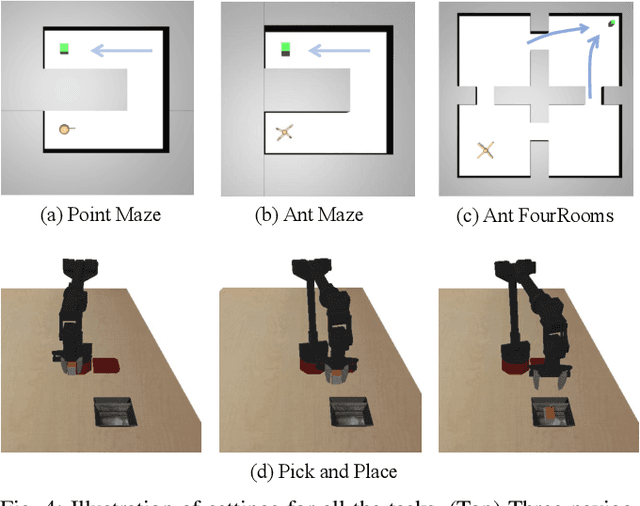
Demonstrations are widely used in Deep Reinforcement Learning (DRL) for facilitating solving tasks with sparse rewards. However, the tasks in real-world scenarios can often have varied initial conditions from the demonstration, which would require additional prior behaviours. For example, consider we are given the demonstration for the task of \emph{picking up an object from an open drawer}, but the drawer is closed in the training. Without acquiring the prior behaviours of opening the drawer, the robot is unlikely to solve the task. To address this, in this paper we propose an Intrinsic Rewards Driven Example-based Control \textbf{(IRDEC)}. Our method can endow agents with the ability to explore and acquire the required prior behaviours and then connect to the task-specific behaviours in the demonstration to solve sparse-reward tasks without requiring additional demonstration of the prior behaviours. The performance of our method outperforms other baselines on three navigation tasks and one robotic manipulation task with sparse rewards. Codes are available at https://github.com/Ricky-Zhu/IRDEC.
Human-Robot Shared Control for Surgical Robot Based on Context-Aware Sim-to-Real Adaptation
Apr 23, 2022



Human-robot shared control, which integrates the advantages of both humans and robots, is an effective approach to facilitate efficient surgical operation. Learning from demonstration (LfD) techniques can be used to automate some of the surgical subtasks for the construction of the shared control mechanism. However, a sufficient amount of data is required for the robot to learn the manoeuvres. Using a surgical simulator to collect data is a less resource-demanding approach. With sim-to-real adaptation, the manoeuvres learned from a simulator can be transferred to a physical robot. To this end, we propose a sim-to-real adaptation method to construct a human-robot shared control framework for robotic surgery. In this paper, a desired trajectory is generated from a simulator using LfD method, while dynamic motion primitives (DMP) is used to transfer the desired trajectory from the simulator to the physical robotic platform. Moreover, a role adaptation mechanism is developed such that the robot can adjust its role according to the surgical operation contexts predicted by a neural network model. The effectiveness of the proposed framework is validated on the da Vinci Research Kit (dVRK). Results of the user studies indicated that with the adaptive human-robot shared control framework, the path length of the remote controller, the total clutching number and the task completion time can be reduced significantly. The proposed method outperformed the traditional manual control via teleoperation.
Deep Reinforcement Learning Based Semi-Autonomous Control for Robotic Surgery
Apr 11, 2022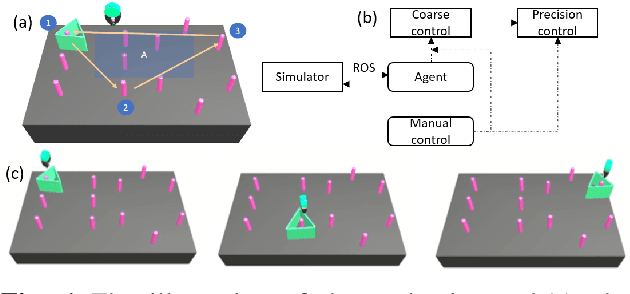
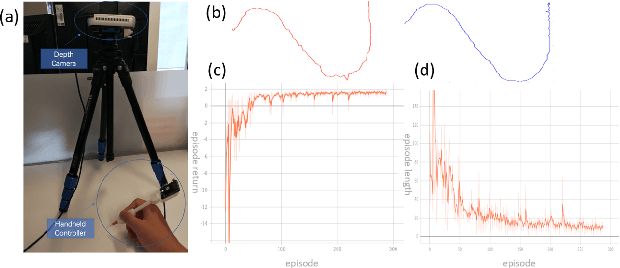

In recent decades, the tremendous benefits surgical robots have brought to surgeons and patients have been witnessed. With the dexterous operation and the great precision, surgical robots can offer patients less recovery time and less hospital stay. However, the controls for current surgical robots in practical usage are fully carried out by surgeons via teleoperation. During the surgery process, there exists a lot of repetitive but simple manipulation, which can cause unnecessary fatigue to the surgeons. In this paper, we proposed a deep reinforcement learning-based semi-autonomous control framework for robotic surgery. The user study showed that the framework can reduce the completion time by 19.1% and the travel length by 58.7%.