 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnect the Dots: Knowledge Graph-Guided Crawler Attack on Retrieval-Augmented Generation Systems
Jan 22, 2026Retrieval-augmented generation (RAG) systems integrate document retrieval with large language models and have been widely adopted. However, in privacy-related scenarios, RAG introduces a new privacy risk: adversaries can issue carefully crafted queries to exfiltrate sensitive content from the underlying corpus gradually. Although recent studies have demonstrated multi-turn extraction attacks, they rely on heuristics and fail to perform long-term extraction planning. To address these limitations, we formulate the RAG extraction attack as an adaptive stochastic coverage problem (ASCP). In ASCP, each query is treated as a probabilistic action that aims to maximize conditional marginal gain (CMG), enabling principled long-term planning under uncertainty. However, integrating ASCP with practical RAG attack faces three key challenges: unobservable CMG, intractability in the action space, and feasibility constraints. To overcome these challenges, we maintain a global attacker-side state to guide the attack. Building on this idea, we introduce RAGCRAWLER, which builds a knowledge graph to represent revealed information, uses this global state to estimate CMG, and plans queries in semantic space that target unretrieved regions. In comprehensive experiments across diverse RAG architectures and datasets, our proposed method, RAGCRAWLER, consistently outperforms all baselines. It achieves up to 84.4% corpus coverage within a fixed query budget and deliver an average improvement of 20.7% over the top-performing baseline. It also maintains high semantic fidelity and strong content reconstruction accuracy with low attack cost. Crucially, RAGCRAWLER proves its robustness by maintaining effectiveness against advanced RAG systems employing query rewriting and multi-query retrieval strategies. Our work reveals significant security gaps and highlights the pressing need for stronger safeguards for RAG.
Vision-Integrated High-Quality Neural Speech Coding
May 29, 2025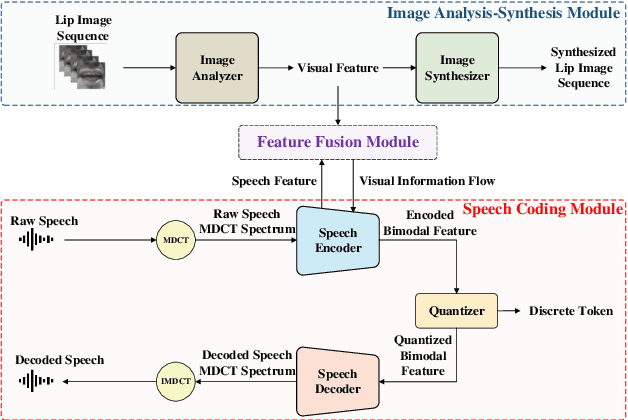
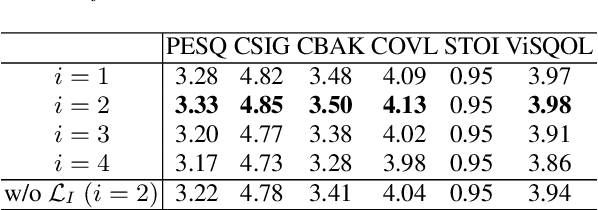
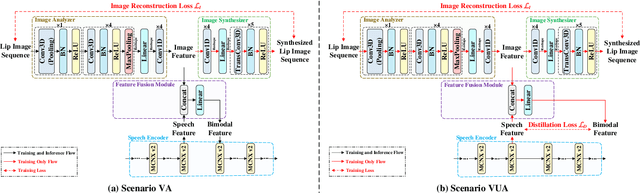
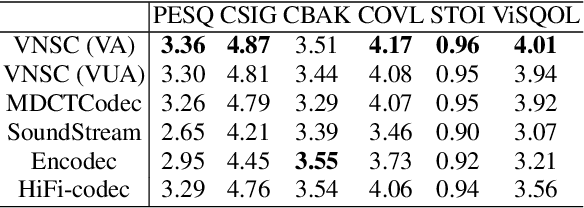
This paper proposes a novel vision-integrated neural speech codec (VNSC), which aims to enhance speech coding quality by leveraging visual modality information. In VNSC, the image analysis-synthesis module extracts visual features from lip images, while the feature fusion module facilitates interaction between the image analysis-synthesis module and the speech coding module, transmitting visual information to assist the speech coding process. Depending on whether visual information is available during the inference stage, the feature fusion module integrates visual features into the speech coding module using either explicit integration or implicit distillation strategies. Experimental results confirm that integrating visual information effectively improves the quality of the decoded speech and enhances the noise robustness of the neural speech codec, without increasing the bitrate.
MAGE: A Multi-task Architecture for Gaze Estimation with an Efficient Calibration Module
May 22, 2025Eye gaze can provide rich information on human psychological activities, and has garnered significant attention in the field of Human-Robot Interaction (HRI). However, existing gaze estimation methods merely predict either the gaze direction or the Point-of-Gaze (PoG) on the screen, failing to provide sufficient information for a comprehensive six Degree-of-Freedom (DoF) gaze analysis in 3D space. Moreover, the variations of eye shape and structure among individuals also impede the generalization capability of these methods. In this study, we propose MAGE, a Multi-task Architecture for Gaze Estimation with an efficient calibration module, to predict the 6-DoF gaze information that is applicable for the real-word HRI. Our basic model encodes both the directional and positional features from facial images, and predicts gaze results with dedicated information flow and multiple decoders. To reduce the impact of individual variations, we propose a novel calibration module, namely Easy-Calibration, to fine-tune the basic model with subject-specific data, which is efficient to implement without the need of a screen. Experimental results demonstrate that our method achieves state-of-the-art performance on the public MPIIFaceGaze, EYEDIAP, and our built IMRGaze datasets.
Moss: Proxy Model-based Full-Weight Aggregation in Federated Learning with Heterogeneous Models
Mar 13, 2025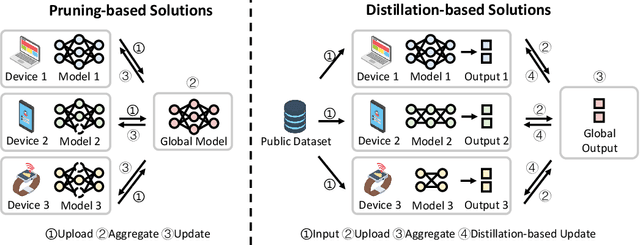
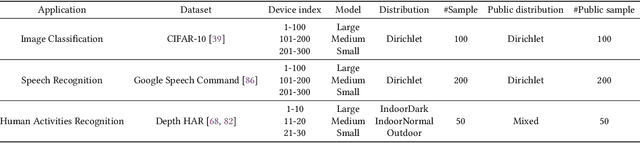
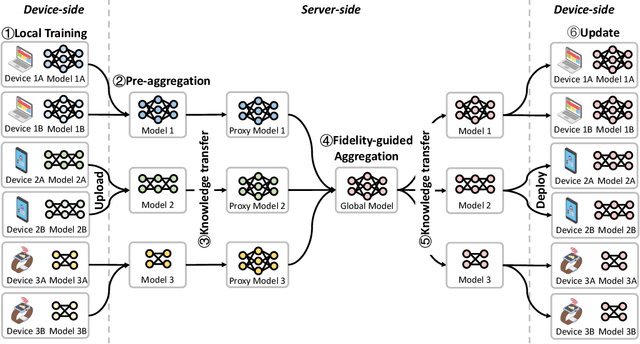

Modern Federated Learning (FL) has become increasingly essential for handling highly heterogeneous mobile devices. Current approaches adopt a partial model aggregation paradigm that leads to sub-optimal model accuracy and higher training overhead. In this paper, we challenge the prevailing notion of partial-model aggregation and propose a novel "full-weight aggregation" method named Moss, which aggregates all weights within heterogeneous models to preserve comprehensive knowledge. Evaluation across various applications demonstrates that Moss significantly accelerates training, reduces on-device training time and energy consumption, enhances accuracy, and minimizes network bandwidth utilization when compared to state-of-the-art baselines.
ChainStream: An LLM-based Framework for Unified Synthetic Sensing
Dec 13, 2024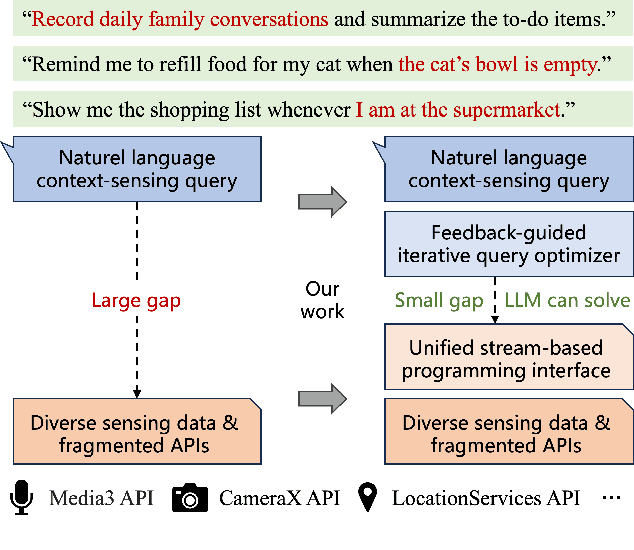
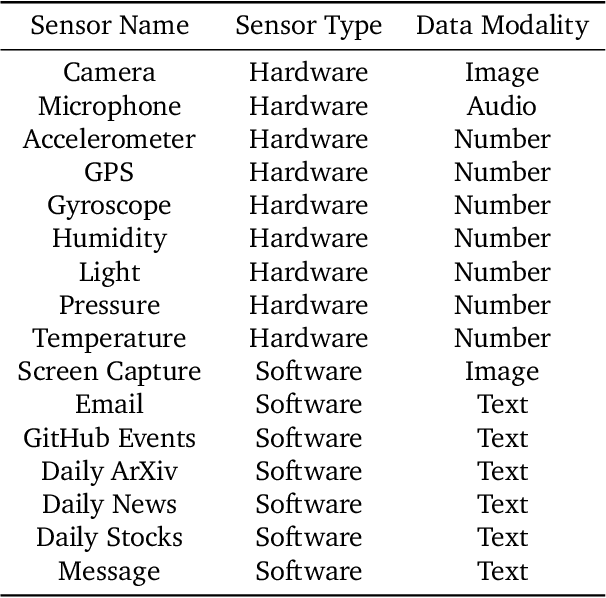
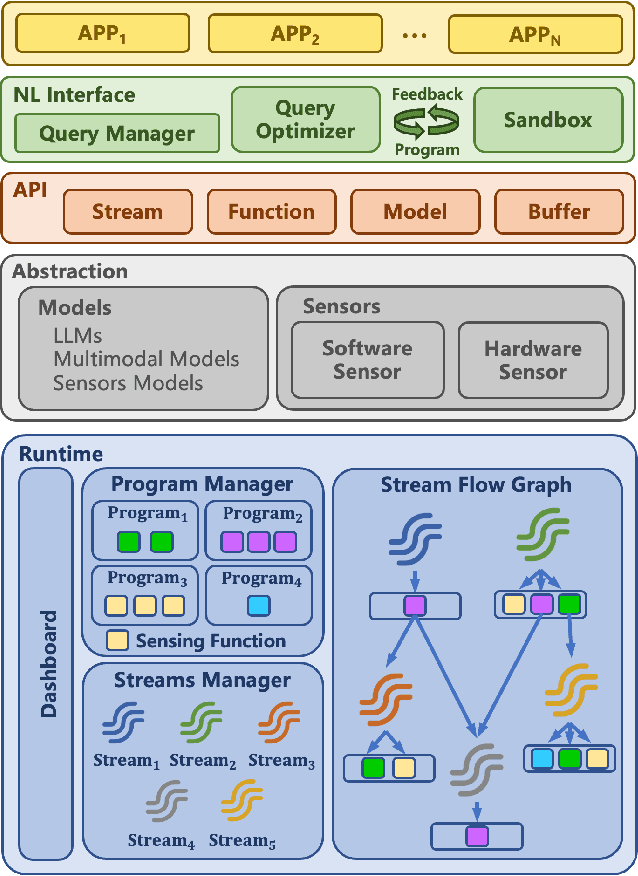

Many applications demand context sensing to offer personalized and timely services. Yet, developing sensing programs can be challenging for developers and using them is privacy-concerning for end-users. In this paper, we propose to use natural language as the unified interface to process personal data and sense user context, which can effectively ease app development and make the data pipeline more transparent. Our work is inspired by large language models (LLMs) and other generative models, while directly applying them does not solve the problem - letting the model directly process the data cannot handle complex sensing requests and letting the model write the data processing program suffers error-prone code generation. We address the problem with 1) a unified data processing framework that makes context-sensing programs simpler and 2) a feedback-guided query optimizer that makes data query more informative. To evaluate the performance of natural language-based context sensing, we create a benchmark that contains 133 context sensing tasks. Extensive evaluation has shown that our approach is able to automatically solve the context-sensing tasks efficiently and precisely. The code is opensourced at https://github.com/MobileLLM/ChainStream.
TEESlice: Protecting Sensitive Neural Network Models in Trusted Execution Environments When Attackers have Pre-Trained Models
Nov 15, 2024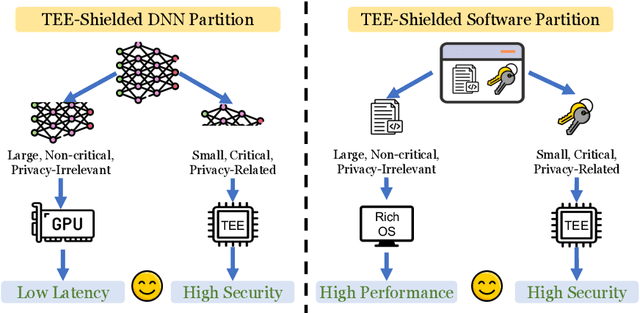
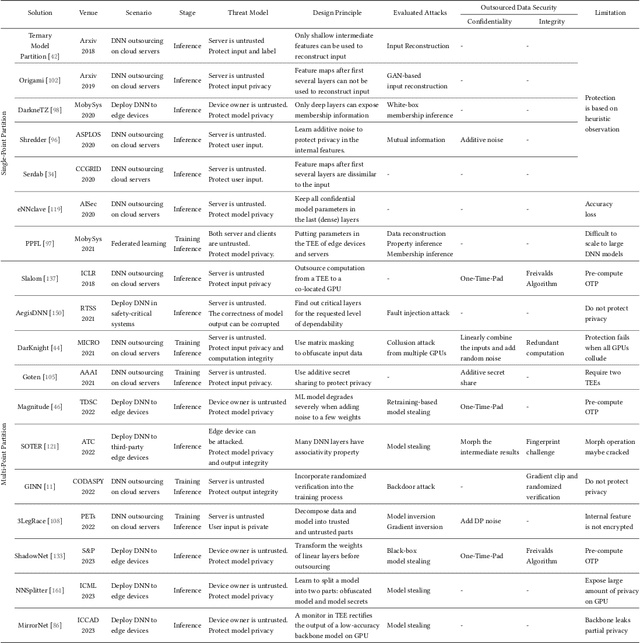
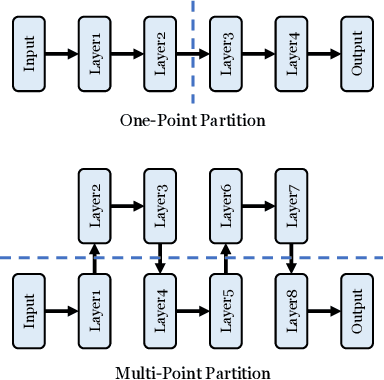
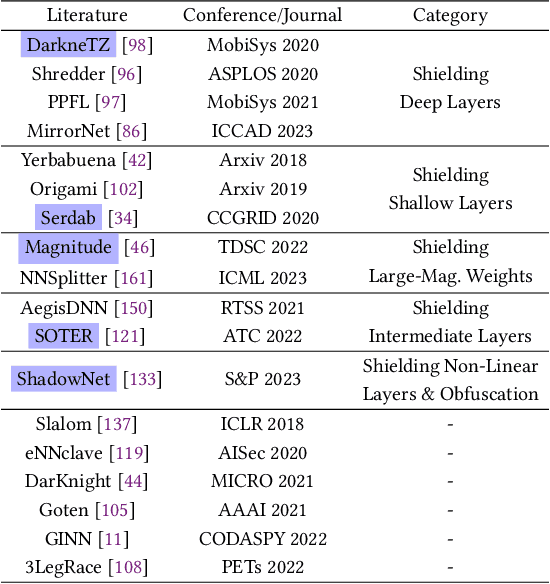
Trusted Execution Environments (TEE) are used to safeguard on-device models. However, directly employing TEEs to secure the entire DNN model is challenging due to the limited computational speed. Utilizing GPU can accelerate DNN's computation speed but commercial widely-available GPUs usually lack security protection. To this end, scholars introduce TSDP, a method that protects privacy-sensitive weights within TEEs and offloads insensitive weights to GPUs. Nevertheless, current methods do not consider the presence of a knowledgeable adversary who can access abundant publicly available pre-trained models and datasets. This paper investigates the security of existing methods against such a knowledgeable adversary and reveals their inability to fulfill their security promises. Consequently, we introduce a novel partition before training strategy, which effectively separates privacy-sensitive weights from other components of the model. Our evaluation demonstrates that our approach can offer full model protection with a computational cost reduced by a factor of 10. In addition to traditional CNN models, we also demonstrate the scalability to large language models. Our approach can compress the private functionalities of the large language model to lightweight slices and achieve the same level of protection as the shielding-whole-model baseline.
GCCRR: A Short Sequence Gait Cycle Segmentation Method Based on Ear-Worn IMU
Sep 02, 2024



This paper addresses the critical task of gait cycle segmentation using short sequences from ear-worn IMUs, a practical and non-invasive approach for home-based monitoring and rehabilitation of patients with impaired motor function. While previous studies have focused on IMUs positioned on the lower limbs, ear-worn IMUs offer a unique advantage in capturing gait dynamics with minimal intrusion. To address the challenges of gait cycle segmentation using short sequences, we introduce the Gait Characteristic Curve Regression and Restoration (GCCRR) method, a novel two-stage approach designed for fine-grained gait phase segmentation. The first stage transforms the segmentation task into a regression task on the Gait Characteristic Curve (GCC), which is a one-dimensional feature sequence incorporating periodic information. The second stage restores the gait cycle using peak detection techniques. Our method employs Bi-LSTM-based deep learning algorithms for regression to ensure reliable segmentation for short gait sequences. Evaluation on the HamlynGait dataset demonstrates that GCCRR achieves over 80\% Accuracy, with a Timestamp Error below one sampling interval. Despite its promising results, the performance lags behind methods using more extensive sensor systems, highlighting the need for larger, more diverse datasets. Future work will focus on data augmentation using motion capture systems and improving algorithmic generalizability.
Beyond Fidelity: Explaining Vulnerability Localization of Learning-based Detectors
Jan 05, 2024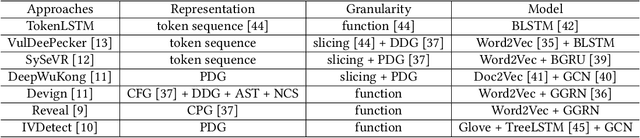
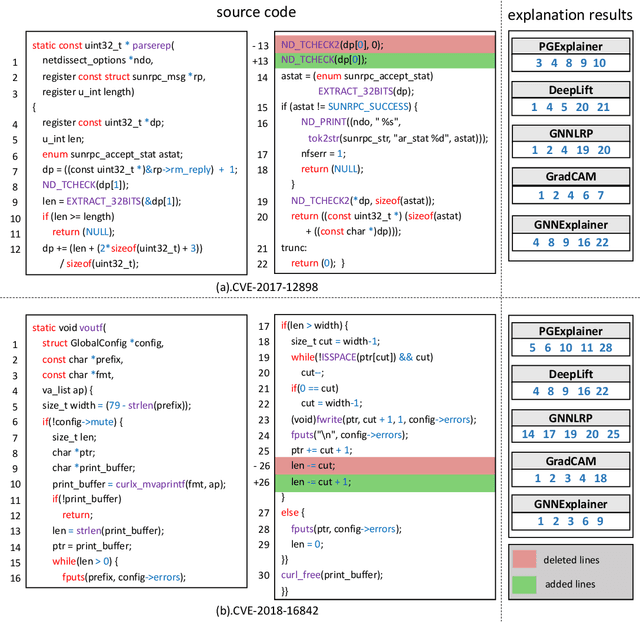
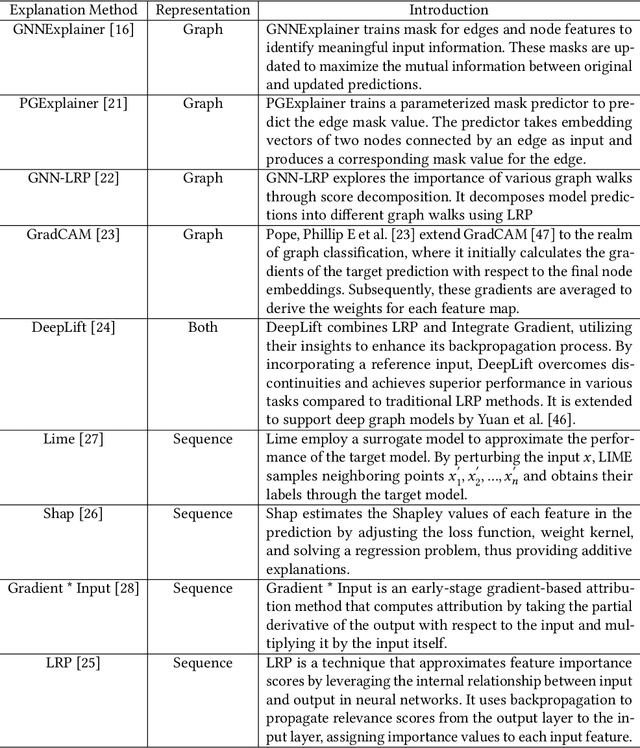
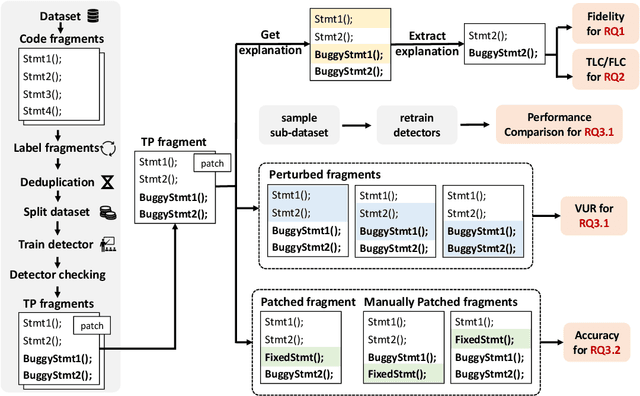
Vulnerability detectors based on deep learning (DL) models have proven their effectiveness in recent years. However, the shroud of opacity surrounding the decision-making process of these detectors makes it difficult for security analysts to comprehend. To address this, various explanation approaches have been proposed to explain the predictions by highlighting important features, which have been demonstrated effective in other domains such as computer vision and natural language processing. Unfortunately, an in-depth evaluation of vulnerability-critical features, such as fine-grained vulnerability-related code lines, learned and understood by these explanation approaches remains lacking. In this study, we first evaluate the performance of ten explanation approaches for vulnerability detectors based on graph and sequence representations, measured by two quantitative metrics including fidelity and vulnerability line coverage rate. Our results show that fidelity alone is not sufficient for evaluating these approaches, as fidelity incurs significant fluctuations across different datasets and detectors. We subsequently check the precision of the vulnerability-related code lines reported by the explanation approaches, and find poor accuracy in this task among all of them. This can be attributed to the inefficiency of explainers in selecting important features and the presence of irrelevant artifacts learned by DL-based detectors.
Learning Deformable Hypothesis Sampling for Accurate PatchMatch Multi-View Stereo
Dec 26, 2023This paper introduces a learnable Deformable Hypothesis Sampler (DeformSampler) to address the challenging issue of noisy depth estimation for accurate PatchMatch Multi-View Stereo (MVS). We observe that the heuristic depth hypothesis sampling modes employed by PatchMatch MVS solvers are insensitive to (i) the piece-wise smooth distribution of depths across the object surface, and (ii) the implicit multi-modal distribution of depth prediction probabilities along the ray direction on the surface points. Accordingly, we develop DeformSampler to learn distribution-sensitive sample spaces to (i) propagate depths consistent with the scene's geometry across the object surface, and (ii) fit a Laplace Mixture model that approaches the point-wise probabilities distribution of the actual depths along the ray direction. We integrate DeformSampler into a learnable PatchMatch MVS system to enhance depth estimation in challenging areas, such as piece-wise discontinuous surface boundaries and weakly-textured regions. Experimental results on DTU and Tanks \& Temples datasets demonstrate its superior performance and generalization capabilities compared to state-of-the-art competitors. Code is available at https://github.com/Geo-Tell/DS-PMNet.
No Privacy Left Outside: On the Security of TEE-Shielded DNN Partition for On-Device ML
Oct 11, 2023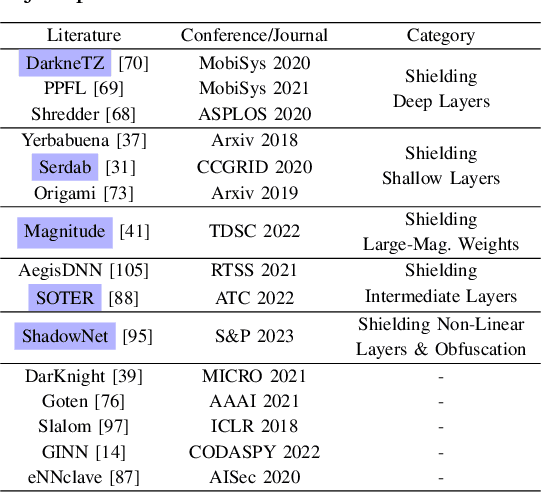
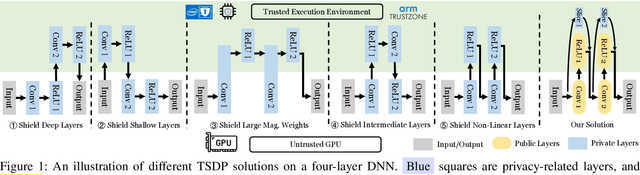
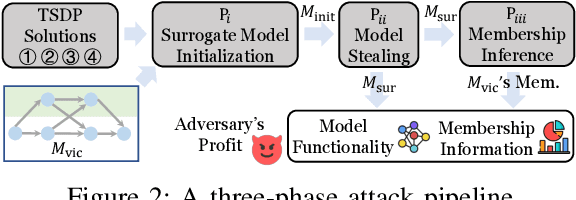
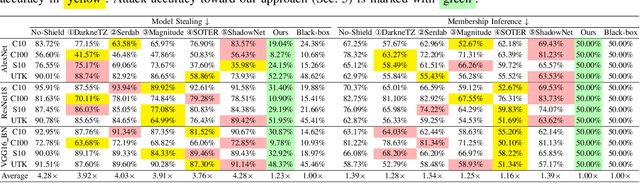
On-device ML introduces new security challenges: DNN models become white-box accessible to device users. Based on white-box information, adversaries can conduct effective model stealing (MS) and membership inference attack (MIA). Using Trusted Execution Environments (TEEs) to shield on-device DNN models aims to downgrade (easy) white-box attacks to (harder) black-box attacks. However, one major shortcoming is the sharply increased latency (up to 50X). To accelerate TEE-shield DNN computation with GPUs, researchers proposed several model partition techniques. These solutions, referred to as TEE-Shielded DNN Partition (TSDP), partition a DNN model into two parts, offloading the privacy-insensitive part to the GPU while shielding the privacy-sensitive part within the TEE. This paper benchmarks existing TSDP solutions using both MS and MIA across a variety of DNN models, datasets, and metrics. We show important findings that existing TSDP solutions are vulnerable to privacy-stealing attacks and are not as safe as commonly believed. We also unveil the inherent difficulty in deciding optimal DNN partition configurations (i.e., the highest security with minimal utility cost) for present TSDP solutions. The experiments show that such ``sweet spot'' configurations vary across datasets and models. Based on lessons harvested from the experiments, we present TEESlice, a novel TSDP method that defends against MS and MIA during DNN inference. TEESlice follows a partition-before-training strategy, which allows for accurate separation between privacy-related weights from public weights. TEESlice delivers the same security protection as shielding the entire DNN model inside TEE (the ``upper-bound'' security guarantees) with over 10X less overhead (in both experimental and real-world environments) than prior TSDP solutions and no accuracy loss.