 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Attention Mechanism in Video Diffusion Models
Apr 16, 2025Text-to-video (T2V) synthesis models, such as OpenAI's Sora, have garnered significant attention due to their ability to generate high-quality videos from a text prompt. In diffusion-based T2V models, the attention mechanism is a critical component. However, it remains unclear what intermediate features are learned and how attention blocks in T2V models affect various aspects of video synthesis, such as image quality and temporal consistency. In this paper, we conduct an in-depth perturbation analysis of the spatial and temporal attention blocks of T2V models using an information-theoretic approach. Our results indicate that temporal and spatial attention maps affect not only the timing and layout of the videos but also the complexity of spatiotemporal elements and the aesthetic quality of the synthesized videos. Notably, high-entropy attention maps are often key elements linked to superior video quality, whereas low-entropy attention maps are associated with the video's intra-frame structure. Based on our findings, we propose two novel methods to enhance video quality and enable text-guided video editing. These methods rely entirely on lightweight manipulation of the attention matrices in T2V models. The efficacy and effectiveness of our methods are further validated through experimental evaluation across multiple datasets.
BTFL: A Bayesian-based Test-Time Generalization Method for Internal and External Data Distributions in Federated learning
Mar 09, 2025Federated Learning (FL) enables multiple clients to collaboratively develop a global model while maintaining data privacy. However, online FL deployment faces challenges due to distribution shifts and evolving test samples. Personalized Federated Learning (PFL) tailors the global model to individual client distributions, but struggles with Out-Of-Distribution (OOD) samples during testing, leading to performance degradation. In real-world scenarios, balancing personalization and generalization during online testing is crucial and existing methods primarily focus on training-phase generalization. To address the test-time trade-off, we introduce a new scenario: Test-time Generalization for Internal and External Distributions in Federated Learning (TGFL), which evaluates adaptability under Internal Distribution (IND) and External Distribution (EXD). We propose BTFL, a Bayesian-based test-time generalization method for TGFL, which balances generalization and personalization at the sample level during testing. BTFL employs a two-head architecture to store local and global knowledge, interpolating predictions via a dual-Bayesian framework that considers both historical test data and current sample characteristics with theoretical guarantee and faster speed. Our experiments demonstrate that BTFL achieves improved performance across various datasets and models with less time cost. The source codes are made publicly available at https://github.com/ZhouYuCS/BTFL .
A Separable Self-attention Inspired by the State Space Model for Computer Vision
Jan 03, 2025



Mamba is an efficient State Space Model (SSM) with linear computational complexity. Although SSMs are not suitable for handling non-causal data, Vision Mamba (ViM) methods still demonstrate good performance in tasks such as image classification and object detection. Recent studies have shown that there is a rich theoretical connection between state space models and attention variants. We propose a novel separable self attention method, for the first time introducing some excellent design concepts of Mamba into separable self-attention. To ensure a fair comparison with ViMs, we introduce VMINet, a simple yet powerful prototype architecture, constructed solely by stacking our novel attention modules with the most basic down-sampling layers. Notably, VMINet differs significantly from the conventional Transformer architecture. Our experiments demonstrate that VMINet has achieved competitive results on image classification and high-resolution dense prediction tasks.Code is available at: \url{https://github.com/yws-wxs/VMINet}.
Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing
Mar 06, 2024



Deep Text-to-Image Synthesis (TIS) models such as Stable Diffusion have recently gained significant popularity for creative Text-to-image generation. Yet, for domain-specific scenarios, tuning-free Text-guided Image Editing (TIE) is of greater importance for application developers, which modify objects or object properties in images by manipulating feature components in attention layers during the generation process. However, little is known about what semantic meanings these attention layers have learned and which parts of the attention maps contribute to the success of image editing. In this paper, we conduct an in-depth probing analysis and demonstrate that cross-attention maps in Stable Diffusion often contain object attribution information that can result in editing failures. In contrast, self-attention maps play a crucial role in preserving the geometric and shape details of the source image during the transformation to the target image. Our analysis offers valuable insights into understanding cross and self-attention maps in diffusion models. Moreover, based on our findings, we simplify popular image editing methods and propose a more straightforward yet more stable and efficient tuning-free procedure that only modifies self-attention maps of the specified attention layers during the denoising process. Experimental results show that our simplified method consistently surpasses the performance of popular approaches on multiple datasets.
BeautifulPrompt: Towards Automatic Prompt Engineering for Text-to-Image Synthesis
Nov 12, 2023Recently, diffusion-based deep generative models (e.g., Stable Diffusion) have shown impressive results in text-to-image synthesis. However, current text-to-image models often require multiple passes of prompt engineering by humans in order to produce satisfactory results for real-world applications. We propose BeautifulPrompt, a deep generative model to produce high-quality prompts from very simple raw descriptions, which enables diffusion-based models to generate more beautiful images. In our work, we first fine-tuned the BeautifulPrompt model over low-quality and high-quality collecting prompt pairs. Then, to ensure that our generated prompts can generate more beautiful images, we further propose a Reinforcement Learning with Visual AI Feedback technique to fine-tune our model to maximize the reward values of the generated prompts, where the reward values are calculated based on the PickScore and the Aesthetic Scores. Our results demonstrate that learning from visual AI feedback promises the potential to improve the quality of generated prompts and images significantly. We further showcase the integration of BeautifulPrompt to a cloud-native AI platform to provide better text-to-image generation service in the cloud.
No Privacy Left Outside: On the Security of TEE-Shielded DNN Partition for On-Device ML
Oct 11, 2023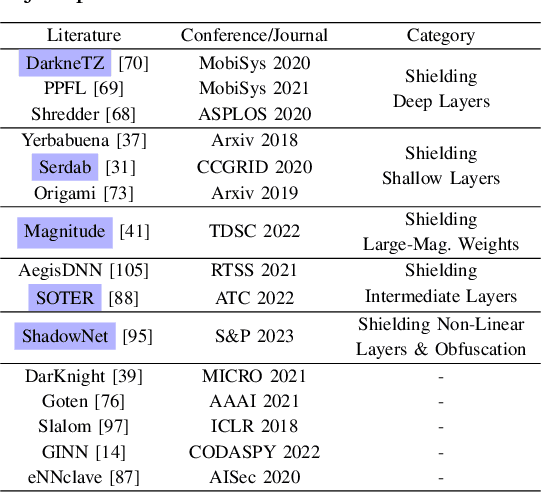
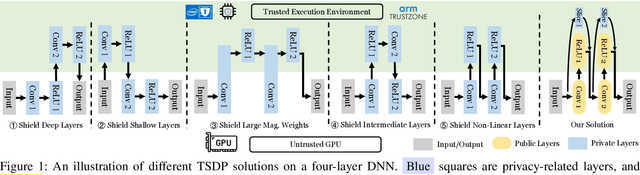
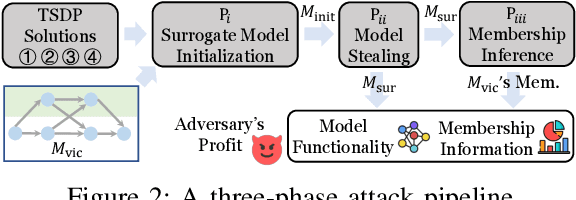
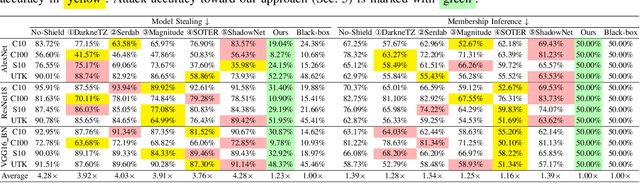
On-device ML introduces new security challenges: DNN models become white-box accessible to device users. Based on white-box information, adversaries can conduct effective model stealing (MS) and membership inference attack (MIA). Using Trusted Execution Environments (TEEs) to shield on-device DNN models aims to downgrade (easy) white-box attacks to (harder) black-box attacks. However, one major shortcoming is the sharply increased latency (up to 50X). To accelerate TEE-shield DNN computation with GPUs, researchers proposed several model partition techniques. These solutions, referred to as TEE-Shielded DNN Partition (TSDP), partition a DNN model into two parts, offloading the privacy-insensitive part to the GPU while shielding the privacy-sensitive part within the TEE. This paper benchmarks existing TSDP solutions using both MS and MIA across a variety of DNN models, datasets, and metrics. We show important findings that existing TSDP solutions are vulnerable to privacy-stealing attacks and are not as safe as commonly believed. We also unveil the inherent difficulty in deciding optimal DNN partition configurations (i.e., the highest security with minimal utility cost) for present TSDP solutions. The experiments show that such ``sweet spot'' configurations vary across datasets and models. Based on lessons harvested from the experiments, we present TEESlice, a novel TSDP method that defends against MS and MIA during DNN inference. TEESlice follows a partition-before-training strategy, which allows for accurate separation between privacy-related weights from public weights. TEESlice delivers the same security protection as shielding the entire DNN model inside TEE (the ``upper-bound'' security guarantees) with over 10X less overhead (in both experimental and real-world environments) than prior TSDP solutions and no accuracy loss.
PAI-Diffusion: Constructing and Serving a Family of Open Chinese Diffusion Models for Text-to-image Synthesis on the Cloud
Sep 11, 2023



Text-to-image synthesis for the Chinese language poses unique challenges due to its large vocabulary size, and intricate character relationships. While existing diffusion models have shown promise in generating images from textual descriptions, they often neglect domain-specific contexts and lack robustness in handling the Chinese language. This paper introduces PAI-Diffusion, a comprehensive framework that addresses these limitations. PAI-Diffusion incorporates both general and domain-specific Chinese diffusion models, enabling the generation of contextually relevant images. It explores the potential of using LoRA and ControlNet for fine-grained image style transfer and image editing, empowering users with enhanced control over image generation. Moreover, PAI-Diffusion seamlessly integrates with Alibaba Cloud's Machine Learning Platform for AI, providing accessible and scalable solutions. All the Chinese diffusion model checkpoints, LoRAs, and ControlNets, including domain-specific ones, are publicly available. A user-friendly Chinese WebUI and the diffusers-api elastic inference toolkit, also open-sourced, further facilitate the easy deployment of PAI-Diffusion models in various environments, making it a valuable resource for Chinese text-to-image synthesis.
Recent Advances on Federated Learning: A Systematic Survey
Jan 03, 2023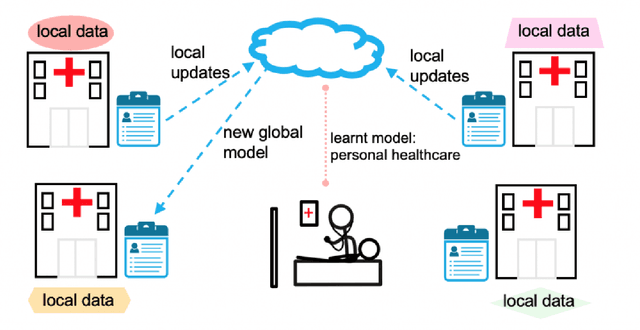
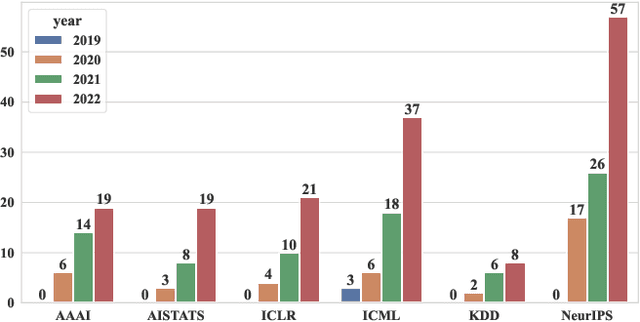
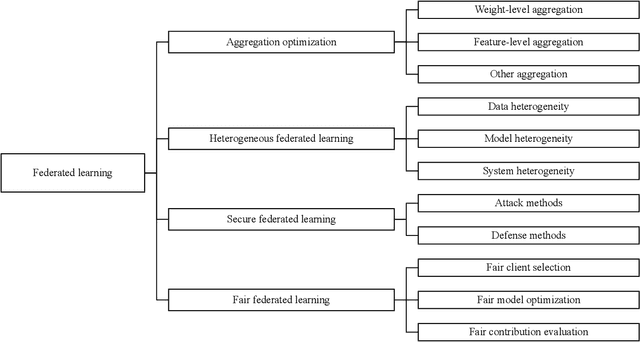

Federated learning has emerged as an effective paradigm to achieve privacy-preserving collaborative learning among different parties. Compared to traditional centralized learning that requires collecting data from each party, in federated learning, only the locally trained models or computed gradients are exchanged, without exposing any data information. As a result, it is able to protect privacy to some extent. In recent years, federated learning has become more and more prevalent and there have been many surveys for summarizing related methods in this hot research topic. However, most of them focus on a specific perspective or lack the latest research progress. In this paper, we provide a systematic survey on federated learning, aiming to review the recent advanced federated methods and applications from different aspects. Specifically, this paper includes four major contributions. First, we present a new taxonomy of federated learning in terms of the pipeline and challenges in federated scenarios. Second, we summarize federated learning methods into several categories and briefly introduce the state-of-the-art methods under these categories. Third, we overview some prevalent federated learning frameworks and introduce their features. Finally, some potential deficiencies of current methods and several future directions are discussed.
DistFL: Distribution-aware Federated Learning for Mobile Scenarios
Oct 22, 2021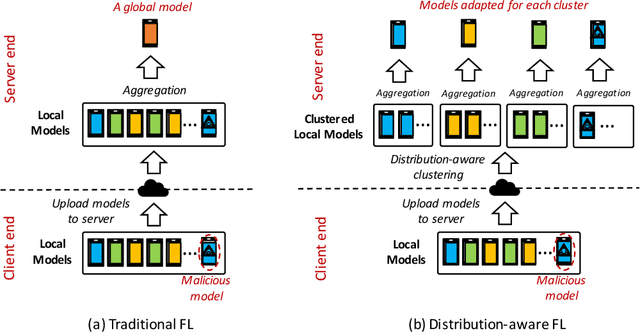
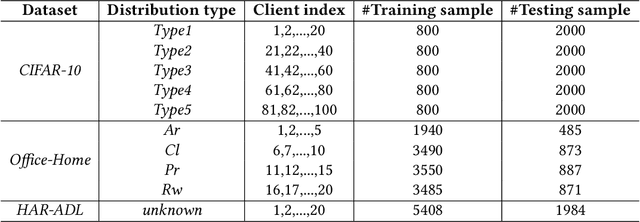
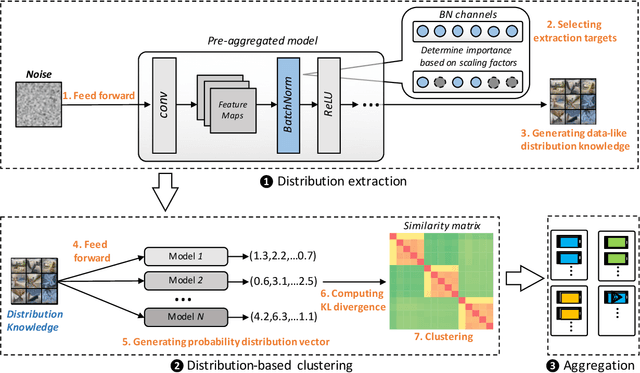
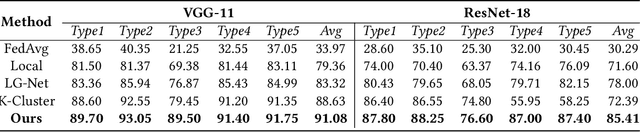
Federated learning (FL) has emerged as an effective solution to decentralized and privacy-preserving machine learning for mobile clients. While traditional FL has demonstrated its superiority, it ignores the non-iid (independently identically distributed) situation, which widely exists in mobile scenarios. Failing to handle non-iid situations could cause problems such as performance decreasing and possible attacks. Previous studies focus on the "symptoms" directly, as they try to improve the accuracy or detect possible attacks by adding extra steps to conventional FL models. However, previous techniques overlook the root causes for the "symptoms": blindly aggregating models with the non-iid distributions. In this paper, we try to fundamentally address the issue by decomposing the overall non-iid situation into several iid clusters and conducting aggregation in each cluster. Specifically, we propose \textbf{DistFL}, a novel framework to achieve automated and accurate \textbf{Dist}ribution-aware \textbf{F}ederated \textbf{L}earning in a cost-efficient way. DistFL achieves clustering via extracting and comparing the \textit{distribution knowledge} from the uploaded models. With this framework, we are able to generate multiple personalized models with distinctive distributions and assign them to the corresponding clients. Extensive experiments on mobile scenarios with popular model architectures have demonstrated the effectiveness of DistFL.
ModelDiff: Testing-Based DNN Similarity Comparison for Model Reuse Detection
Jun 11, 2021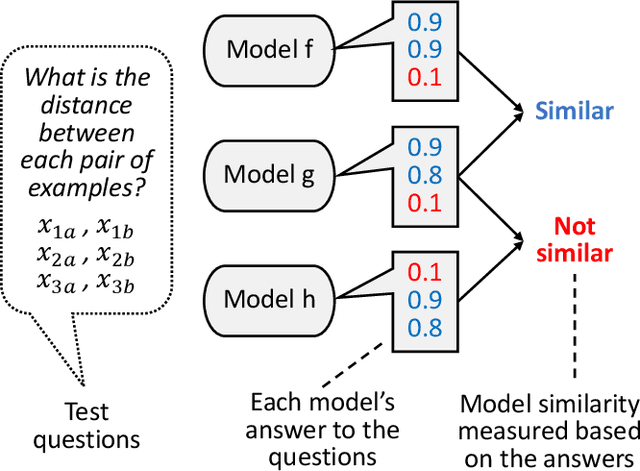

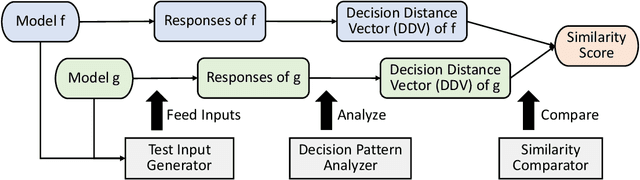

The knowledge of a deep learning model may be transferred to a student model, leading to intellectual property infringement or vulnerability propagation. Detecting such knowledge reuse is nontrivial because the suspect models may not be white-box accessible and/or may serve different tasks. In this paper, we propose ModelDiff, a testing-based approach to deep learning model similarity comparison. Instead of directly comparing the weights, activations, or outputs of two models, we compare their behavioral patterns on the same set of test inputs. Specifically, the behavioral pattern of a model is represented as a decision distance vector (DDV), in which each element is the distance between the model's reactions to a pair of inputs. The knowledge similarity between two models is measured with the cosine similarity between their DDVs. To evaluate ModelDiff, we created a benchmark that contains 144 pairs of models that cover most popular model reuse methods, including transfer learning, model compression, and model stealing. Our method achieved 91.7% correctness on the benchmark, which demonstrates the effectiveness of using ModelDiff for model reuse detection. A study on mobile deep learning apps has shown the feasibility of ModelDiff on real-world models.