 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtifact Removal and Image Restoration in AFM:A Structured Mask-Guided Directional Inpainting Approach
Feb 03, 2026Atomic Force Microscopy (AFM) enables high-resolution surface imaging at the nanoscale, yet the output is often degraded by artifacts introduced by environmental noise, scanning imperfections, and tip-sample interactions. To address this challenge, a lightweight and fully automated framework for artifact detection and restoration in AFM image analysis is presented. The pipeline begins with a classification model that determines whether an AFM image contains artifacts. If necessary, a lightweight semantic segmentation network, custom-designed and trained on AFM data, is applied to generate precise artifact masks. These masks are adaptively expanded based on their structural orientation and then inpainted using a directional neighbor-based interpolation strategy to preserve 3D surface continuity. A localized Gaussian smoothing operation is then applied for seamless restoration. The system is integrated into a user-friendly GUI that supports real-time parameter adjustments and batch processing. Experimental results demonstrate the effective artifact removal while preserving nanoscale structural details, providing a robust, geometry-aware solution for high-fidelity AFM data interpretation.
MARO: Learning Stronger Reasoning from Social Interaction
Jan 18, 2026Humans face countless scenarios that require reasoning and judgment in daily life. However, existing large language model training methods primarily allow models to learn from existing textual content or solve predetermined problems, lacking experience in real scenarios involving interaction, negotiation, and competition with others. To address this, this paper proposes Multi-Agent Reward Optimization (MARO), a method that enables large language models (LLMs) to acquire stronger reasoning abilities by learning and practicing in multi-agent social environments. Specifically, MARO first addresses the sparse learning signal problem by decomposing final success or failure outcomes into each specific behavior during the interaction process; second, it handles the uneven role distribution problem by balancing the training sample weights of different roles; finally, it addresses environmental instability issues by directly evaluating the utility of each behavior. Experimental results demonstrate that MARO not only achieves significant improvements in social reasoning capabilities, but also that the abilities acquired through social simulation learning can effectively transfer to other tasks such as mathematical reasoning and instruction following. This reveals the tremendous potential of multi-agent social learning in enhancing the general reasoning capabilities of LLMs.
From Chains to Graphs: Self-Structured Reasoning for General-Domain LLMs
Jan 07, 2026Large Language Models (LLMs) show strong reasoning ability in open-domain question answering, yet their reasoning processes are typically linear and often logically inconsistent. In contrast, real-world reasoning requires integrating multiple premises and solving subproblems in parallel. Existing methods, such as Chain-of-Thought (CoT), express reasoning in a linear textual form, which may appear coherent but frequently leads to inconsistent conclusions. Recent approaches rely on externally provided graphs and do not explore how LLMs can construct and use their own graph-structured reasoning, particularly in open-domain QA. To fill this gap, we novelly explore graph-structured reasoning of LLMs in general-domain question answering. We propose Self-Graph Reasoning (SGR), a framework that enables LLMs to explicitly represent their reasoning process as a structured graph before producing the final answer. We further construct a graph-structured reasoning dataset that merges multiple candidate reasoning graphs into refined graph structures for model training. Experiments on five QA benchmarks across both general and specialized domains show that SGR consistently improves reasoning consistency and yields a 17.74% gain over the base model. The LLaMA-3.3-70B model fine-tuned with SGR performs comparably to GPT-4o and surpasses Claude-3.5-Haiku, demonstrating the effectiveness of graph-structured reasoning.
A Separable Self-attention Inspired by the State Space Model for Computer Vision
Jan 03, 2025



Mamba is an efficient State Space Model (SSM) with linear computational complexity. Although SSMs are not suitable for handling non-causal data, Vision Mamba (ViM) methods still demonstrate good performance in tasks such as image classification and object detection. Recent studies have shown that there is a rich theoretical connection between state space models and attention variants. We propose a novel separable self attention method, for the first time introducing some excellent design concepts of Mamba into separable self-attention. To ensure a fair comparison with ViMs, we introduce VMINet, a simple yet powerful prototype architecture, constructed solely by stacking our novel attention modules with the most basic down-sampling layers. Notably, VMINet differs significantly from the conventional Transformer architecture. Our experiments demonstrate that VMINet has achieved competitive results on image classification and high-resolution dense prediction tasks.Code is available at: \url{https://github.com/yws-wxs/VMINet}.
AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data
Oct 15, 2024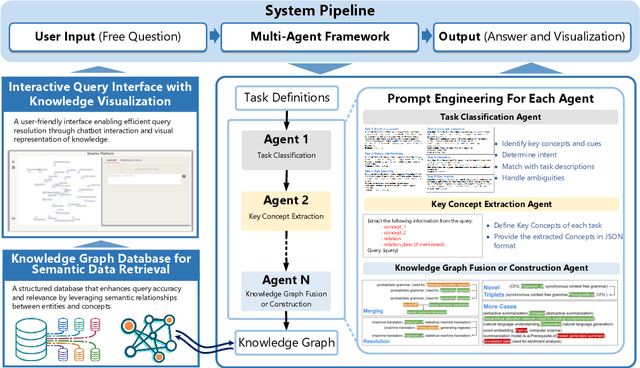
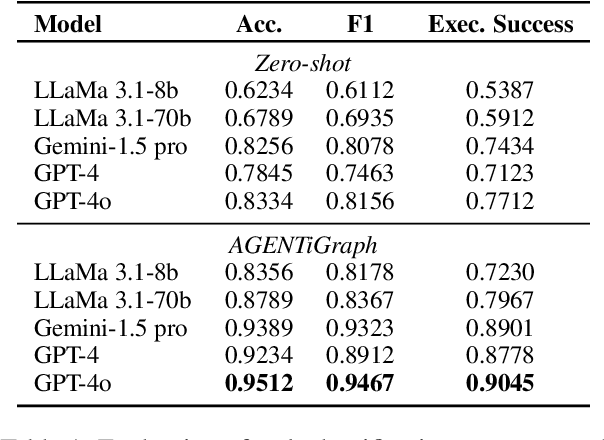
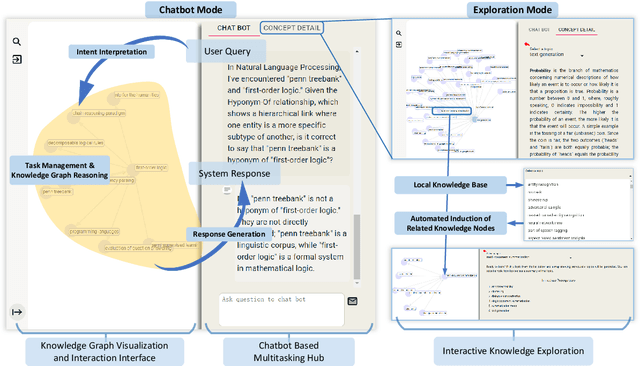
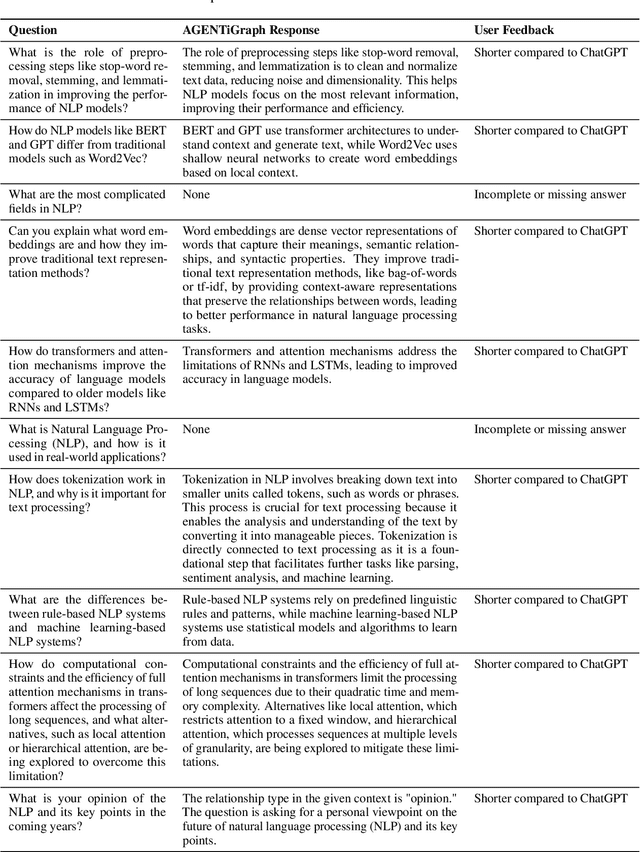
Large Language Models~(LLMs) have demonstrated capabilities across various applications but face challenges such as hallucination, limited reasoning abilities, and factual inconsistencies, especially when tackling complex, domain-specific tasks like question answering~(QA). While Knowledge Graphs~(KGs) have been shown to help mitigate these issues, research on the integration of LLMs with background KGs remains limited. In particular, user accessibility and the flexibility of the underlying KG have not been thoroughly explored. We introduce AGENTiGraph (Adaptive Generative ENgine for Task-based Interaction and Graphical Representation), a platform for knowledge management through natural language interaction. It integrates knowledge extraction, integration, and real-time visualization. AGENTiGraph employs a multi-agent architecture to dynamically interpret user intents, manage tasks, and integrate new knowledge, ensuring adaptability to evolving user requirements and data contexts. Our approach demonstrates superior performance in knowledge graph interactions, particularly for complex domain-specific tasks. Experimental results on a dataset of 3,500 test cases show AGENTiGraph significantly outperforms state-of-the-art zero-shot baselines, achieving 95.12\% accuracy in task classification and 90.45\% success rate in task execution. User studies corroborate its effectiveness in real-world scenarios. To showcase versatility, we extended AGENTiGraph to legislation and healthcare domains, constructing specialized KGs capable of answering complex queries in legal and medical contexts.
Vim-F: Visual State Space Model Benefiting from Learning in the Frequency Domain
May 29, 2024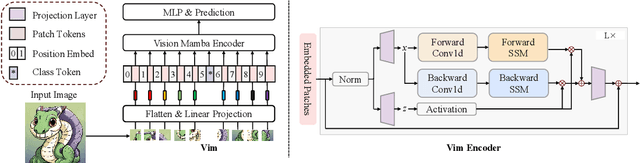

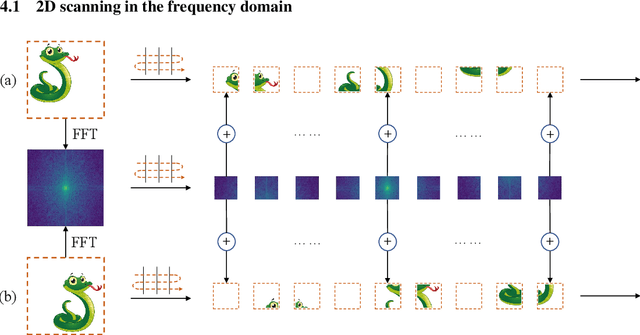
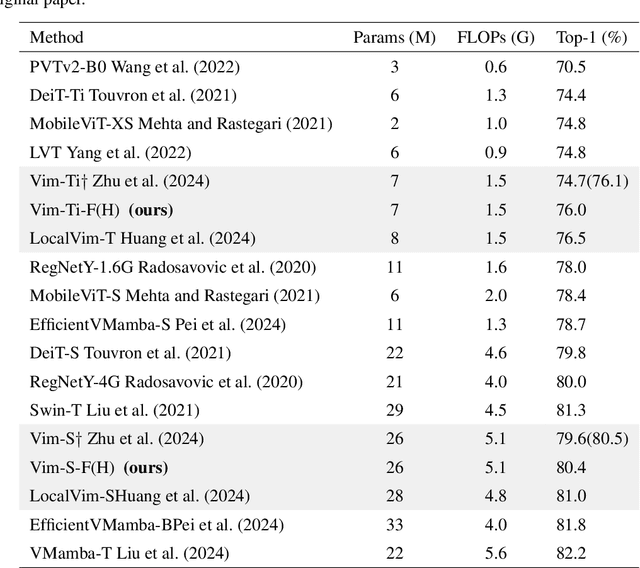
In recent years, State Space Models (SSMs) with efficient hardware-aware designs, known as the Mamba deep learning models, have made significant progress in modeling long sequences such as language understanding. Therefore, building efficient and general-purpose visual backbones based on SSMs is a promising direction. Compared to traditional convolutional neural networks (CNNs) and Vision Transformers (ViTs), the performance of Vision Mamba (ViM) methods is not yet fully competitive. To enable SSMs to process image data, ViMs typically flatten 2D images into 1D sequences, inevitably ignoring some 2D local dependencies, thereby weakening the model's ability to interpret spatial relationships from a global perspective. We use Fast Fourier Transform (FFT) to obtain the spectrum of the feature map and add it to the original feature map, enabling ViM to model a unified visual representation in both frequency and spatial domains. The introduction of frequency domain information enables ViM to have a global receptive field during scanning. We propose a novel model called Vim-F, which employs pure Mamba encoders and scans in both the frequency and spatial domains. Moreover, we question the necessity of position embedding in ViM and remove it accordingly in Vim-F, which helps to fully utilize the efficient long-sequence modeling capability of ViM. Finally, we redesign a patch embedding for Vim-F, leveraging a convolutional stem to capture more local correlations, further improving the performance of Vim-F. Code is available at: \url{https://github.com/yws-wxs/Vim-F}.
C3Net: Compound Conditioned ControlNet for Multimodal Content Generation
Nov 29, 2023
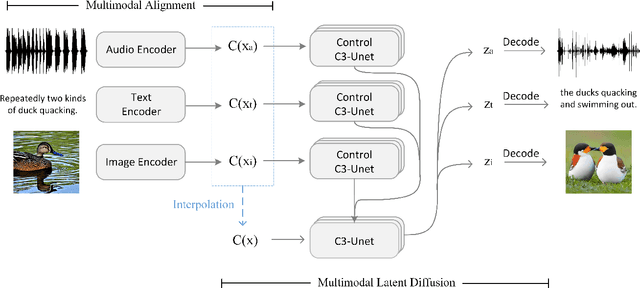

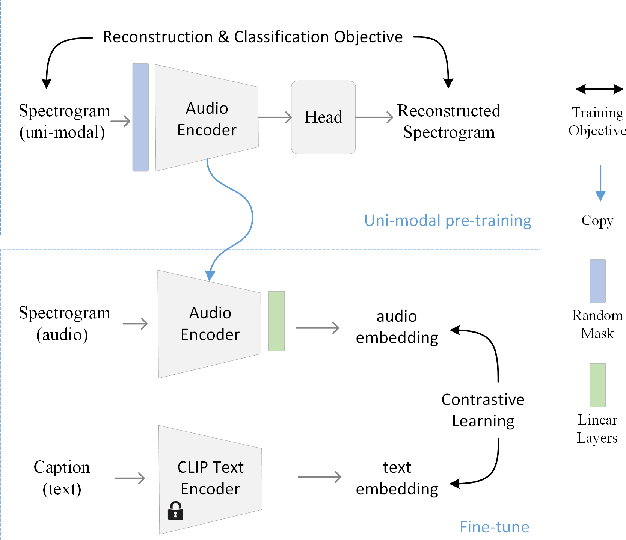
We present Compound Conditioned ControlNet, C3Net, a novel generative neural architecture taking conditions from multiple modalities and synthesizing multimodal contents simultaneously (e.g., image, text, audio). C3Net adapts the ControlNet architecture to jointly train and make inferences on a production-ready diffusion model and its trainable copies. Specifically, C3Net first aligns the conditions from multi-modalities to the same semantic latent space using modality-specific encoders based on contrastive training. Then, it generates multimodal outputs based on the aligned latent space, whose semantic information is combined using a ControlNet-like architecture called Control C3-UNet. Correspondingly, with this system design, our model offers an improved solution for joint-modality generation through learning and explaining multimodal conditions instead of simply taking linear interpolations on the latent space. Meanwhile, as we align conditions to a unified latent space, C3Net only requires one trainable Control C3-UNet to work on multimodal semantic information. Furthermore, our model employs unimodal pretraining on the condition alignment stage, outperforming the non-pretrained alignment even on relatively scarce training data and thus demonstrating high-quality compound condition generation. We contribute the first high-quality tri-modal validation set to validate quantitatively that C3Net outperforms or is on par with first and contemporary state-of-the-art multimodal generation. Our codes and tri-modal dataset will be released.
Dependency Relationships-Enhanced Attentive Group Recommendation in HINs
Nov 19, 2023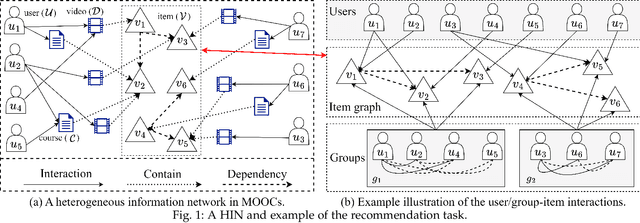

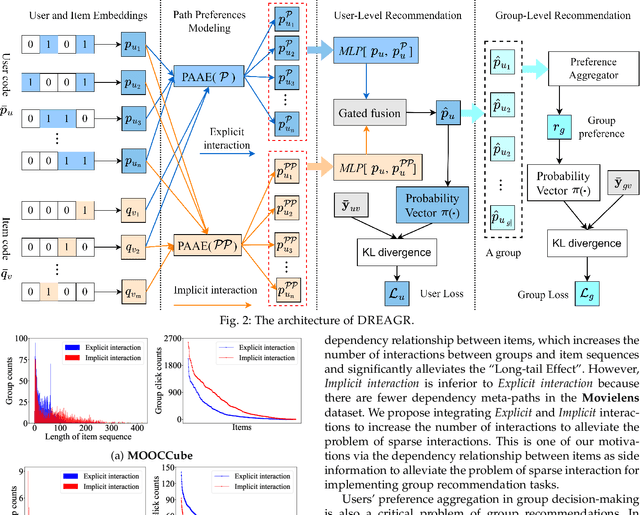

Recommending suitable items to a group of users, commonly referred to as the group recommendation task, is becoming increasingly urgent with the development of group activities. The challenges within the group recommendation task involve aggregating the individual preferences of group members as the group's preferences and facing serious sparsity problems due to the lack of user/group-item interactions. To solve these problems, we propose a novel approach called Dependency Relationships-Enhanced Attentive Group Recommendation (DREAGR) for the recommendation task of occasional groups. Specifically, we introduce the dependency relationship between items as side information to enhance the user/group-item interaction and alleviate the interaction sparsity problem. Then, we propose a Path-Aware Attention Embedding (PAAE) method to model users' preferences on different types of paths. Next, we design a gated fusion mechanism to fuse users' preferences into their comprehensive preferences. Finally, we develop an attention aggregator that aggregates users' preferences as the group's preferences for the group recommendation task. We conducted experiments on two datasets to demonstrate the superiority of DREAGR by comparing it with state-of-the-art group recommender models. The experimental results show that DREAGR outperforms other models, especially HR@N and NDCG@N (N=5, 10), where DREAGR has improved in the range of 3.64% to 7.01% and 2.57% to 3.39% on both datasets, respectively.
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
Aug 15, 2023



We present the content deformation field CoDeF as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis.Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline.We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video.With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field.We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training.More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to track non-rigid objects like water and smog.Project page can be found at https://qiuyu96.github.io/CoDeF/.
Elastically-Constrained Meta-Learner for Federated Learning
Jun 30, 2023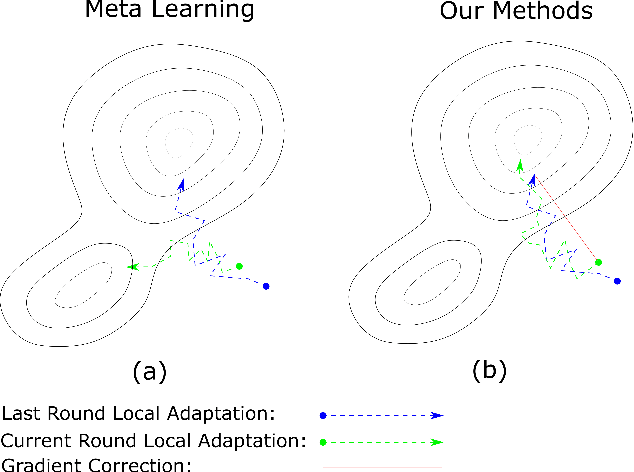
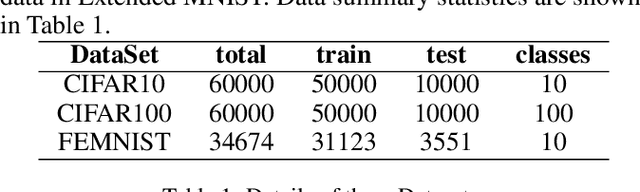
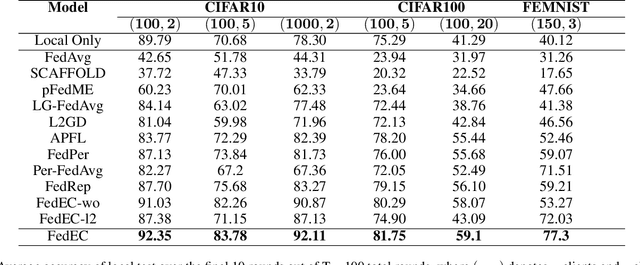
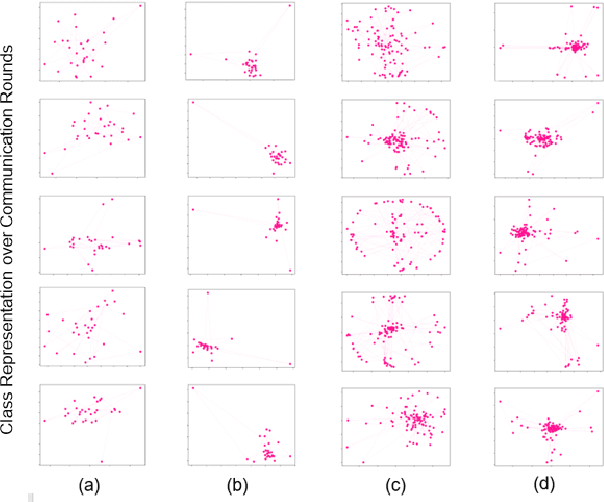
Federated learning is an approach to collaboratively training machine learning models for multiple parties that prohibit data sharing. One of the challenges in federated learning is non-IID data between clients, as a single model can not fit the data distribution for all clients. Meta-learning, such as Per-FedAvg, is introduced to cope with the challenge. Meta-learning learns shared initial parameters for all clients. Each client employs gradient descent to adapt the initialization to local data distributions quickly to realize model personalization. However, due to non-convex loss function and randomness of sampling update, meta-learning approaches have unstable goals in local adaptation for the same client. This fluctuation in different adaptation directions hinders the convergence in meta-learning. To overcome this challenge, we use the historical local adapted model to restrict the direction of the inner loop and propose an elastic-constrained method. As a result, the current round inner loop keeps historical goals and adapts to better solutions. Experiments show our method boosts meta-learning convergence and improves personalization without additional calculation and communication. Our method achieved SOTA on all metrics in three public datasets.