 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphusion: A RAG Framework for Knowledge Graph Construction with a Global Perspective
Oct 23, 2024



Knowledge Graphs (KGs) are crucial in the field of artificial intelligence and are widely used in downstream tasks, such as question-answering (QA). The construction of KGs typically requires significant effort from domain experts. Large Language Models (LLMs) have recently been used for Knowledge Graph Construction (KGC). However, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents, missing a fusion process to combine the knowledge in a global KG. This work introduces Graphusion, a zero-shot KGC framework from free text. It contains three steps: in Step 1, we extract a list of seed entities using topic modeling to guide the final KG includes the most relevant entities; in Step 2, we conduct candidate triplet extraction using LLMs; in Step 3, we design the novel fusion module that provides a global view of the extracted knowledge, incorporating entity merging, conflict resolution, and novel triplet discovery. Results show that Graphusion achieves scores of 2.92 and 2.37 out of 3 for entity extraction and relation recognition, respectively. Moreover, we showcase how Graphusion could be applied to the Natural Language Processing (NLP) domain and validate it in an educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for QA, comprising six tasks and a total of 1,200 QA pairs. Using the Graphusion-constructed KG, we achieve a significant improvement on the benchmark, for example, a 9.2% accuracy improvement on sub-graph completion.
Transformers4NewsRec: A Transformer-based News Recommendation Framework
Oct 17, 2024



Pre-trained transformer models have shown great promise in various natural language processing tasks, including personalized news recommendations. To harness the power of these models, we introduce Transformers4NewsRec, a new Python framework built on the \textbf{Transformers} library. This framework is designed to unify and compare the performance of various news recommendation models, including deep neural networks and graph-based models. Transformers4NewsRec offers flexibility in terms of model selection, data preprocessing, and evaluation, allowing both quantitative and qualitative analysis.
AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data
Oct 15, 2024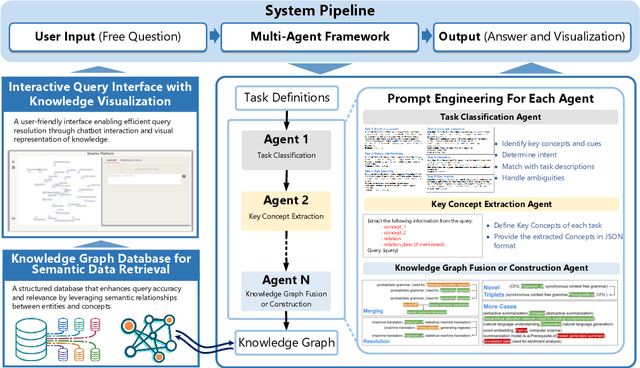
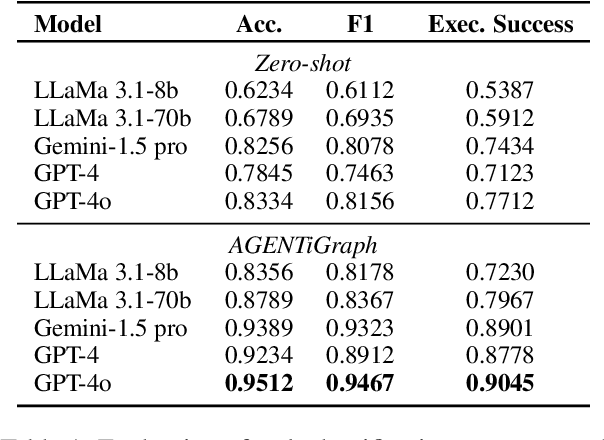
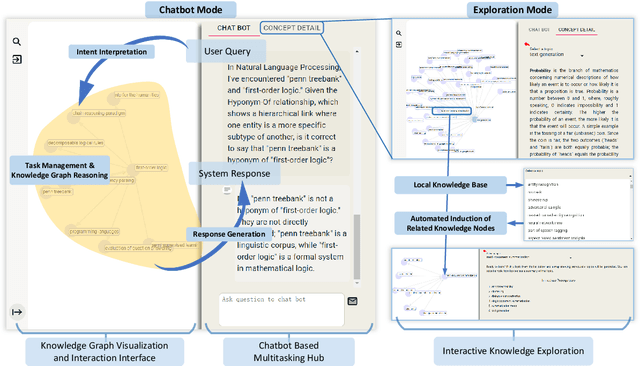
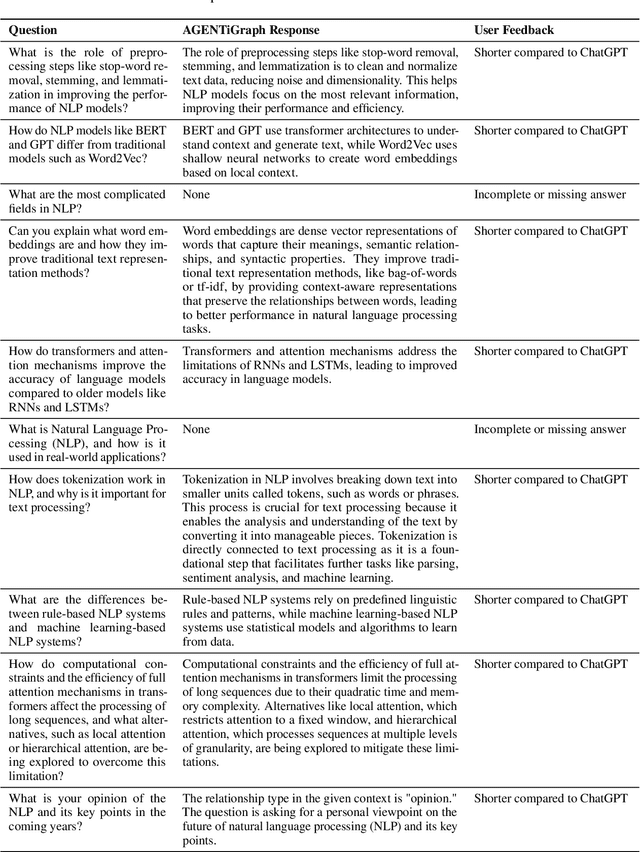
Large Language Models~(LLMs) have demonstrated capabilities across various applications but face challenges such as hallucination, limited reasoning abilities, and factual inconsistencies, especially when tackling complex, domain-specific tasks like question answering~(QA). While Knowledge Graphs~(KGs) have been shown to help mitigate these issues, research on the integration of LLMs with background KGs remains limited. In particular, user accessibility and the flexibility of the underlying KG have not been thoroughly explored. We introduce AGENTiGraph (Adaptive Generative ENgine for Task-based Interaction and Graphical Representation), a platform for knowledge management through natural language interaction. It integrates knowledge extraction, integration, and real-time visualization. AGENTiGraph employs a multi-agent architecture to dynamically interpret user intents, manage tasks, and integrate new knowledge, ensuring adaptability to evolving user requirements and data contexts. Our approach demonstrates superior performance in knowledge graph interactions, particularly for complex domain-specific tasks. Experimental results on a dataset of 3,500 test cases show AGENTiGraph significantly outperforms state-of-the-art zero-shot baselines, achieving 95.12\% accuracy in task classification and 90.45\% success rate in task execution. User studies corroborate its effectiveness in real-world scenarios. To showcase versatility, we extended AGENTiGraph to legislation and healthcare domains, constructing specialized KGs capable of answering complex queries in legal and medical contexts.
Graphusion: Leveraging Large Language Models for Scientific Knowledge Graph Fusion and Construction in NLP Education
Jul 15, 2024



Knowledge graphs (KGs) are crucial in the field of artificial intelligence and are widely applied in downstream tasks, such as enhancing Question Answering (QA) systems. The construction of KGs typically requires significant effort from domain experts. Recently, Large Language Models (LLMs) have been used for knowledge graph construction (KGC), however, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents. In this work, we introduce Graphusion, a zero-shot KGC framework from free text. The core fusion module provides a global view of triplets, incorporating entity merging, conflict resolution, and novel triplet discovery. We showcase how Graphusion could be applied to the natural language processing (NLP) domain and validate it in the educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for graph reasoning and QA, comprising six tasks and a total of 1,200 QA pairs. Our evaluation demonstrates that Graphusion surpasses supervised baselines by up to 10% in accuracy on link prediction. Additionally, it achieves average scores of 2.92 and 2.37 out of 3 in human evaluations for concept entity extraction and relation recognition, respectively.
Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education
Feb 22, 2024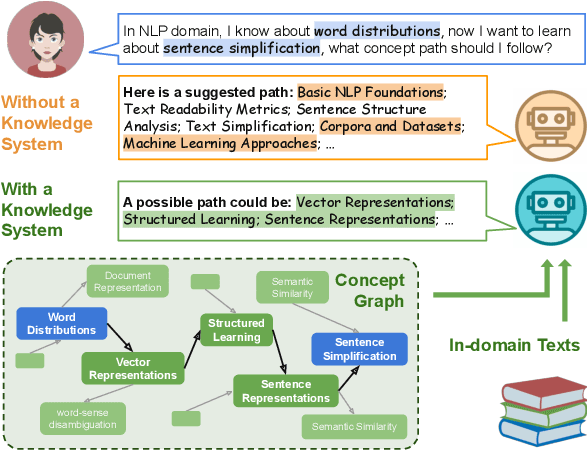
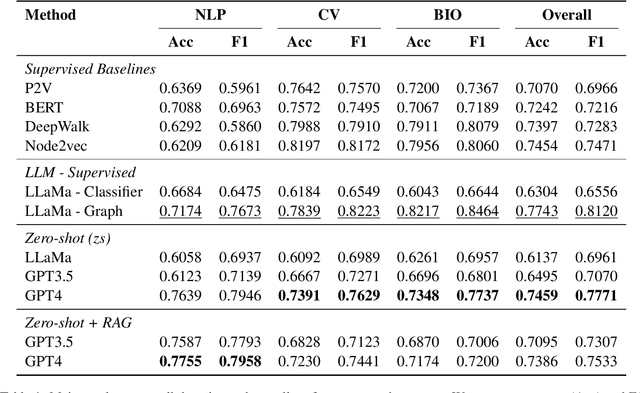
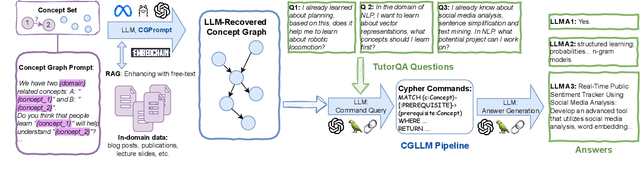

In the domain of Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated promise in text-generation tasks. However, their educational applications, particularly for domain-specific queries, remain underexplored. This study investigates LLMs' capabilities in educational scenarios, focusing on concept graph recovery and question-answering (QA). We assess LLMs' zero-shot performance in creating domain-specific concept graphs and introduce TutorQA, a new expert-verified NLP-focused benchmark for scientific graph reasoning and QA. TutorQA consists of five tasks with 500 QA pairs. To tackle TutorQA queries, we present CGLLM, a pipeline integrating concept graphs with LLMs for answering diverse questions. Our results indicate that LLMs' zero-shot concept graph recovery is competitive with supervised methods, showing an average 3% F1 score improvement. In TutorQA tasks, LLMs achieve up to 26% F1 score enhancement. Moreover, human evaluation and analysis show that CGLLM generates answers with more fine-grained concepts.
RecPrompt: A Prompt Tuning Framework for News Recommendation Using Large Language Models
Dec 16, 2023



In the evolving field of personalized news recommendation, understanding the semantics of the underlying data is crucial. Large Language Models (LLMs) like GPT-4 have shown promising performance in understanding natural language. However, the extent of their applicability in news recommendation systems remains to be validated. This paper introduces RecPrompt, the first framework for news recommendation that leverages the capabilities of LLMs through prompt engineering. This system incorporates a prompt optimizer that applies an iterative bootstrapping process, enhancing the LLM-based recommender's ability to align news content with user preferences and interests more effectively. Moreover, this study offers insights into the effective use of LLMs in news recommendation, emphasizing both the advantages and the challenges of incorporating LLMs into recommendation systems.
Going Beyond Local: Global Graph-Enhanced Personalized News Recommendations
Jul 31, 2023



Precisely recommending candidate news articles to users has always been a core challenge for personalized news recommendation systems. Most recent works primarily focus on using advanced natural language processing techniques to extract semantic information from rich textual data, employing content-based methods derived from local historical news. However, this approach lacks a global perspective, failing to account for users' hidden motivations and behaviors beyond semantic information. To address this challenge, we propose a novel model called GLORY (Global-LOcal news Recommendation sYstem), which combines global representations learned from other users with local representations to enhance personalized recommendation systems. We accomplish this by constructing a Global-aware Historical News Encoder, which includes a global news graph and employs gated graph neural networks to enrich news representations, thereby fusing historical news representations by a historical news aggregator. Similarly, we extend this approach to a Global Candidate News Encoder, utilizing a global entity graph and a candidate news aggregator to enhance candidate news representation. Evaluation results on two public news datasets demonstrate that our method outperforms existing approaches. Furthermore, our model offers more diverse recommendations.
XDLM: Cross-lingual Diffusion Language Model for Machine Translation
Jul 31, 2023



Recently, diffusion models have excelled in image generation tasks and have also been applied to neural language processing (NLP) for controllable text generation. However, the application of diffusion models in a cross-lingual setting is less unexplored. Additionally, while pretraining with diffusion models has been studied within a single language, the potential of cross-lingual pretraining remains understudied. To address these gaps, we propose XDLM, a novel Cross-lingual diffusion model for machine translation, consisting of pretraining and fine-tuning stages. In the pretraining stage, we propose TLDM, a new training objective for mastering the mapping between different languages; in the fine-tuning stage, we build up the translation system based on the pretrained model. We evaluate the result on several machine translation benchmarks and outperformed both diffusion and Transformer baselines.
NNKGC: Improving Knowledge Graph Completion with Node Neighborhoods
Feb 13, 2023



Knowledge graph completion (KGC) aims to discover missing relations of query entities. Current text-based models utilize the entity name and description to infer the tail entity given the head entity and a certain relation. Existing approaches also consider the neighborhood of the head entity. However, these methods tend to model the neighborhood using a flat structure and are only restricted to 1-hop neighbors. In this work, we propose a node neighborhood-enhanced framework for knowledge graph completion. It models the head entity neighborhood from multiple hops using graph neural networks to enrich the head node information. Moreover, we introduce an additional edge link prediction task to improve KGC. Evaluation on two public datasets shows that this framework is simple yet effective. The case study also shows that the model is able to predict explainable predictions.