 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathVLM-R1: A Reinforcement Learning-Driven Reasoning Model for Pathology Visual-Language Tasks
Apr 12, 2025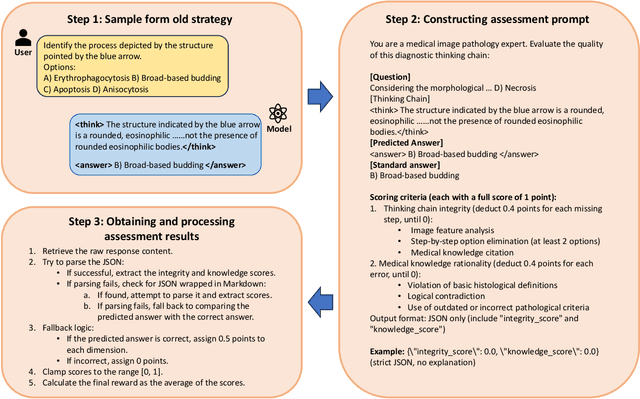
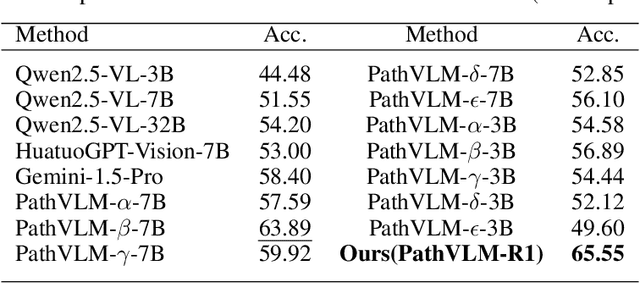
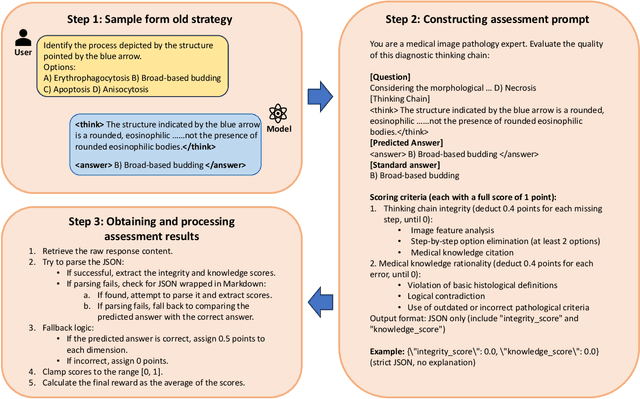

The diagnosis of pathological images is often limited by expert availability and regional disparities, highlighting the importance of automated diagnosis using Vision-Language Models (VLMs). Traditional multimodal models typically emphasize outcomes over the reasoning process, compromising the reliability of clinical decisions. To address the weak reasoning abilities and lack of supervised processes in pathological VLMs, we have innovatively proposed PathVLM-R1, a visual language model designed specifically for pathological images. We have based our model on Qwen2.5-VL-7B-Instruct and enhanced its performance for pathological tasks through meticulously designed post-training strategies. Firstly, we conduct supervised fine-tuning guided by pathological data to imbue the model with foundational pathological knowledge, forming a new pathological base model. Subsequently, we introduce Group Relative Policy Optimization (GRPO) and propose a dual reward-driven reinforcement learning optimization, ensuring strict constraint on logical supervision of the reasoning process and accuracy of results via cross-modal process reward and outcome accuracy reward. In the pathological image question-answering tasks, the testing results of PathVLM-R1 demonstrate a 14% improvement in accuracy compared to baseline methods, and it demonstrated superior performance compared to the Qwen2.5-VL-32B version despite having a significantly smaller parameter size. Furthermore, in out-domain data evaluation involving four medical imaging modalities: Computed Tomography (CT), dermoscopy, fundus photography, and Optical Coherence Tomography (OCT) images: PathVLM-R1's transfer performance improved by an average of 17.3% compared to traditional SFT methods. These results clearly indicate that PathVLM-R1 not only enhances accuracy but also possesses broad applicability and expansion potential.
XDLM: Cross-lingual Diffusion Language Model for Machine Translation
Jul 31, 2023



Recently, diffusion models have excelled in image generation tasks and have also been applied to neural language processing (NLP) for controllable text generation. However, the application of diffusion models in a cross-lingual setting is less unexplored. Additionally, while pretraining with diffusion models has been studied within a single language, the potential of cross-lingual pretraining remains understudied. To address these gaps, we propose XDLM, a novel Cross-lingual diffusion model for machine translation, consisting of pretraining and fine-tuning stages. In the pretraining stage, we propose TLDM, a new training objective for mastering the mapping between different languages; in the fine-tuning stage, we build up the translation system based on the pretrained model. We evaluate the result on several machine translation benchmarks and outperformed both diffusion and Transformer baselines.
NNKGC: Improving Knowledge Graph Completion with Node Neighborhoods
Feb 13, 2023



Knowledge graph completion (KGC) aims to discover missing relations of query entities. Current text-based models utilize the entity name and description to infer the tail entity given the head entity and a certain relation. Existing approaches also consider the neighborhood of the head entity. However, these methods tend to model the neighborhood using a flat structure and are only restricted to 1-hop neighbors. In this work, we propose a node neighborhood-enhanced framework for knowledge graph completion. It models the head entity neighborhood from multiple hops using graph neural networks to enrich the head node information. Moreover, we introduce an additional edge link prediction task to improve KGC. Evaluation on two public datasets shows that this framework is simple yet effective. The case study also shows that the model is able to predict explainable predictions.