 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathVLM-R1: A Reinforcement Learning-Driven Reasoning Model for Pathology Visual-Language Tasks
Paper and Code
Apr 12, 2025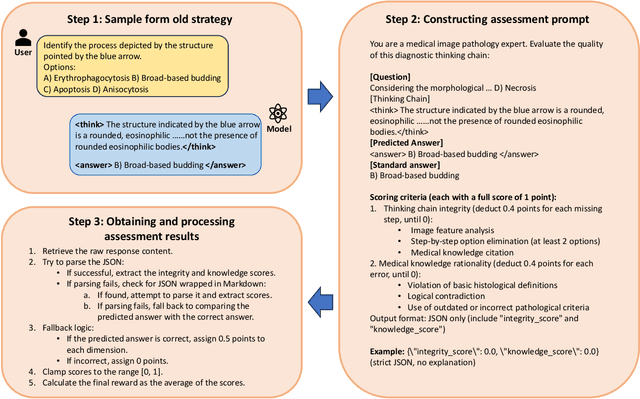
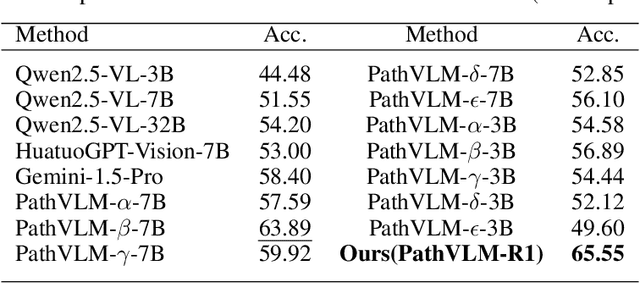
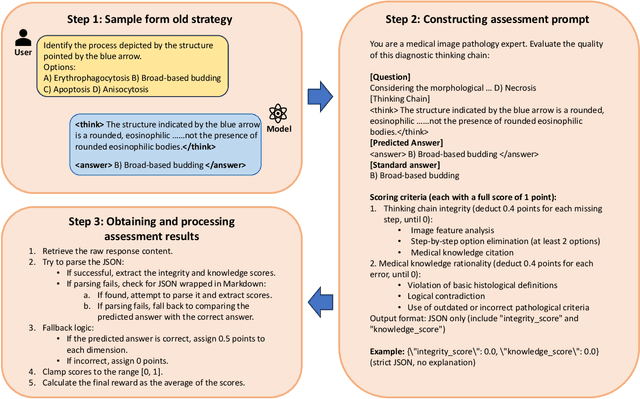

The diagnosis of pathological images is often limited by expert availability and regional disparities, highlighting the importance of automated diagnosis using Vision-Language Models (VLMs). Traditional multimodal models typically emphasize outcomes over the reasoning process, compromising the reliability of clinical decisions. To address the weak reasoning abilities and lack of supervised processes in pathological VLMs, we have innovatively proposed PathVLM-R1, a visual language model designed specifically for pathological images. We have based our model on Qwen2.5-VL-7B-Instruct and enhanced its performance for pathological tasks through meticulously designed post-training strategies. Firstly, we conduct supervised fine-tuning guided by pathological data to imbue the model with foundational pathological knowledge, forming a new pathological base model. Subsequently, we introduce Group Relative Policy Optimization (GRPO) and propose a dual reward-driven reinforcement learning optimization, ensuring strict constraint on logical supervision of the reasoning process and accuracy of results via cross-modal process reward and outcome accuracy reward. In the pathological image question-answering tasks, the testing results of PathVLM-R1 demonstrate a 14% improvement in accuracy compared to baseline methods, and it demonstrated superior performance compared to the Qwen2.5-VL-32B version despite having a significantly smaller parameter size. Furthermore, in out-domain data evaluation involving four medical imaging modalities: Computed Tomography (CT), dermoscopy, fundus photography, and Optical Coherence Tomography (OCT) images: PathVLM-R1's transfer performance improved by an average of 17.3% compared to traditional SFT methods. These results clearly indicate that PathVLM-R1 not only enhances accuracy but also possesses broad applicability and expansion potential.