 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciIF: Benchmarking Scientific Instruction Following Towards Rigorous Scientific Intelligence
Jan 08, 2026As large language models (LLMs) transition from general knowledge retrieval to complex scientific discovery, their evaluation standards must also incorporate the rigorous norms of scientific inquiry. Existing benchmarks exhibit a critical blind spot: general instruction-following metrics focus on superficial formatting, while domain-specific scientific benchmarks assess only final-answer correctness, often rewarding models that arrive at the right result with the wrong reasons. To address this gap, we introduce scientific instruction following: the capability to solve problems while strictly adhering to the constraints that establish scientific validity. Specifically, we introduce SciIF, a multi-discipline benchmark that evaluates this capability by pairing university-level problems with a fixed catalog of constraints across three pillars: scientific conditions (e.g., boundary checks and assumptions), semantic stability (e.g., unit and symbol conventions), and specific processes(e.g., required numerical methods). Uniquely, SciIF emphasizes auditability, requiring models to provide explicit evidence of constraint satisfaction rather than implicit compliance. By measuring both solution correctness and multi-constraint adherence, SciIF enables finegrained diagnosis of compositional reasoning failures, ensuring that LLMs can function as reliable agents within the strict logical frameworks of science.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
CMT: A Cascade MAR with Topology Predictor for Multimodal Conditional CAD Generation
Apr 29, 2025While accurate and user-friendly Computer-Aided Design (CAD) is crucial for industrial design and manufacturing, existing methods still struggle to achieve this due to their over-simplified representations or architectures incapable of supporting multimodal design requirements. In this paper, we attempt to tackle this problem from both methods and datasets aspects. First, we propose a cascade MAR with topology predictor (CMT), the first multimodal framework for CAD generation based on Boundary Representation (B-Rep). Specifically, the cascade MAR can effectively capture the ``edge-counters-surface'' priors that are essential in B-Reps, while the topology predictor directly estimates topology in B-Reps from the compact tokens in MAR. Second, to facilitate large-scale training, we develop a large-scale multimodal CAD dataset, mmABC, which includes over 1.3 million B-Rep models with multimodal annotations, including point clouds, text descriptions, and multi-view images. Extensive experiments show the superior of CMT in both conditional and unconditional CAD generation tasks. For example, we improve Coverage and Valid ratio by +10.68% and +10.3%, respectively, compared to state-of-the-art methods on ABC in unconditional generation. CMT also improves +4.01 Chamfer on image conditioned CAD generation on mmABC. The dataset, code and pretrained network shall be released.
PathVLM-R1: A Reinforcement Learning-Driven Reasoning Model for Pathology Visual-Language Tasks
Apr 12, 2025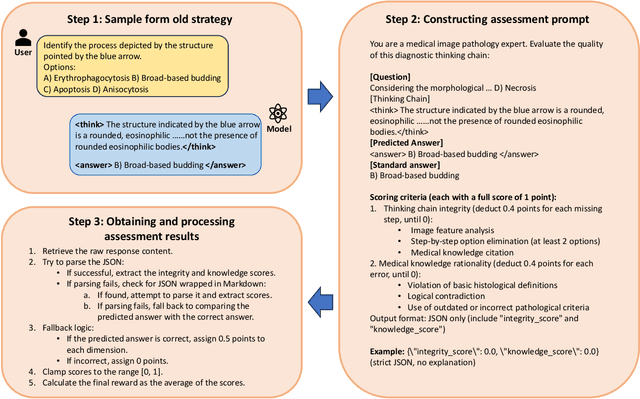
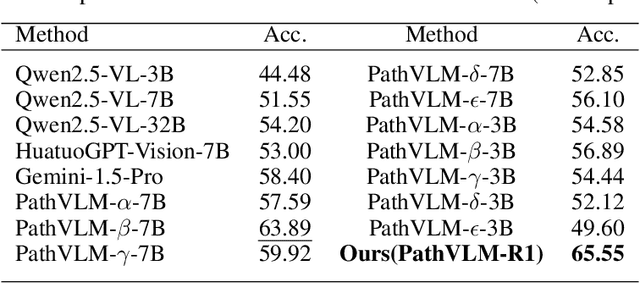
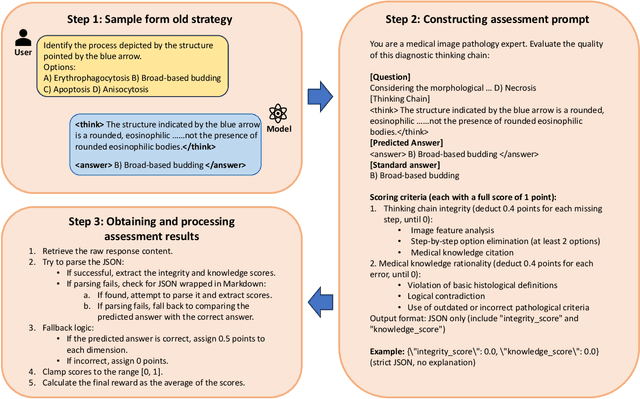

The diagnosis of pathological images is often limited by expert availability and regional disparities, highlighting the importance of automated diagnosis using Vision-Language Models (VLMs). Traditional multimodal models typically emphasize outcomes over the reasoning process, compromising the reliability of clinical decisions. To address the weak reasoning abilities and lack of supervised processes in pathological VLMs, we have innovatively proposed PathVLM-R1, a visual language model designed specifically for pathological images. We have based our model on Qwen2.5-VL-7B-Instruct and enhanced its performance for pathological tasks through meticulously designed post-training strategies. Firstly, we conduct supervised fine-tuning guided by pathological data to imbue the model with foundational pathological knowledge, forming a new pathological base model. Subsequently, we introduce Group Relative Policy Optimization (GRPO) and propose a dual reward-driven reinforcement learning optimization, ensuring strict constraint on logical supervision of the reasoning process and accuracy of results via cross-modal process reward and outcome accuracy reward. In the pathological image question-answering tasks, the testing results of PathVLM-R1 demonstrate a 14% improvement in accuracy compared to baseline methods, and it demonstrated superior performance compared to the Qwen2.5-VL-32B version despite having a significantly smaller parameter size. Furthermore, in out-domain data evaluation involving four medical imaging modalities: Computed Tomography (CT), dermoscopy, fundus photography, and Optical Coherence Tomography (OCT) images: PathVLM-R1's transfer performance improved by an average of 17.3% compared to traditional SFT methods. These results clearly indicate that PathVLM-R1 not only enhances accuracy but also possesses broad applicability and expansion potential.
LLMCBench: Benchmarking Large Language Model Compression for Efficient Deployment
Oct 28, 2024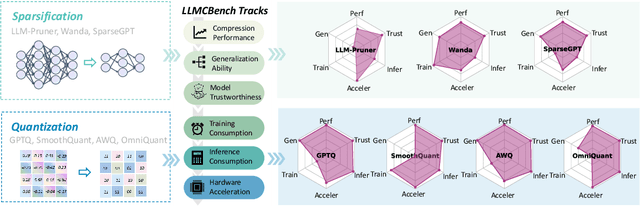
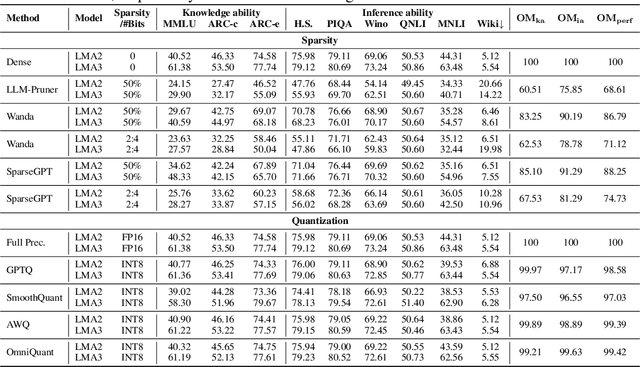
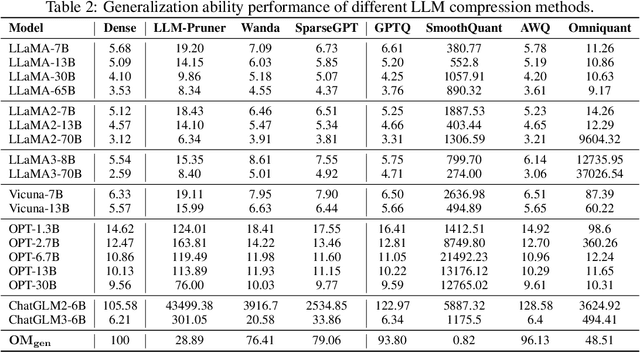
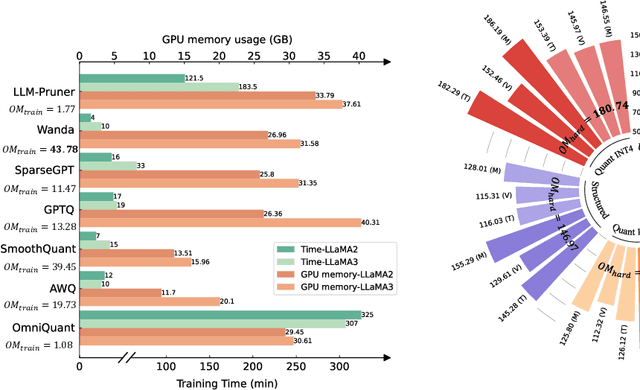
Although large language models (LLMs) have demonstrated their strong intelligence ability, the high demand for computation and storage hinders their practical application. To this end, many model compression techniques are proposed to increase the efficiency of LLMs. However, current researches only validate their methods on limited models, datasets, metrics, etc, and still lack a comprehensive evaluation under more general scenarios. So it is still a question of which model compression approach we should use under a specific case. To mitigate this gap, we present the Large Language Model Compression Benchmark (LLMCBench), a rigorously designed benchmark with an in-depth analysis for LLM compression algorithms. We first analyze the actual model production requirements and carefully design evaluation tracks and metrics. Then, we conduct extensive experiments and comparison using multiple mainstream LLM compression approaches. Finally, we perform an in-depth analysis based on the evaluation and provide useful insight for LLM compression design. We hope our LLMCBench can contribute insightful suggestions for LLM compression algorithm design and serve as a foundation for future research. Our code is available at https://github.com/AboveParadise/LLMCBench.