 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Control Map Distribution using Map Query Bank for Online Map Generation
Apr 04, 2025Reliable autonomous driving systems require high-definition (HD) map that contains detailed map information for planning and navigation. However, pre-build HD map requires a large cost. Visual-based Online Map Generation (OMG) has become an alternative low-cost solution to build a local HD map. Query-based BEV Transformer has been a base model for this task. This model learns HD map predictions from an initial map queries distribution which is obtained by offline optimization on training set. Besides the quality of BEV feature, the performance of this model also highly relies on the capacity of initial map query distribution. However, this distribution is limited because the limited query number. To make map predictions optimal on each test sample, it is essential to generate a suitable initial distribution for each specific scenario. This paper proposes to decompose the whole HD map distribution into a set of point representations, namely map query bank (MQBank). To build specific map query initial distributions of different scenarios, low-cost standard definition map (SD map) data is introduced as a kind of prior knowledge. Moreover, each layer of map decoder network learns instance-level map query features, which will lose detailed information of each point. However, BEV feature map is a point-level dense feature. It is important to keep point-level information in map queries when interacting with BEV feature map. This can also be solved with map query bank method. Final experiments show a new insight on SD map prior and a new record on OpenLaneV2 benchmark with 40.5%, 45.7% mAP on vehicle lane and pedestrian area.
Mamba-3D as Masked Autoencoders for Accurate and Data-Efficient Analysis of Medical Ultrasound Videos
Mar 26, 2025Ultrasound videos are an important form of clinical imaging data, and deep learning-based automated analysis can improve diagnostic accuracy and clinical efficiency. However, the scarcity of labeled data and the inherent challenges of video analysis have impeded the advancement of related methods. In this work, we introduce E-ViM$^3$, a data-efficient Vision Mamba network that preserves the 3D structure of video data, enhancing long-range dependencies and inductive biases to better model space-time correlations. With our design of Enclosure Global Tokens (EGT), the model captures and aggregates global features more effectively than competing methods. To further improve data efficiency, we employ masked video modeling for self-supervised pre-training, with the proposed Spatial-Temporal Chained (STC) masking strategy designed to adapt to various video scenarios. Experiments demonstrate that E-ViM$^3$ performs as the state-of-the-art in two high-level semantic analysis tasks across four datasets of varying sizes: EchoNet-Dynamic, CAMUS, MICCAI-BUV, and WHBUS. Furthermore, our model achieves competitive performance with limited labels, highlighting its potential impact on real-world clinical applications.
Humanoid Policy ~ Human Policy
Mar 17, 2025Training manipulation policies for humanoid robots with diverse data enhances their robustness and generalization across tasks and platforms. However, learning solely from robot demonstrations is labor-intensive, requiring expensive tele-operated data collection which is difficult to scale. This paper investigates a more scalable data source, egocentric human demonstrations, to serve as cross-embodiment training data for robot learning. We mitigate the embodiment gap between humanoids and humans from both the data and modeling perspectives. We collect an egocentric task-oriented dataset (PH2D) that is directly aligned with humanoid manipulation demonstrations. We then train a human-humanoid behavior policy, which we term Human Action Transformer (HAT). The state-action space of HAT is unified for both humans and humanoid robots and can be differentiably retargeted to robot actions. Co-trained with smaller-scale robot data, HAT directly models humanoid robots and humans as different embodiments without additional supervision. We show that human data improves both generalization and robustness of HAT with significantly better data collection efficiency. Code and data: https://human-as-robot.github.io/
MRS: A Fast Sampler for Mean Reverting Diffusion based on ODE and SDE Solvers
Feb 11, 2025In applications of diffusion models, controllable generation is of practical significance, but is also challenging. Current methods for controllable generation primarily focus on modifying the score function of diffusion models, while Mean Reverting (MR) Diffusion directly modifies the structure of the stochastic differential equation (SDE), making the incorporation of image conditions simpler and more natural. However, current training-free fast samplers are not directly applicable to MR Diffusion. And thus MR Diffusion requires hundreds of NFEs (number of function evaluations) to obtain high-quality samples. In this paper, we propose a new algorithm named MRS (MR Sampler) to reduce the sampling NFEs of MR Diffusion. We solve the reverse-time SDE and the probability flow ordinary differential equation (PF-ODE) associated with MR Diffusion, and derive semi-analytical solutions. The solutions consist of an analytical function and an integral parameterized by a neural network. Based on this solution, we can generate high-quality samples in fewer steps. Our approach does not require training and supports all mainstream parameterizations, including noise prediction, data prediction and velocity prediction. Extensive experiments demonstrate that MR Sampler maintains high sampling quality with a speedup of 10 to 20 times across ten different image restoration tasks. Our algorithm accelerates the sampling procedure of MR Diffusion, making it more practical in controllable generation.
ExBody2: Advanced Expressive Humanoid Whole-Body Control
Dec 17, 2024This paper enables real-world humanoid robots to maintain stability while performing expressive motions like humans do. We propose ExBody2, a generalized whole-body tracking framework that can take any reference motion inputs and control the humanoid to mimic the motion. The model is trained in simulation with Reinforcement Learning and then transferred to the real world. It decouples keypoint tracking with velocity control, and effectively leverages a privileged teacher policy to distill precise mimic skills into the target student policy, which enables high-fidelity replication of dynamic movements such as running, crouching, dancing, and other challenging motions. We present a comprehensive qualitative and quantitative analysis of crucial design factors in the paper. We conduct our experiments on two humanoid platforms and demonstrate the superiority of our approach against state-of-the-arts, providing practical guidelines to pursue the extreme of whole-body control for humanoid robots.
Mobile-TeleVision: Predictive Motion Priors for Humanoid Whole-Body Control
Dec 10, 2024



Humanoid robots require both robust lower-body locomotion and precise upper-body manipulation. While recent Reinforcement Learning (RL) approaches provide whole-body loco-manipulation policies, they lack precise manipulation with high DoF arms. In this paper, we propose decoupling upper-body control from locomotion, using inverse kinematics (IK) and motion retargeting for precise manipulation, while RL focuses on robust lower-body locomotion. We introduce PMP (Predictive Motion Priors), trained with Conditional Variational Autoencoder (CVAE) to effectively represent upper-body motions. The locomotion policy is trained conditioned on this upper-body motion representation, ensuring that the system remains robust with both manipulation and locomotion. We show that CVAE features are crucial for stability and robustness, and significantly outperforms RL-based whole-body control in precise manipulation. With precise upper-body motion and robust lower-body locomotion control, operators can remotely control the humanoid to walk around and explore different environments, while performing diverse manipulation tasks.
WildLMa: Long Horizon Loco-Manipulation in the Wild
Nov 22, 2024



`In-the-wild' mobile manipulation aims to deploy robots in diverse real-world environments, which requires the robot to (1) have skills that generalize across object configurations; (2) be capable of long-horizon task execution in diverse environments; and (3) perform complex manipulation beyond pick-and-place. Quadruped robots with manipulators hold promise for extending the workspace and enabling robust locomotion, but existing results do not investigate such a capability. This paper proposes WildLMa with three components to address these issues: (1) adaptation of learned low-level controller for VR-enabled whole-body teleoperation and traversability; (2) WildLMa-Skill -- a library of generalizable visuomotor skills acquired via imitation learning or heuristics and (3) WildLMa-Planner -- an interface of learned skills that allow LLM planners to coordinate skills for long-horizon tasks. We demonstrate the importance of high-quality training data by achieving higher grasping success rate over existing RL baselines using only tens of demonstrations. WildLMa exploits CLIP for language-conditioned imitation learning that empirically generalizes to objects unseen in training demonstrations. Besides extensive quantitative evaluation, we qualitatively demonstrate practical robot applications, such as cleaning up trash in university hallways or outdoor terrains, operating articulated objects, and rearranging items on a bookshelf.
Learning Visual Parkour from Generated Images
Oct 31, 2024


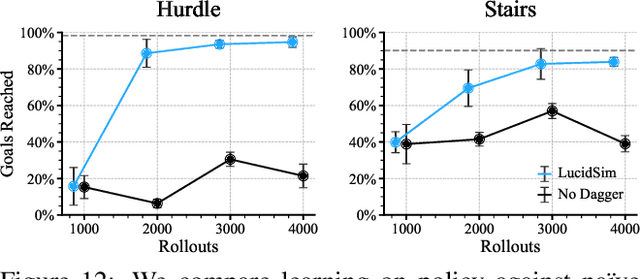
Fast and accurate physics simulation is an essential component of robot learning, where robots can explore failure scenarios that are difficult to produce in the real world and learn from unlimited on-policy data. Yet, it remains challenging to incorporate RGB-color perception into the sim-to-real pipeline that matches the real world in its richness and realism. In this work, we train a robot dog in simulation for visual parkour. We propose a way to use generative models to synthesize diverse and physically accurate image sequences of the scene from the robot's ego-centric perspective. We present demonstrations of zero-shot transfer to the RGB-only observations of the real world on a robot equipped with a low-cost, off-the-shelf color camera. website visit https://lucidsim.github.io
LLMCBench: Benchmarking Large Language Model Compression for Efficient Deployment
Oct 28, 2024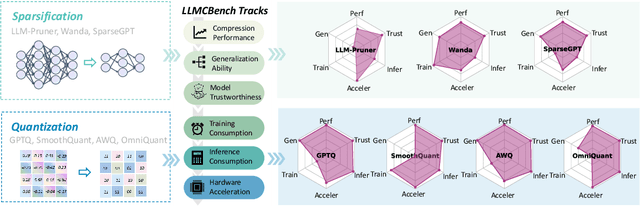
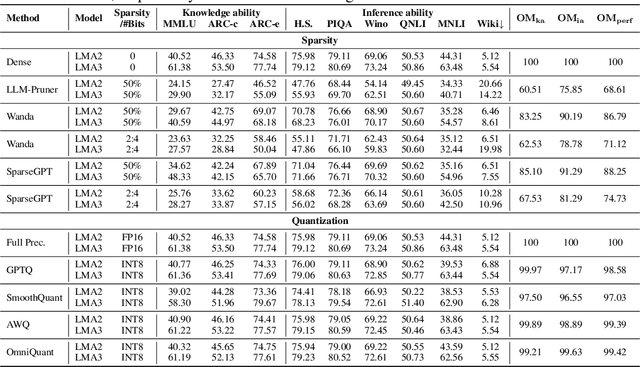
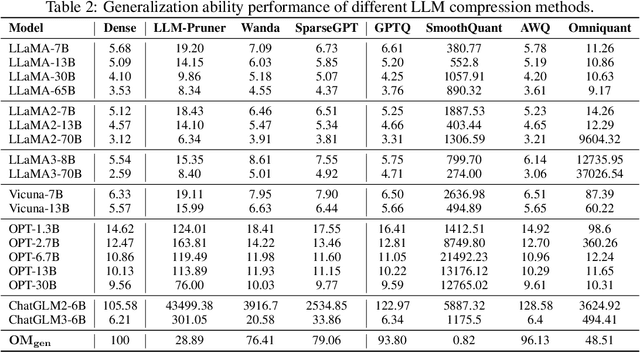
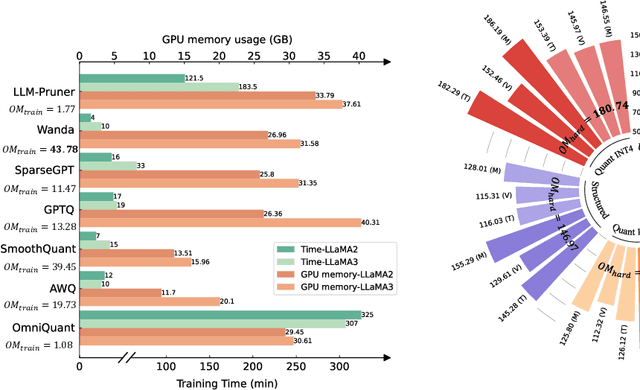
Although large language models (LLMs) have demonstrated their strong intelligence ability, the high demand for computation and storage hinders their practical application. To this end, many model compression techniques are proposed to increase the efficiency of LLMs. However, current researches only validate their methods on limited models, datasets, metrics, etc, and still lack a comprehensive evaluation under more general scenarios. So it is still a question of which model compression approach we should use under a specific case. To mitigate this gap, we present the Large Language Model Compression Benchmark (LLMCBench), a rigorously designed benchmark with an in-depth analysis for LLM compression algorithms. We first analyze the actual model production requirements and carefully design evaluation tracks and metrics. Then, we conduct extensive experiments and comparison using multiple mainstream LLM compression approaches. Finally, we perform an in-depth analysis based on the evaluation and provide useful insight for LLM compression design. We hope our LLMCBench can contribute insightful suggestions for LLM compression algorithm design and serve as a foundation for future research. Our code is available at https://github.com/AboveParadise/LLMCBench.