 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoPhys: Learning Generalizable Physics Models of Deformable Objects from Egocentric Video
Jun 15, 2026Humans naturally understand object physics through everyday interactions, but faithfully predicting complex deformable dynamics, such as elastic materials and fabrics, remains a major challenge for computer vision and robotics. We present EgoPhys, a framework that constructs deformable physical digital twins from egocentric RGB-only video using generalizable priors. EgoPhys overcomes the limitations of existing methods to enable controllable deformable digital twin generation from egocentric videos by distilling per-object inverse-physics solutions into a compact codebook, enabling prediction of dense spring stiffness fields for unseen objects without per-spring test-time optimization. Trained with generalizable priors from diverse egocentric interactions, EgoPhys outperforms baselines in reconstruction, future prediction, and zero-shot generalization. To support training and evaluation, we curate an egocentric interaction dataset covering diverse deformable objects, scenes, and manipulation styles. We deploy EgoPhys on a real xArm6 robot, demonstrating that a digital twin initialized from a single egocentric human play video can serve as an internal world representation to aid in deformable-object planning, highlighting egocentric RGB observations as a scalable path toward real-to-sim pipelines.
ConTrack: Constrained Hand Motion Tracking with Adaptive Trade-off Control
Jun 02, 2026Human demonstrations provide strong priors for robot manipulation, yet it is non-trivial to transfer them to execute on real robots due to the kinematic gap. In dexterous manipulation, it remains challenging to track long-horizon, contact-rich sequences even in simulators: a reference-tracking policy must keep objects on their target trajectories while preserving demonstrated joint motion and contact timing. Existing approaches often rely on hand-crafted reward tuning that require per-sequence tuning and break under limited interaction budgets. We introduce ConTrack, a reinforcement learning (RL) framework that scales with tracking data. ConTrack treats object tracking as a constraint and allocates remaining control authority to motion fidelity, which allows it to adapt task--style trade-offs online using a dual-variable update. In addition, ConTrack also stabilizes long-horizon learning with an adaptive mid-trajectory reset library that reuses policy-reachable simulator states. Our qualitative and quantitative results in simulation tracking and real robot demonstrate that ConTrack improves success and object pose accuracy significantly over prior arts while preserving joint and contact fidelity. Website: https://www.lyt0112.com/projects/ConTrack.
Long-Horizon Manipulation via Trace-Conditioned VLA Planning
Apr 23, 2026Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip
EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Apr 08, 2026Robot learning increasingly depends on large and diverse data, yet robot data collection remains expensive and difficult to scale. Egocentric human data offer a promising alternative by capturing rich manipulation behavior across everyday environments. However, existing human datasets are often limited in scope, difficult to extend, and fragmented across institutions. We introduce EgoVerse, a collaborative platform for human data-driven robot learning that unifies data collection, processing, and access under a shared framework, enabling contributions from individual researchers, academic labs, and industry partners. The current release includes 1,362 hours (80k episodes) of human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 unique demonstrators, with standardized formats, manipulation-relevant annotations, and tooling for downstream learning. Beyond the dataset, we conduct a large-scale study of human-to-robot transfer with experiments replicated across multiple labs, tasks, and robot embodiments under shared protocols. We find that policy performance generally improves with increased human data, but that effective scaling depends on alignment between human data and robot learning objectives. Together, the dataset, platform, and study establish a foundation for reproducible progress in human data-driven robot learning. Videos and additional information can be found at https://egoverse.ai/
In-N-On: Scaling Egocentric Manipulation with in-the-wild and on-task Data
Nov 19, 2025Egocentric videos are a valuable and scalable data source to learn manipulation policies. However, due to significant data heterogeneity, most existing approaches utilize human data for simple pre-training, which does not unlock its full potential. This paper first provides a scalable recipe for collecting and using egocentric data by categorizing human data into two categories: in-the-wild and on-task alongside with systematic analysis on how to use the data. We first curate a dataset, PHSD, which contains over 1,000 hours of diverse in-the-wild egocentric data and over 20 hours of on-task data directly aligned to the target manipulation tasks. This enables learning a large egocentric language-conditioned flow matching policy, Human0. With domain adaptation techniques, Human0 minimizes the gap between humans and humanoids. Empirically, we show Human0 achieves several novel properties from scaling human data, including language following of instructions from only human data, few-shot learning, and improved robustness using on-task data. Project website: https://xiongyicai.github.io/In-N-On/
HMC: Learning Heterogeneous Meta-Control for Contact-Rich Loco-Manipulation
Nov 18, 2025



Learning from real-world robot demonstrations holds promise for interacting with complex real-world environments. However, the complexity and variability of interaction dynamics often cause purely positional controllers to struggle with contacts or varying payloads. To address this, we propose a Heterogeneous Meta-Control (HMC) framework for Loco-Manipulation that adaptively stitches multiple control modalities: position, impedance, and hybrid force-position. We first introduce an interface, HMC-Controller, for blending actions from different control profiles continuously in the torque space. HMC-Controller facilitates both teleoperation and policy deployment. Then, to learn a robust force-aware policy, we propose HMC-Policy to unify different controllers into a heterogeneous architecture. We adopt a mixture-of-experts style routing to learn from large-scale position-only data and fine-grained force-aware demonstrations. Experiments on a real humanoid robot show over 50% relative improvement vs. baselines on challenging tasks such as compliant table wiping and drawer opening, demonstrating the efficacy of HMC.
Gaussian-Augmented Physics Simulation and System Identification with Complex Colliders
Nov 10, 2025

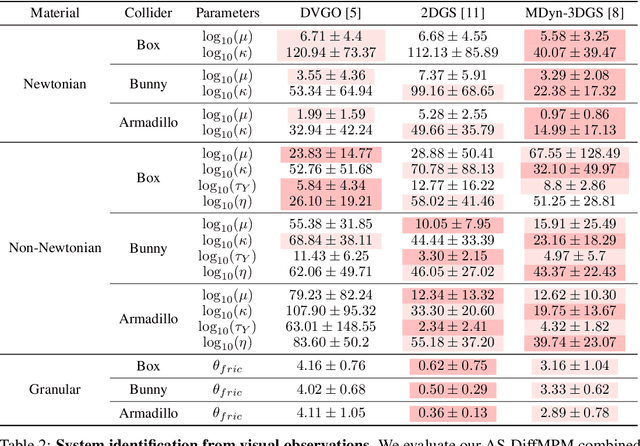

System identification involving the geometry, appearance, and physical properties from video observations is a challenging task with applications in robotics and graphics. Recent approaches have relied on fully differentiable Material Point Method (MPM) and rendering for simultaneous optimization of these properties. However, they are limited to simplified object-environment interactions with planar colliders and fail in more challenging scenarios where objects collide with non-planar surfaces. We propose AS-DiffMPM, a differentiable MPM framework that enables physical property estimation with arbitrarily shaped colliders. Our approach extends existing methods by incorporating a differentiable collision handling mechanism, allowing the target object to interact with complex rigid bodies while maintaining end-to-end optimization. We show AS-DiffMPM can be easily interfaced with various novel view synthesis methods as a framework for system identification from visual observations.
GSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control
May 06, 2025Humanoid robots derive much of their dexterity from hyper-dexterous whole-body movements, enabling tasks that require a large operational workspace: such as picking objects off the ground. However, achieving these capabilities on real humanoids remains challenging due to their high degrees of freedom (DoF) and nonlinear dynamics. We propose Adaptive Motion Optimization (AMO), a framework that integrates sim-to-real reinforcement learning (RL) with trajectory optimization for real-time, adaptive whole-body control. To mitigate distribution bias in motion imitation RL, we construct a hybrid AMO dataset and train a network capable of robust, on-demand adaptation to potentially O.O.D. commands. We validate AMO in simulation and on a 29-DoF Unitree G1 humanoid robot, demonstrating superior stability and an expanded workspace compared to strong baselines. Finally, we show that AMO's consistent performance supports autonomous task execution via imitation learning, underscoring the system's versatility and robustness.
Visual Acoustic Fields
Apr 01, 2025Objects produce different sounds when hit, and humans can intuitively infer how an object might sound based on its appearance and material properties. Inspired by this intuition, we propose Visual Acoustic Fields, a framework that bridges hitting sounds and visual signals within a 3D space using 3D Gaussian Splatting (3DGS). Our approach features two key modules: sound generation and sound localization. The sound generation module leverages a conditional diffusion model, which takes multiscale features rendered from a feature-augmented 3DGS to generate realistic hitting sounds. Meanwhile, the sound localization module enables querying the 3D scene, represented by the feature-augmented 3DGS, to localize hitting positions based on the sound sources. To support this framework, we introduce a novel pipeline for collecting scene-level visual-sound sample pairs, achieving alignment between captured images, impact locations, and corresponding sounds. To the best of our knowledge, this is the first dataset to connect visual and acoustic signals in a 3D context. Extensive experiments on our dataset demonstrate the effectiveness of Visual Acoustic Fields in generating plausible impact sounds and accurately localizing impact sources. Our project page is at https://yuelei0428.github.io/projects/Visual-Acoustic-Fields/.