 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMPM: Embodied MPM for Modeling and Simulation of Deformable Objects
Jan 24, 2026Modeling deformable objects - especially continuum materials - in a way that is physically plausible, generalizable, and data-efficient remains challenging across 3D vision, graphics, and robotic manipulation. Many existing methods oversimplify the rich dynamics of deformable objects or require large training sets, which often limits generalization. We introduce embodied MPM (EMPM), a deformable object modeling and simulation framework built on a differentiable Material Point Method (MPM) simulator that captures the dynamics of challenging materials. From multi-view RGB-D videos, our approach reconstructs geometry and appearance, then uses an MPM physics engine to simulate object behavior by minimizing the mismatch between predicted and observed visual data. We further optimize MPM parameters online using sensory feedback, enabling adaptive, robust, and physics-aware object representations that open new possibilities for robotic manipulation of complex deformables. Experiments show that EMPM outperforms spring-mass baseline models. Project website: https://embodied-mpm.github.io.
GaRLILEO: Gravity-aligned Radar-Leg-Inertial Enhanced Odometry
Nov 17, 2025Deployment of legged robots for navigating challenging terrains (e.g., stairs, slopes, and unstructured environments) has gained increasing preference over wheel-based platforms. In such scenarios, accurate odometry estimation is a preliminary requirement for stable locomotion, localization, and mapping. Traditional proprioceptive approaches, which rely on leg kinematics sensor modalities and inertial sensing, suffer from irrepressible vertical drift caused by frequent contact impacts, foot slippage, and vibrations, particularly affected by inaccurate roll and pitch estimation. Existing methods incorporate exteroceptive sensors such as LiDAR or cameras. Further enhancement has been introduced by leveraging gravity vector estimation to add additional observations on roll and pitch, thereby increasing the accuracy of vertical pose estimation. However, these approaches tend to degrade in feature-sparse or repetitive scenes and are prone to errors from double-integrated IMU acceleration. To address these challenges, we propose GaRLILEO, a novel gravity-aligned continuous-time radar-leg-inertial odometry framework. GaRLILEO decouples velocity from the IMU by building a continuous-time ego-velocity spline from SoC radar Doppler and leg kinematics information, enabling seamless sensor fusion which mitigates odometry distortion. In addition, GaRLILEO can reliably capture accurate gravity vectors leveraging a novel soft S2-constrained gravity factor, improving vertical pose accuracy without relying on LiDAR or cameras. Evaluated on a self-collected real-world dataset with diverse indoor-outdoor trajectories, GaRLILEO demonstrates state-of-the-art accuracy, particularly in vertical odometry estimation on stairs and slopes. We open-source both our dataset and algorithm to foster further research in legged robot odometry and SLAM. https://garlileo.github.io/GaRLILEO
NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
Oct 09, 2025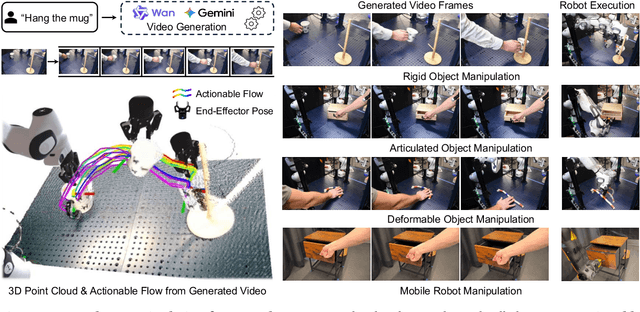
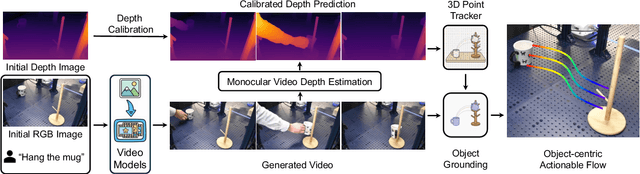


Enabling robots to execute novel manipulation tasks zero-shot is a central goal in robotics. Most existing methods assume in-distribution tasks or rely on fine-tuning with embodiment-matched data, limiting transfer across platforms. We present NovaFlow, an autonomous manipulation framework that converts a task description into an actionable plan for a target robot without any demonstrations. Given a task description, NovaFlow synthesizes a video using a video generation model and distills it into 3D actionable object flow using off-the-shelf perception modules. From the object flow, it computes relative poses for rigid objects and realizes them as robot actions via grasp proposals and trajectory optimization. For deformable objects, this flow serves as a tracking objective for model-based planning with a particle-based dynamics model. By decoupling task understanding from low-level control, NovaFlow naturally transfers across embodiments. We validate on rigid, articulated, and deformable object manipulation tasks using a table-top Franka arm and a Spot quadrupedal mobile robot, and achieve effective zero-shot execution without demonstrations or embodiment-specific training. Project website: https://novaflow.lhy.xyz/.
Learning Generalizable Feature Fields for Mobile Manipulation
Mar 12, 2024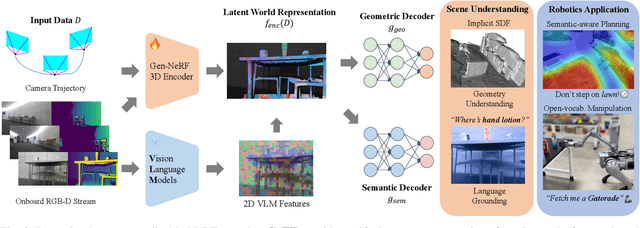


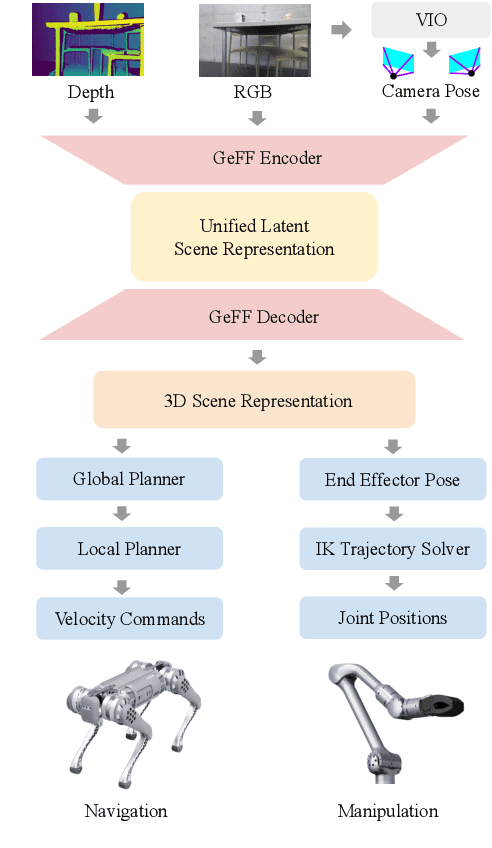
An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understanding fine-grained semantics, whereas the former involves capturing the complexity inherit to an expansive physical scale. In this work, we present GeFF (Generalizable Feature Fields), a scene-level generalizable neural feature field that acts as a unified representation for both navigation and manipulation that performs in real-time. To do so, we treat generative novel view synthesis as a pre-training task, and then align the resulting rich scene priors with natural language via CLIP feature distillation. We demonstrate the effectiveness of this approach by deploying GeFF on a quadrupedal robot equipped with a manipulator. We evaluate GeFF's ability to generalize to open-set objects as well as running time, when performing open-vocabulary mobile manipulation in dynamic scenes.
Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis
Dec 15, 2023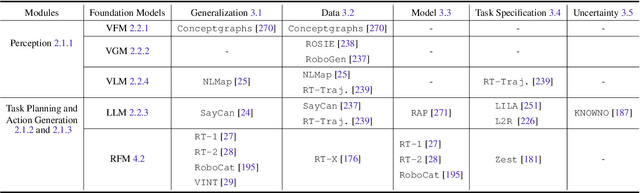

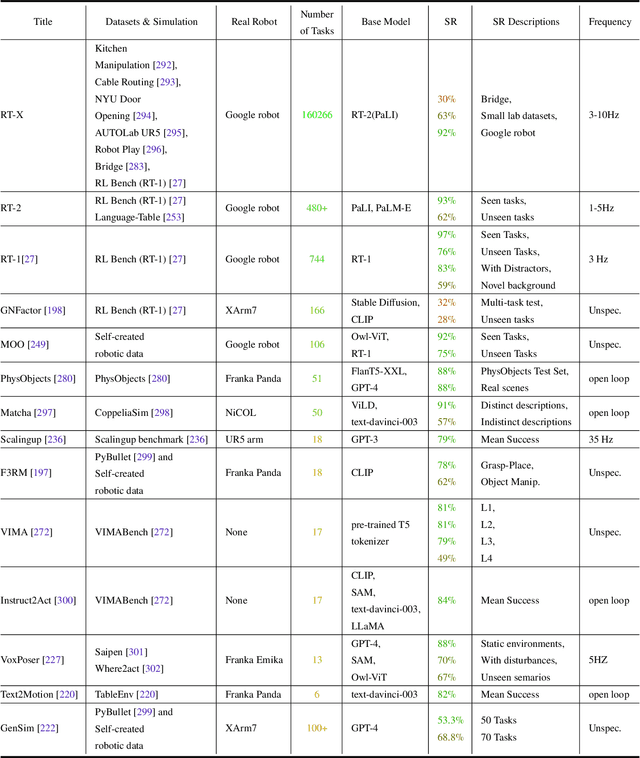
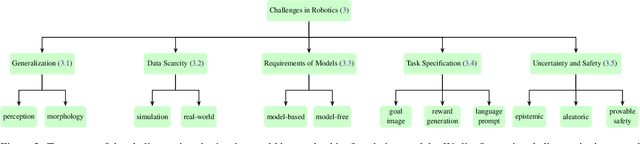
Building general-purpose robots that can operate seamlessly, in any environment, with any object, and utilizing various skills to complete diverse tasks has been a long-standing goal in Artificial Intelligence. Unfortunately, however, most existing robotic systems have been constrained - having been designed for specific tasks, trained on specific datasets, and deployed within specific environments. These systems usually require extensively-labeled data, rely on task-specific models, have numerous generalization issues when deployed in real-world scenarios, and struggle to remain robust to distribution shifts. Motivated by the impressive open-set performance and content generation capabilities of web-scale, large-capacity pre-trained models (i.e., foundation models) in research fields such as Natural Language Processing (NLP) and Computer Vision (CV), we devote this survey to exploring (i) how these existing foundation models from NLP and CV can be applied to the field of robotics, and also exploring (ii) what a robotics-specific foundation model would look like. We begin by providing an overview of what constitutes a conventional robotic system and the fundamental barriers to making it universally applicable. Next, we establish a taxonomy to discuss current work exploring ways to leverage existing foundation models for robotics and develop ones catered to robotics. Finally, we discuss key challenges and promising future directions in using foundation models for enabling general-purpose robotic systems. We encourage readers to view our living GitHub repository of resources, including papers reviewed in this survey as well as related projects and repositories for developing foundation models for robotics.
Learning and Transferring Value Function for Robot Exploration in Subterranean Environments
Apr 07, 2022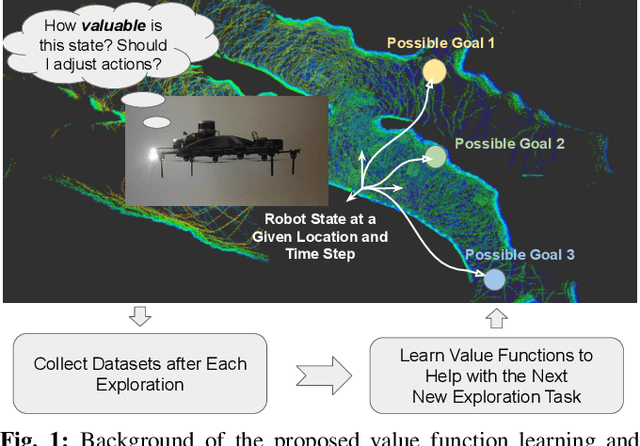
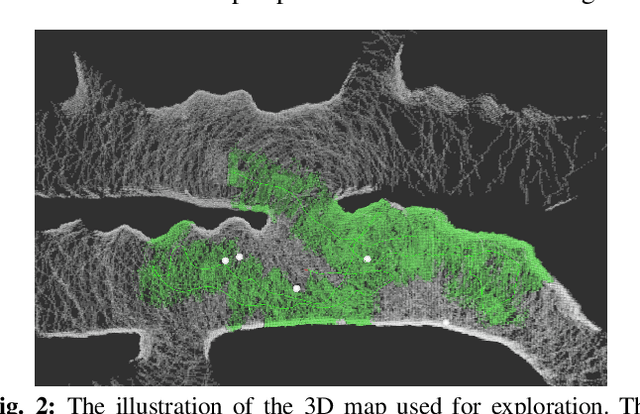

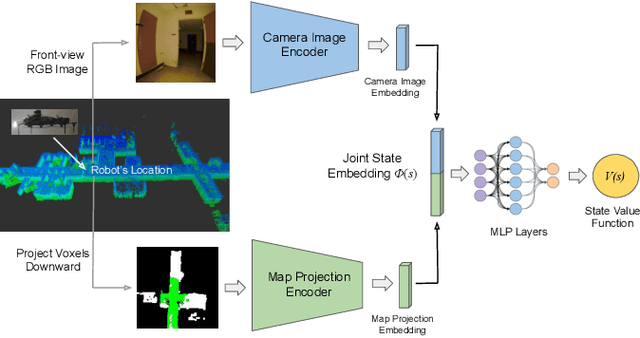
In traditional robot exploration methods, the robot usually does not have prior biases about the environment it is exploring. Thus the robot assigns equal importance to the goals which leads to insufficient exploration efficiency. Alternative, often a hand-tuned policy is used to tweak the value of goals. In this paper, we present a method to learn how "good" some states are, measured by the state value function, to provide a hint for the robot to make exploration decisions. We propose to learn state value functions from previous offline collected datasets and then transfer and improve the value function during testing in a new environment. Moreover, the environments usually have very few and even no extrinsic reward or feedback for the robot. Therefore in this work, we also tackle the problem of sparse extrinsic rewards from the environments. We design several intrinsic rewards to encourage the robot to obtain more information during exploration. These reward functions then become the building blocks of the state value functions. We test our method on challenging subterranean and urban environments. To the best of our knowledge, this work for the first time demonstrates value function prediction with previous collected datasets to help exploration in challenging subterranean environments.
Unsupervised Online Learning for Robotic Interestingness with Visual Memory
Nov 19, 2021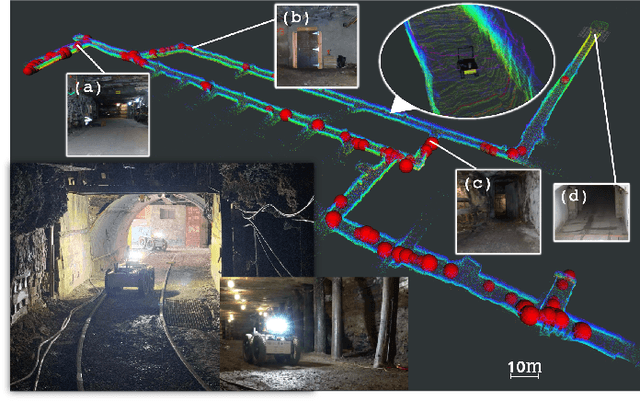


Autonomous robots frequently need to detect "interesting" scenes to decide on further exploration, or to decide which data to share for cooperation. These scenarios often require fast deployment with little or no training data. Prior work considers "interestingness" based on data from the same distribution. Instead, we propose to develop a method that automatically adapts online to the environment to report interesting scenes quickly. To address this problem, we develop a novel translation-invariant visual memory and design a three-stage architecture for long-term, short-term, and online learning, which enables the system to learn human-like experience, environmental knowledge, and online adaption, respectively. With this system, we achieve an average of 20% higher accuracy than the state-of-the-art unsupervised methods in a subterranean tunnel environment. We show comparable performance to supervised methods for robot exploration scenarios showing the efficacy of our approach. We expect that the presented method will play an important role in the robotic interestingness recognition exploration tasks.
Visual Memorability for Robotic Interestingness via Unsupervised Online Learning
May 19, 2020
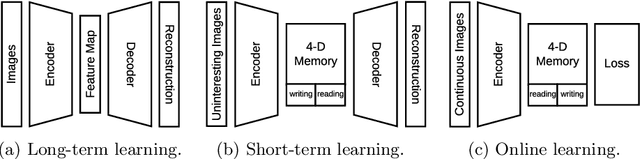
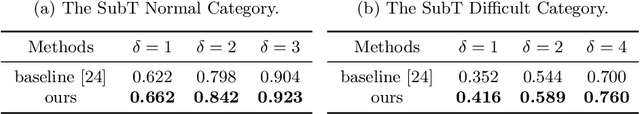
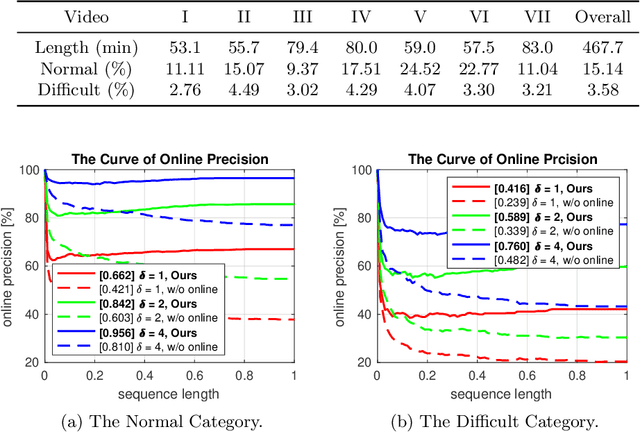
In this paper, we aim to solve the problem of interesting scene prediction for mobile robots. This area is currently under explored but is crucial for many practical applications such as autonomous exploration and decision making. First, we expect a robot to detect novel and interesting scenes in unknown environments and lose interests over time after repeatedly observing similar objects. Second, we expect the robots to learn from unbalanced data in a short time, as the robots normally only know the uninteresting scenes before they are deployed. Inspired by those industrial demands, we first propose a novel translation-invariant visual memory for recalling and identifying interesting scenes, then design a three-stage architecture of long-term, short-term, and online learning for human-like experience, environmental knowledge, and online adaption, respectively. It is demonstrated that our approach is able to learn online and find interesting scenes for practical exploration tasks. It also achieves a much higher accuracy than the state-of-the-art algorithm on very challenging robotic interestingness prediction datasets.
TartanAir: A Dataset to Push the Limits of Visual SLAM
Mar 31, 2020



We present a challenging dataset, the TartanAir, for robot navigation task and more. The data is collected in photo-realistic simulation environments in the presence of various light conditions, weather and moving objects. By collecting data in simulation, we are able to obtain multi-modal sensor data and precise ground truth labels, including the stereo RGB image, depth image, segmentation, optical flow, camera poses, and LiDAR point cloud. We set up a large number of environments with various styles and scenes, covering challenging viewpoints and diverse motion patterns, which are difficult to achieve by using physical data collection platforms.
Instance-Aware Representation Learning and Association for Online Multi-Person Tracking
May 29, 2019
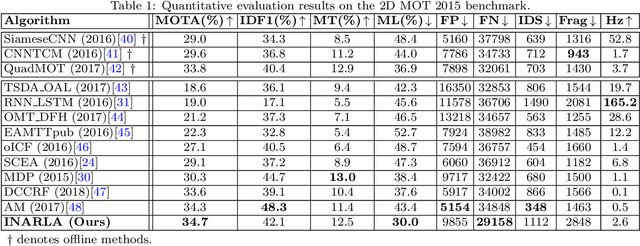
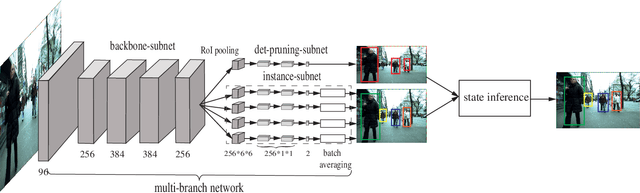
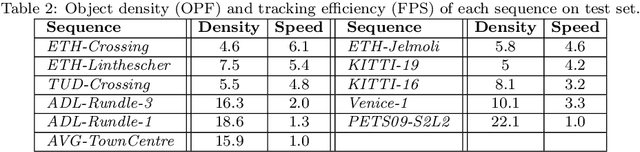
Multi-Person Tracking (MPT) is often addressed within the detection-to-association paradigm. In such approaches, human detections are first extracted in every frame and person trajectories are then recovered by a procedure of data association (usually offline). However, their performances usually degenerate in presence of detection errors, mutual interactions and occlusions. In this paper, we present a deep learning based MPT approach that learns instance-aware representations of tracked persons and robustly online infers states of the tracked persons. Specifically, we design a multi-branch neural network (MBN), which predicts the classification confidences and locations of all targets by taking a batch of candidate regions as input. In our MBN architecture, each branch (instance-subnet) corresponds to an individual to be tracked and new branches can be dynamically created for handling newly appearing persons. Then based on the output of MBN, we construct a joint association matrix that represents meaningful states of tracked persons (e.g., being tracked or disappearing from the scene) and solve it by using the efficient Hungarian algorithm. Moreover, we allow the instance-subnets to be updated during tracking by online mining hard examples, accounting to person appearance variations over time. We comprehensively evaluate our framework on a popular MPT benchmark, demonstrating its excellent performance in comparison with recent online MPT methods.