 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
Oct 09, 2025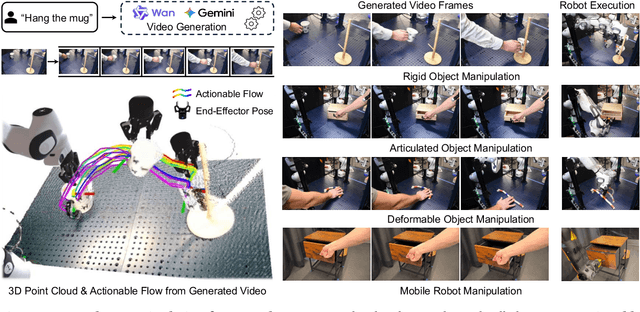
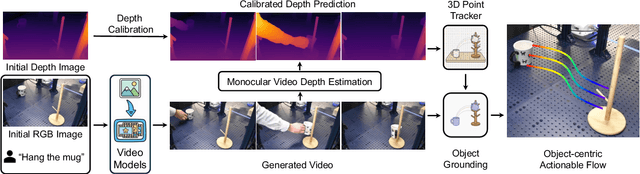


Enabling robots to execute novel manipulation tasks zero-shot is a central goal in robotics. Most existing methods assume in-distribution tasks or rely on fine-tuning with embodiment-matched data, limiting transfer across platforms. We present NovaFlow, an autonomous manipulation framework that converts a task description into an actionable plan for a target robot without any demonstrations. Given a task description, NovaFlow synthesizes a video using a video generation model and distills it into 3D actionable object flow using off-the-shelf perception modules. From the object flow, it computes relative poses for rigid objects and realizes them as robot actions via grasp proposals and trajectory optimization. For deformable objects, this flow serves as a tracking objective for model-based planning with a particle-based dynamics model. By decoupling task understanding from low-level control, NovaFlow naturally transfers across embodiments. We validate on rigid, articulated, and deformable object manipulation tasks using a table-top Franka arm and a Spot quadrupedal mobile robot, and achieve effective zero-shot execution without demonstrations or embodiment-specific training. Project website: https://novaflow.lhy.xyz/.
V2X-PC: Vehicle-to-everything Collaborative Perception via Point Cluster
Mar 25, 2024



The objective of the collaborative vehicle-to-everything perception task is to enhance the individual vehicle's perception capability through message communication among neighboring traffic agents. Previous methods focus on achieving optimal performance within bandwidth limitations and typically adopt BEV maps as the basic collaborative message units. However, we demonstrate that collaboration with dense representations is plagued by object feature destruction during message packing, inefficient message aggregation for long-range collaboration, and implicit structure representation communication. To tackle these issues, we introduce a brand new message unit, namely point cluster, designed to represent the scene sparsely with a combination of low-level structure information and high-level semantic information. The point cluster inherently preserves object information while packing messages, with weak relevance to the collaboration range, and supports explicit structure modeling. Building upon this representation, we propose a novel framework V2X-PC for collaborative perception. This framework includes a Point Cluster Packing (PCP) module to keep object feature and manage bandwidth through the manipulation of cluster point numbers. As for effective message aggregation, we propose a Point Cluster Aggregation (PCA) module to match and merge point clusters associated with the same object. To further handle time latency and pose errors encountered in real-world scenarios, we propose parameter-free solutions that can adapt to different noisy levels without finetuning. Experiments on two widely recognized collaborative perception benchmarks showcase the superior performance of our method compared to the previous state-of-the-art approaches relying on BEV maps.
Eliminating Cross-modal Conflicts in BEV Space for LiDAR-Camera 3D Object Detection
Mar 12, 2024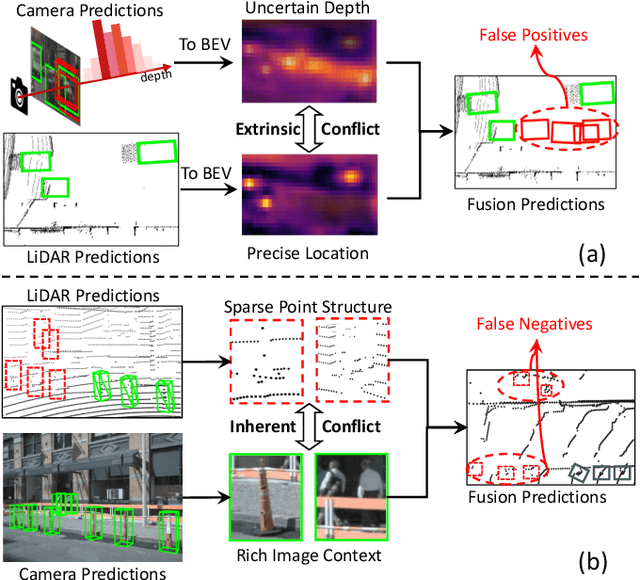
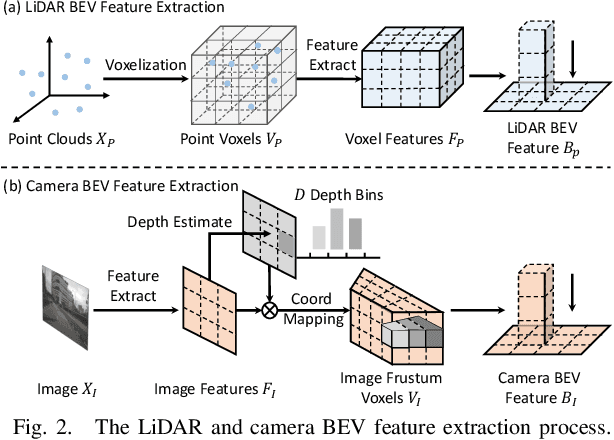
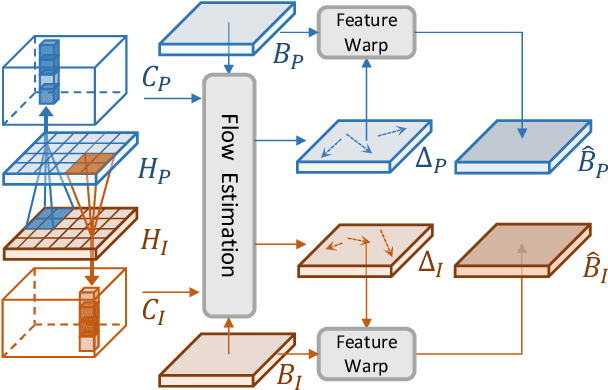
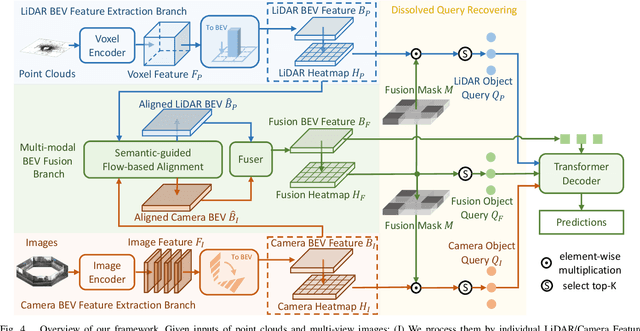
Recent 3D object detectors typically utilize multi-sensor data and unify multi-modal features in the shared bird's-eye view (BEV) representation space. However, our empirical findings indicate that previous methods have limitations in generating fusion BEV features free from cross-modal conflicts. These conflicts encompass extrinsic conflicts caused by BEV feature construction and inherent conflicts stemming from heterogeneous sensor signals. Therefore, we propose a novel Eliminating Conflicts Fusion (ECFusion) method to explicitly eliminate the extrinsic/inherent conflicts in BEV space and produce improved multi-modal BEV features. Specifically, we devise a Semantic-guided Flow-based Alignment (SFA) module to resolve extrinsic conflicts via unifying spatial distribution in BEV space before fusion. Moreover, we design a Dissolved Query Recovering (DQR) mechanism to remedy inherent conflicts by preserving objectness clues that are lost in the fusion BEV feature. In general, our method maximizes the effective information utilization of each modality and leverages inter-modal complementarity. Our method achieves state-of-the-art performance in the highly competitive nuScenes 3D object detection dataset. The code is released at https://github.com/fjhzhixi/ECFusion.
NeuSE: Neural SE(3)-Equivariant Embedding for Consistent Spatial Understanding with Objects
Mar 13, 2023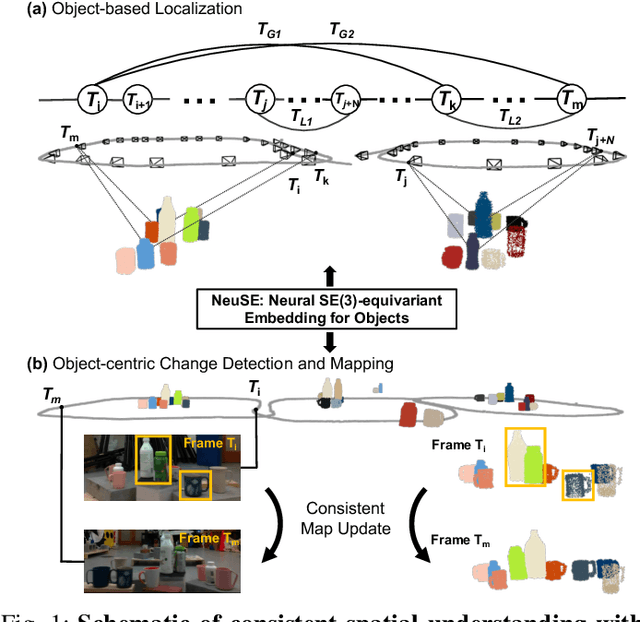
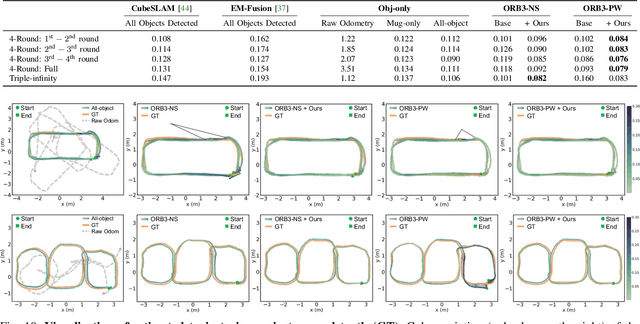
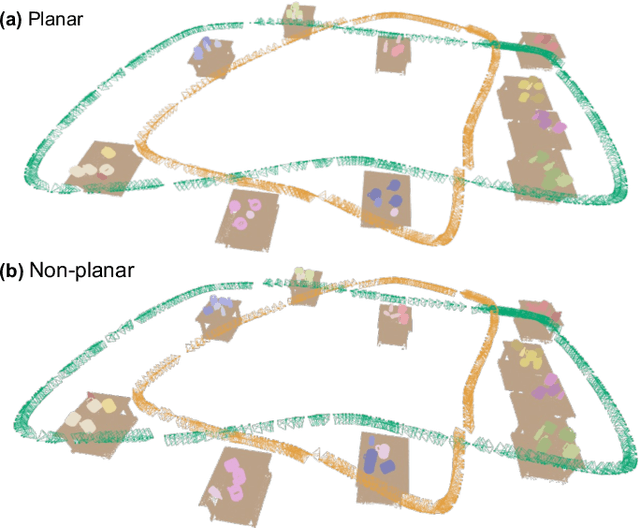
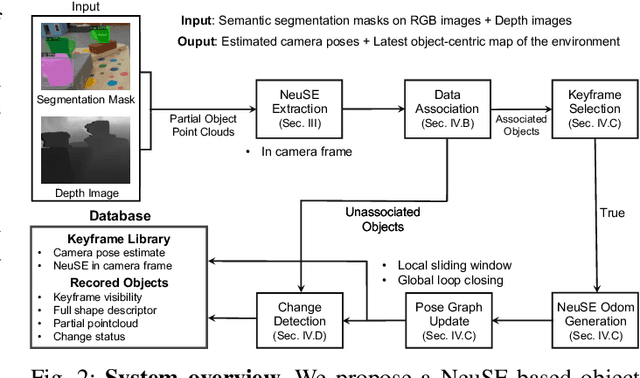
We present NeuSE, a novel Neural SE(3)-Equivariant Embedding for objects, and illustrate how it supports object SLAM for consistent spatial understanding with long-term scene changes. NeuSE is a set of latent object embeddings created from partial object observations. It serves as a compact point cloud surrogate for complete object models, encoding full shape information while transforming SE(3)-equivariantly in tandem with the object in the physical world. With NeuSE, relative frame transforms can be directly derived from inferred latent codes. Our proposed SLAM paradigm, using NeuSE for object shape and pose characterization, can operate independently or in conjunction with typical SLAM systems. It directly infers SE(3) camera pose constraints that are compatible with general SLAM pose graph optimization, while also maintaining a lightweight object-centric map that adapts to real-world changes. Our approach is evaluated on synthetic and real-world sequences featuring changed objects and shows improved localization accuracy and change-aware mapping capability, when working either standalone or jointly with a common SLAM pipeline.
Object as Query: Equipping Any 2D Object Detector with 3D Detection Ability
Jan 06, 2023



3D object detection from multi-view images has drawn much attention over the past few years. Existing methods mainly establish 3D representations from multi-view images and adopt a dense detection head for object detection, or employ object queries distributed in 3D space to localize objects. In this paper, we design Multi-View 2D Objects guided 3D Object Detector (MV2D), which can be equipped with any 2D object detector to promote multi-view 3D object detection. Since 2D detections can provide valuable priors for object existence, MV2D exploits 2D detector to generate object queries conditioned on the rich image semantics. These dynamically generated queries enable MV2D to detect objects in larger 3D space without increased computational costs and shows a strong capability of localizing 3D objects. For the generated queries, we design a sparse cross attention module to force them to focus on the features of specific objects, which reduces the computational cost and suppresses interference from noises. The evaluation results on the nuScenes dataset demonstrate that dynamic object queries and sparse feature aggregation do not harm 3D detection capability. MV2D also exhibits a state-of-the-art performance among existing methods. We hope MV2D can serve as a new baseline for future research.
Robust Change Detection Based on Neural Descriptor Fields
Aug 01, 2022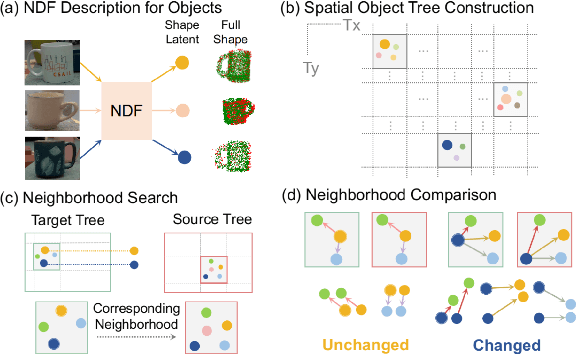
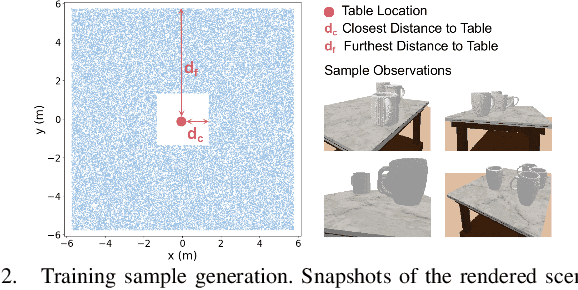
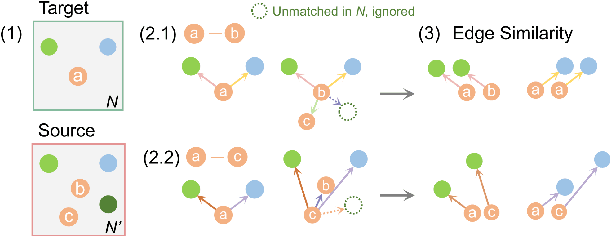
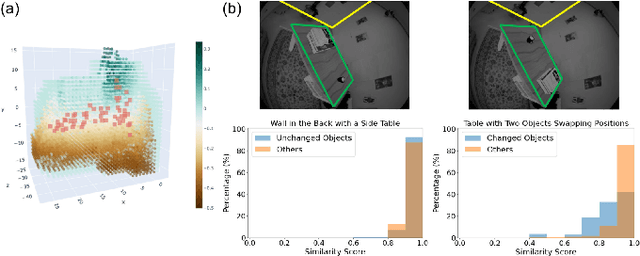
The ability to reason about changes in the environment is crucial for robots operating over extended periods of time. Agents are expected to capture changes during operation so that actions can be followed to ensure a smooth progression of the working session. However, varying viewing angles and accumulated localization errors make it easy for robots to falsely detect changes in the surrounding world due to low observation overlap and drifted object associations. In this paper, based on the recently proposed category-level Neural Descriptor Fields (NDFs), we develop an object-level online change detection approach that is robust to partially overlapping observations and noisy localization results. Utilizing the shape completion capability and SE(3)-equivariance of NDFs, we represent objects with compact shape codes encoding full object shapes from partial observations. The objects are then organized in a spatial tree structure based on object centers recovered from NDFs for fast queries of object neighborhoods. By associating objects via shape code similarity and comparing local object-neighbor spatial layout, our proposed approach demonstrates robustness to low observation overlap and localization noises. We conduct experiments on both synthetic and real-world sequences and achieve improved change detection results compared to multiple baseline methods. Project webpage: https://yilundu.github.io/ndf_change
PlaneSDF-based Change Detection for Long-term Dense Mapping
Jul 18, 2022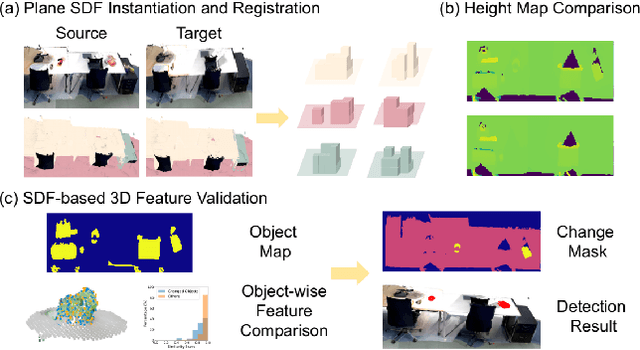
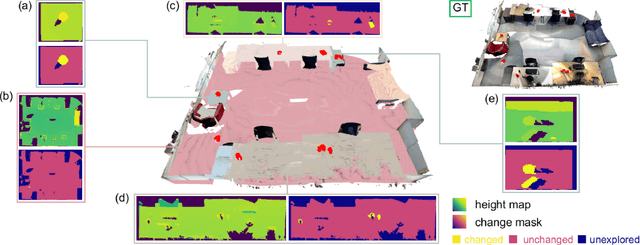
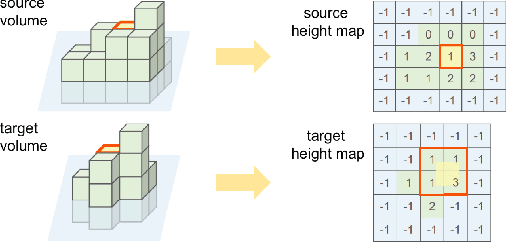
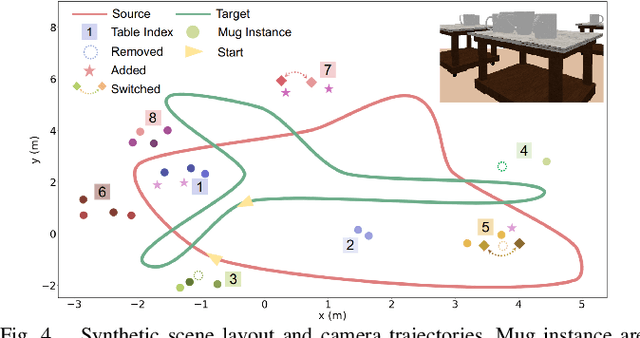
The ability to process environment maps across multiple sessions is critical for robots operating over extended periods of time. Specifically, it is desirable for autonomous agents to detect changes amongst maps of different sessions so as to gain a conflict-free understanding of the current environment. In this paper, we look into the problem of change detection based on a novel map representation, dubbed Plane Signed Distance Fields (PlaneSDF), where dense maps are represented as a collection of planes and their associated geometric components in SDF volumes. Given point clouds of the source and target scenes, we propose a three-step PlaneSDF-based change detection approach: (1) PlaneSDF volumes are instantiated within each scene and registered across scenes using plane poses; 2D height maps and object maps are extracted per volume via height projection and connected component analysis. (2) Height maps are compared and intersected with the object map to produce a 2D change location mask for changed object candidates in the source scene. (3) 3D geometric validation is performed using SDF-derived features per object candidate for change mask refinement. We evaluate our approach on both synthetic and real-world datasets and demonstrate its effectiveness via the task of changed object detection.
3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection
Apr 13, 2022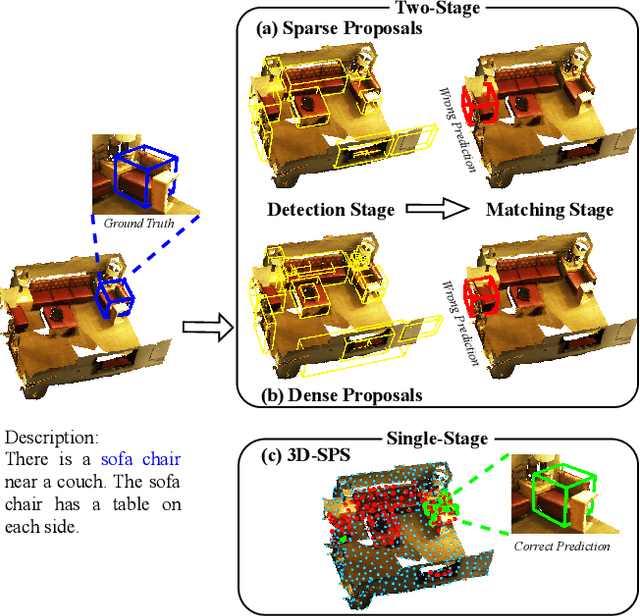
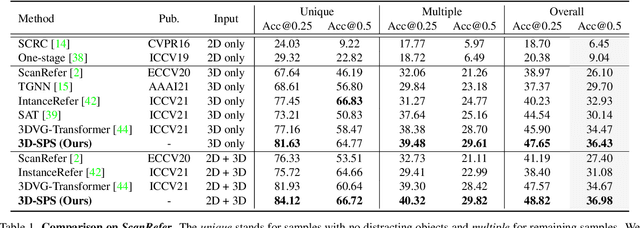
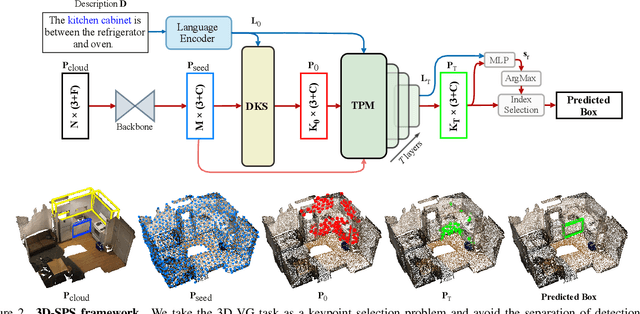
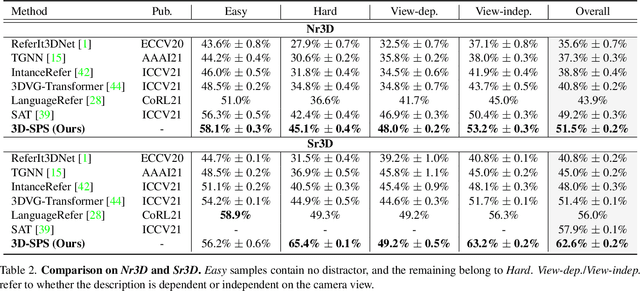
3D visual grounding aims to locate the referred target object in 3D point cloud scenes according to a free-form language description. Previous methods mostly follow a two-stage paradigm, i.e., language-irrelevant detection and cross-modal matching, which is limited by the isolated architecture. In such a paradigm, the detector needs to sample keypoints from raw point clouds due to the inherent properties of 3D point clouds (irregular and large-scale), to generate the corresponding object proposal for each keypoint. However, sparse proposals may leave out the target in detection, while dense proposals may confuse the matching model. Moreover, the language-irrelevant detection stage can only sample a small proportion of keypoints on the target, deteriorating the target prediction. In this paper, we propose a 3D Single-Stage Referred Point Progressive Selection (3D-SPS) method, which progressively selects keypoints with the guidance of language and directly locates the target. Specifically, we propose a Description-aware Keypoint Sampling (DKS) module to coarsely focus on the points of language-relevant objects, which are significant clues for grounding. Besides, we devise a Target-oriented Progressive Mining (TPM) module to finely concentrate on the points of the target, which is enabled by progressive intra-modal relation modeling and inter-modal target mining. 3D-SPS bridges the gap between detection and matching in the 3D visual grounding task, localizing the target at a single stage. Experiments demonstrate that 3D-SPS achieves state-of-the-art performance on both ScanRefer and Nr3D/Sr3D datasets.
Improved Pillar with Fine-grained Feature for 3D Object Detection
Oct 12, 2021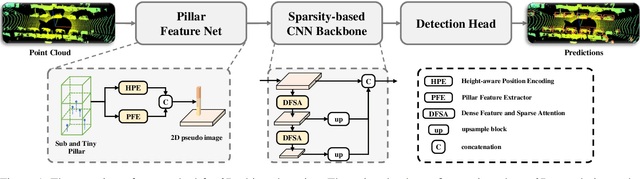
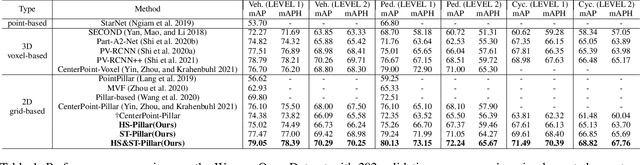
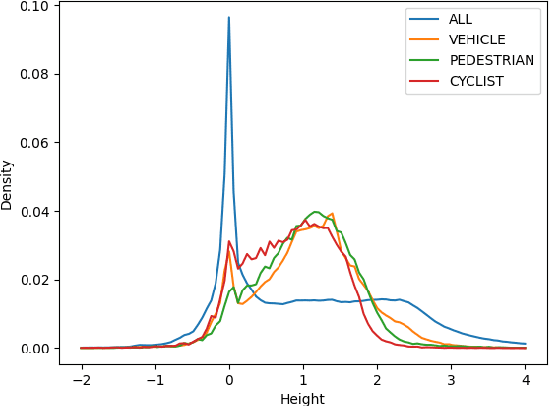
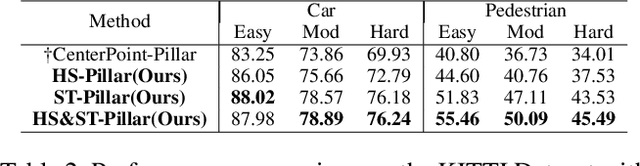
3D object detection with LiDAR point clouds plays an important role in autonomous driving perception module that requires high speed, stability and accuracy. However, the existing point-based methods are challenging to reach the speed requirements because of too many raw points, and the voxel-based methods are unable to ensure stable speed because of the 3D sparse convolution. In contrast, the 2D grid-based methods, such as PointPillar, can easily achieve a stable and efficient speed based on simple 2D convolution, but it is hard to get the competitive accuracy limited by the coarse-grained point clouds representation. So we propose an improved pillar with fine-grained feature based on PointPillar that can significantly improve detection accuracy. It consists of two modules, including height-aware sub-pillar and sparsity-based tiny-pillar, which get fine-grained representation respectively in the vertical and horizontal direction of 3D space. For height-aware sub-pillar, we introduce a height position encoding to keep height information of each sub-pillar during projecting to a 2D pseudo image. For sparsity-based tiny-pillar, we introduce sparsity-based CNN backbone stacked by dense feature and sparse attention module to extract feature with larger receptive field efficiently. Experimental results show that our proposed method significantly outperforms previous state-of-the-art 3D detection methods on the Waymo Open Dataset. The related code will be released to facilitate the academic and industrial study.
A Multi-Hypothesis Approach to Pose Ambiguity in Object-Based SLAM
Aug 03, 2021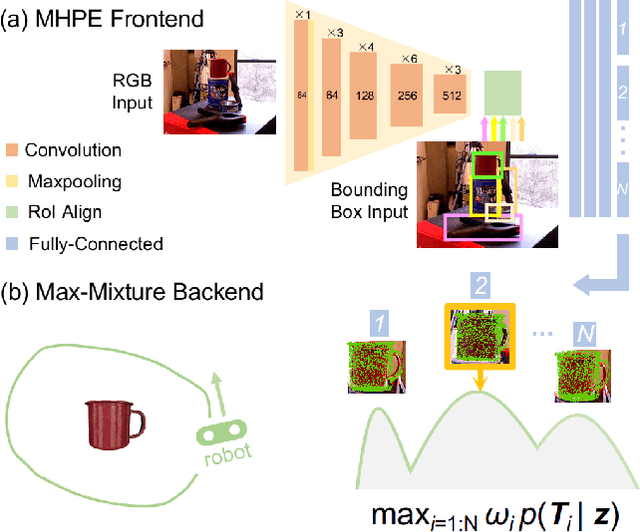
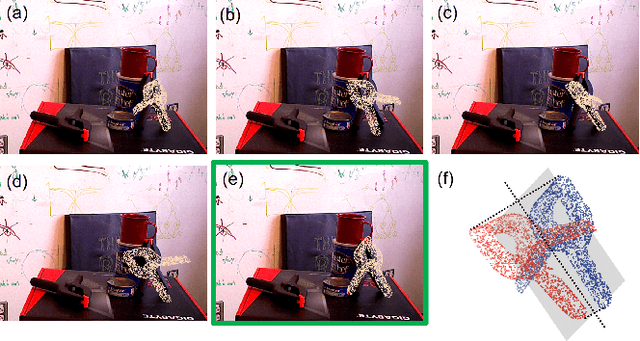
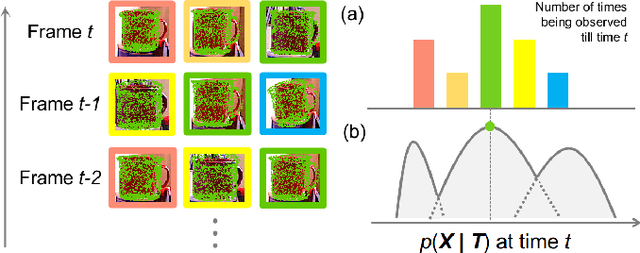

In object-based Simultaneous Localization and Mapping (SLAM), 6D object poses offer a compact representation of landmark geometry useful for downstream planning and manipulation tasks. However, measurement ambiguity then arises as objects may possess complete or partial object shape symmetries (e.g., due to occlusion), making it difficult or impossible to generate a single consistent object pose estimate. One idea is to generate multiple pose candidates to counteract measurement ambiguity. In this paper, we develop a novel approach that enables an object-based SLAM system to reason about multiple pose hypotheses for an object, and synthesize this locally ambiguous information into a globally consistent robot and landmark pose estimation formulation. In particular, we (1) present a learned pose estimation network that provides multiple hypotheses about the 6D pose of an object; (2) by treating the output of our network as components of a mixture model, we incorporate pose predictions into a SLAM system, which, over successive observations, recovers a globally consistent set of robot and object (landmark) pose estimates. We evaluate our approach on the popular YCB-Video Dataset and a simulated video featuring YCB objects. Experiments demonstrate that our approach is effective in improving the robustness of object-based SLAM in the face of object pose ambiguity.