 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaneSDF-based Change Detection for Long-term Dense Mapping
Jul 18, 2022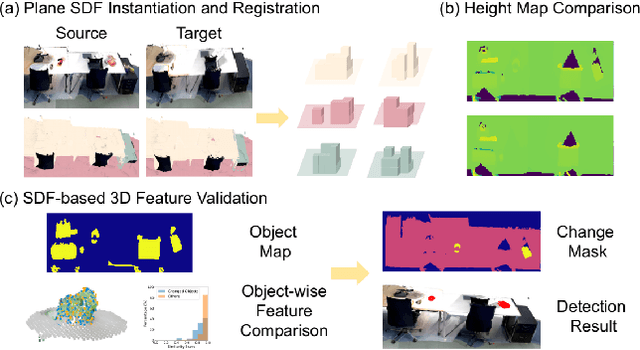
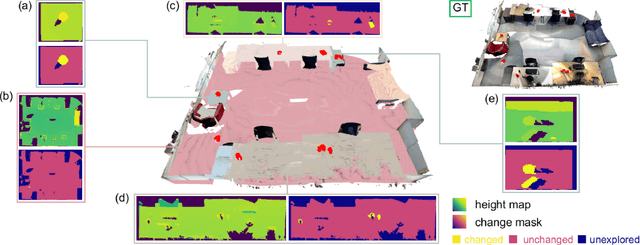
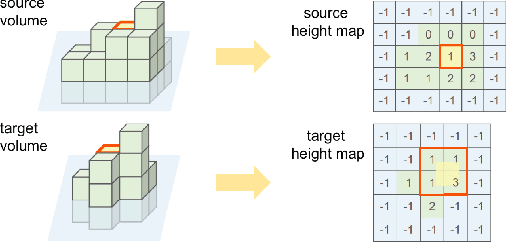
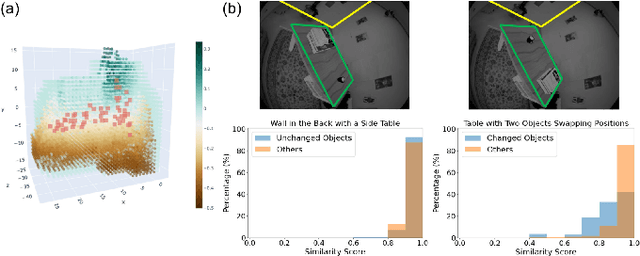
The ability to process environment maps across multiple sessions is critical for robots operating over extended periods of time. Specifically, it is desirable for autonomous agents to detect changes amongst maps of different sessions so as to gain a conflict-free understanding of the current environment. In this paper, we look into the problem of change detection based on a novel map representation, dubbed Plane Signed Distance Fields (PlaneSDF), where dense maps are represented as a collection of planes and their associated geometric components in SDF volumes. Given point clouds of the source and target scenes, we propose a three-step PlaneSDF-based change detection approach: (1) PlaneSDF volumes are instantiated within each scene and registered across scenes using plane poses; 2D height maps and object maps are extracted per volume via height projection and connected component analysis. (2) Height maps are compared and intersected with the object map to produce a 2D change location mask for changed object candidates in the source scene. (3) 3D geometric validation is performed using SDF-derived features per object candidate for change mask refinement. We evaluate our approach on both synthetic and real-world datasets and demonstrate its effectiveness via the task of changed object detection.
Unified Underwater Structure-from-Motion
Sep 09, 2019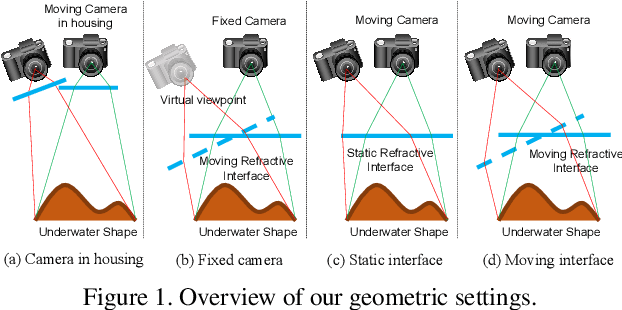
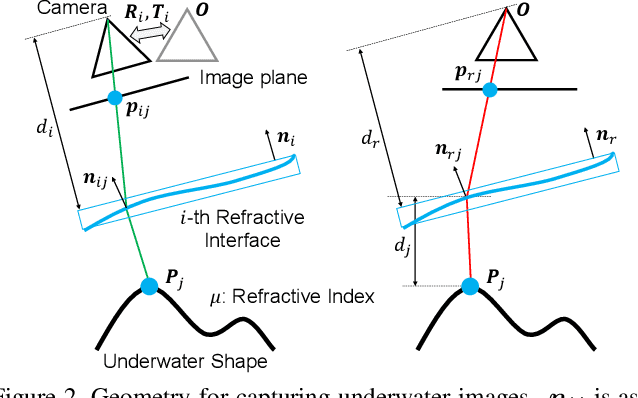
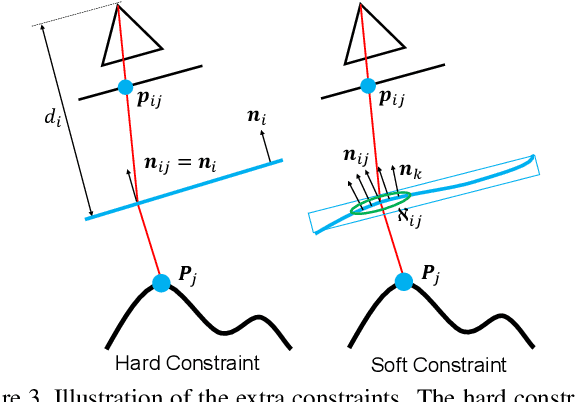
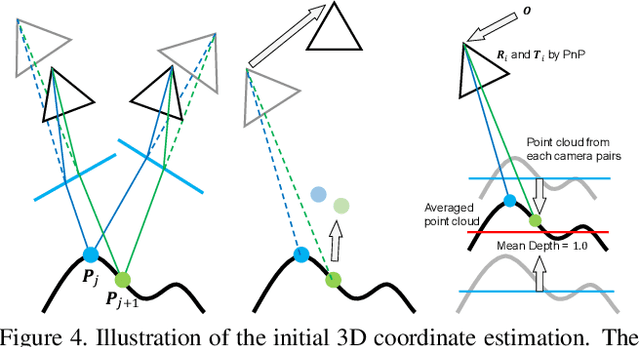
This paper shows that accurate underwater 3D shape reconstruction is possible using a single camera, observing a target through a refractive interface. We provide unified reconstruction techniques for a variety of scenarios such as single static camera and moving refractive interface, single moving camera and static refractive interface, and single moving camera and moving refractive interface. In our basic setup, we assume that the refractive interface is planar, and simultaneously estimate the unknown transformations of the planar interface and the camera, and the unknown target shape using bundle adjustment. We also extend it to relax the planarity assumption, which enables us to use waves of the refractive interface for the reconstruction task. Experiments with real data show the superiority of our method to existing methods.
VLASE: Vehicle Localization by Aggregating Semantic Edges
Jul 06, 2018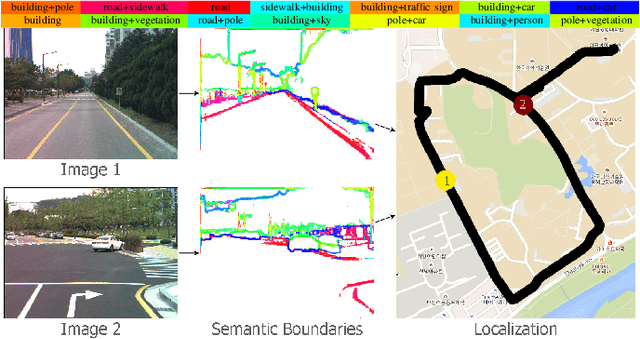
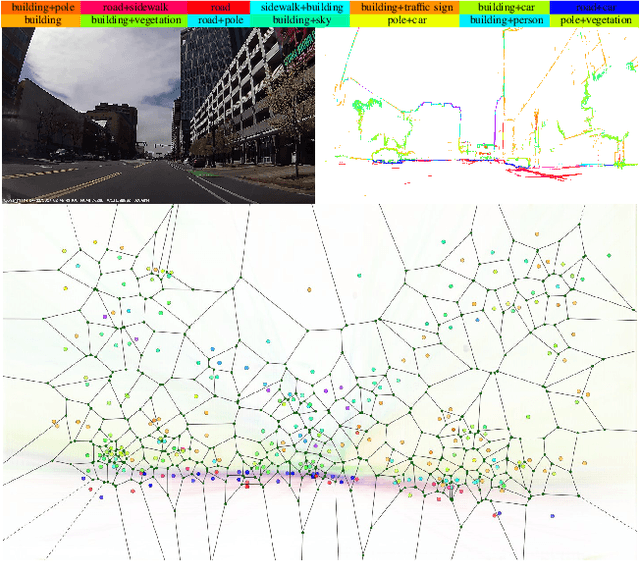
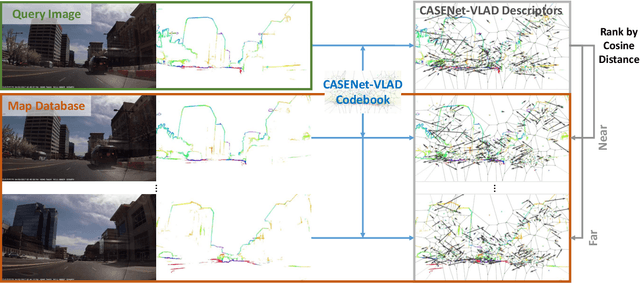
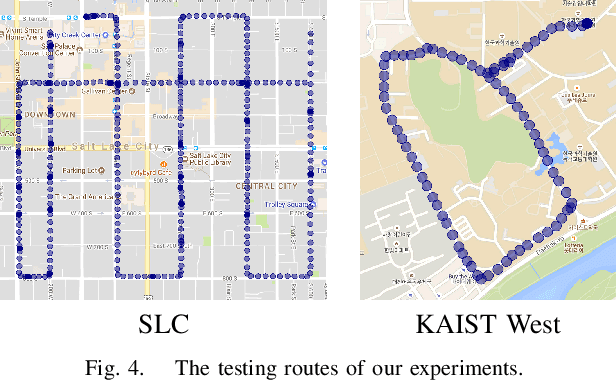
In this paper, we propose VLASE, a framework to use semantic edge features from images to achieve on-road localization. Semantic edge features denote edge contours that separate pairs of distinct objects such as building-sky, road- sidewalk, and building-ground. While prior work has shown promising results by utilizing the boundary between prominent classes such as sky and building using skylines, we generalize this approach to consider semantic edge features that arise from 19 different classes. Our localization algorithm is simple, yet very powerful. We extract semantic edge features using a recently introduced CASENet architecture and utilize VLAD framework to perform image retrieval. Our experiments show that we achieve improvement over some of the state-of-the-art localization algorithms such as SIFT-VLAD and its deep variant NetVLAD. We use ablation study to study the importance of different semantic classes and show that our unified approach achieves better performance compared to individual prominent features such as skylines.
Joint 3D Reconstruction of a Static Scene and Moving Objects
Feb 13, 2018
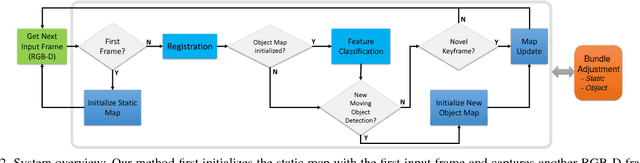
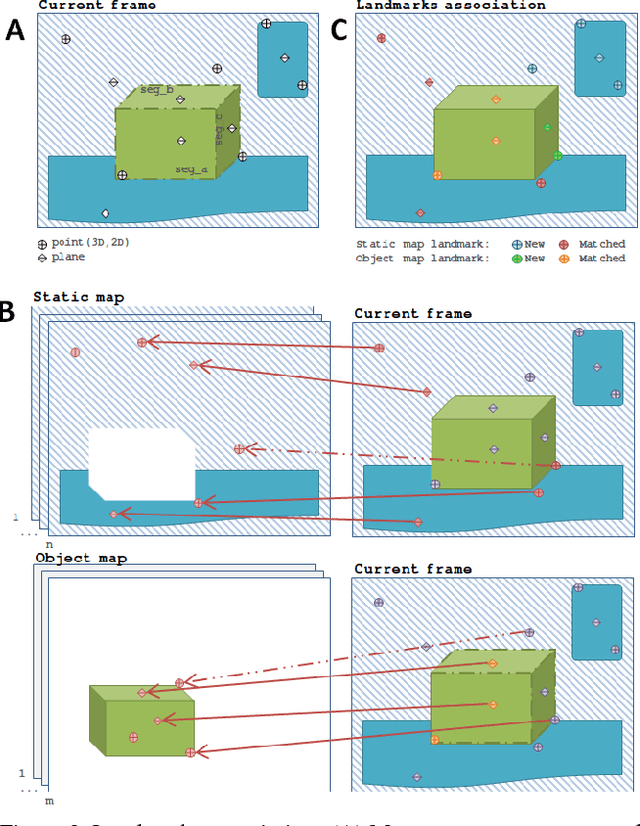

We present a technique for simultaneous 3D reconstruction of static regions and rigidly moving objects in a scene. An RGB-D frame is represented as a collection of features, which are points and planes. We classify the features into static and dynamic regions and grow separate maps, static and object maps, for each of them. To robustly classify the features in each frame, we fuse multiple RANSAC-based registration results obtained by registering different groups of the features to different maps, including (1) all the features to the static map, (2) all the features to each object map, and (3) subsets of the features, each forming a segment, to each object map. This multi-group registration approach is designed to overcome the following challenges: scenes can be dominated by static regions, making object tracking more difficult; and moving object might have larger pose variation between frames compared to the static regions. We show qualitative results from indoor scenes with objects in various shapes. The technique enables on-the-fly object model generation to be used for robotic manipulation.
* This paper has been accepted and presented in 3DV-2017 conference held at Qingdao, China. Video experiments: https://youtu.be/goflUxzG2VI
3D Object Discovery and Modeling Using Single RGB-D Images Containing Multiple Object Instances
Oct 17, 2017
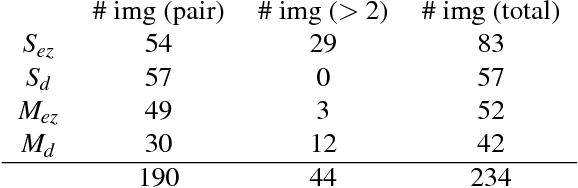
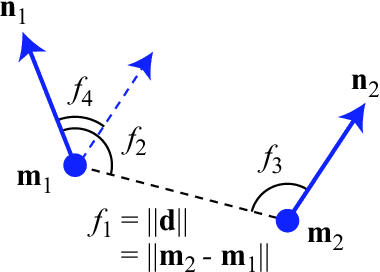
Unsupervised object modeling is important in robotics, especially for handling a large set of objects. We present a method for unsupervised 3D object discovery, reconstruction, and localization that exploits multiple instances of an identical object contained in a single RGB-D image. The proposed method does not rely on segmentation, scene knowledge, or user input, and thus is easily scalable. Our method aims to find recurrent patterns in a single RGB-D image by utilizing appearance and geometry of the salient regions. We extract keypoints and match them in pairs based on their descriptors. We then generate triplets of the keypoints matching with each other using several geometric criteria to minimize false matches. The relative poses of the matched triplets are computed and clustered to discover sets of triplet pairs with similar relative poses. Triplets belonging to the same set are likely to belong to the same object and are used to construct an initial object model. Detection of remaining instances with the initial object model using RANSAC allows to further expand and refine the model. The automatically generated object models are both compact and descriptive. We show quantitative and qualitative results on RGB-D images with various objects including some from the Amazon Picking Challenge. We also demonstrate the use of our method in an object picking scenario with a robotic arm.
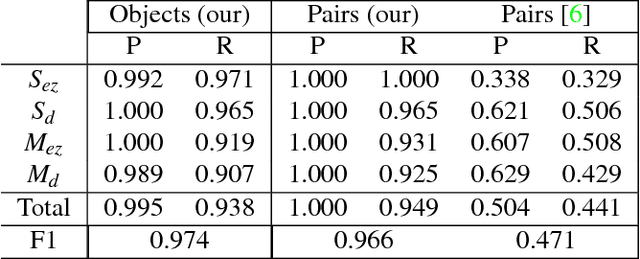
Detecting and Grouping Identical Objects for Region Proposal and Classification
Jul 23, 2017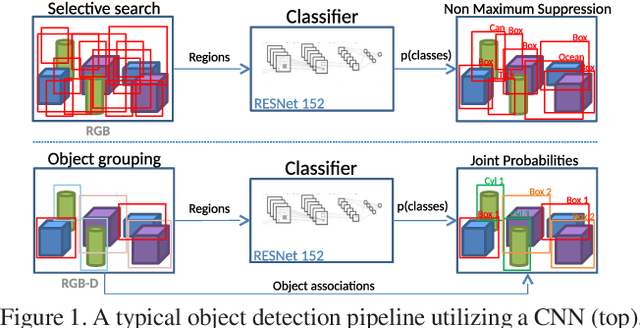

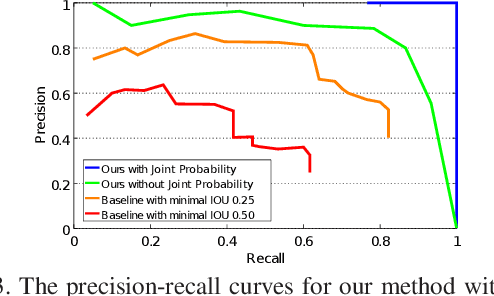
Often multiple instances of an object occur in the same scene, for example in a warehouse. Unsupervised multi-instance object discovery algorithms are able to detect and identify such objects. We use such an algorithm to provide object proposals to a convolutional neural network (CNN) based classifier. This results in fewer regions to evaluate, compared to traditional region proposal algorithms. Additionally, it enables using the joint probability of multiple instances of an object, resulting in improved classification accuracy. The proposed technique can also split a single class into multiple sub-classes corresponding to the different object types, enabling hierarchical classification.
Global-Local Face Upsampling Network
Apr 27, 2016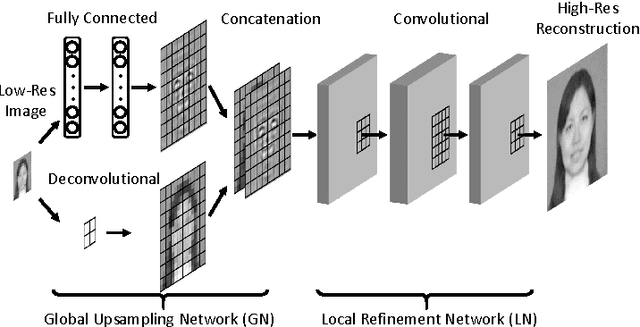

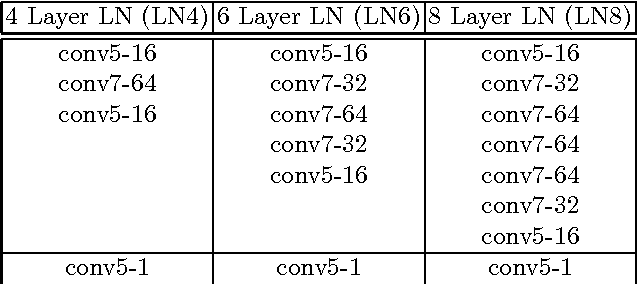

Face hallucination, which is the task of generating a high-resolution face image from a low-resolution input image, is a well-studied problem that is useful in widespread application areas. Face hallucination is particularly challenging when the input face resolution is very low (e.g., 10 x 12 pixels) and/or the image is captured in an uncontrolled setting with large pose and illumination variations. In this paper, we revisit the algorithm introduced in [1] and present a deep interpretation of this framework that achieves state-of-the-art under such challenging scenarios. In our deep network architecture the global and local constraints that define a face can be efficiently modeled and learned end-to-end using training data. Conceptually our network design can be partitioned into two sub-networks: the first one implements the holistic face reconstruction according to global constraints, and the second one enhances face-specific details and enforces local patch statistics. We optimize the deep network using a new loss function for super-resolution that combines reconstruction error with a learned face quality measure in adversarial setting, producing improved visual results. We conduct extensive experiments in both controlled and uncontrolled setups and show that our algorithm improves the state of the art both numerically and visually.
Learning to Remove Multipath Distortions in Time-of-Flight Range Images for a Robotic Arm Setup
Feb 23, 2016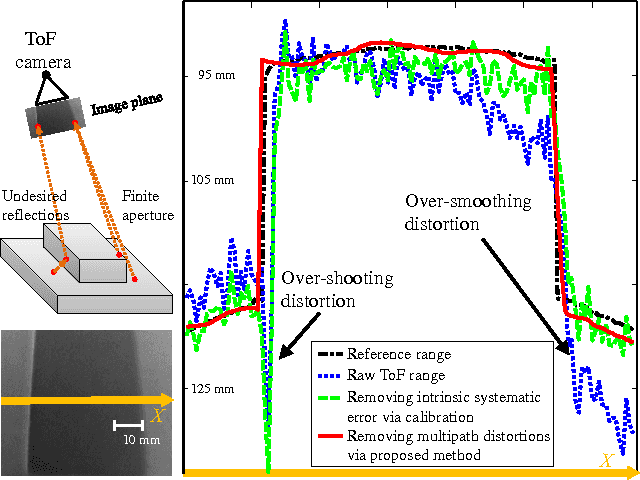



Range images captured by Time-of-Flight (ToF) cameras are corrupted with multipath distortions due to interaction between modulated light signals and scenes. The interaction is often complicated, which makes a model-based solution elusive. We propose a learning-based approach for removing the multipath distortions for a ToF camera in a robotic arm setup. Our approach is based on deep learning. We use the robotic arm to automatically collect a large amount of ToF range images containing various multipath distortions. The training images are automatically labeled by leveraging a high precision structured light sensor available only in the training time. In the test time, we apply the learned model to remove the multipath distortions. This allows our robotic arm setup to enjoy the speed and compact form of the ToF camera without compromising with its range measurement errors. We conduct extensive experimental validations and compare the proposed method to several baseline algorithms. The experiment results show that our method achieves 55% error reduction in range estimation and largely outperforms the baseline algorithms.