 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCEM: Embedder Equipped with Query Rewriting Skill for Robust Conversational Search in Distributional Shift
Jun 01, 2026Conversational search has become increasingly important in retrieval-augmented generation (RAG) systems, where users interact with AI assistants through multi-turn conversations containing context-dependent queries. We propose RCEM, a conversational dense retrieval model that distills the query reformulation capability of LLMs into the embedding model, enabling context-aware retrieval without explicit query rewriting during inference. Unlike prior conversational dense retrieval approaches that learn direct conversation-to-document matching, RCEM aligns conversational-query embeddings with rewritten-query embeddings, improving robustness under distributional shift. RCEM does not require conversational query-to-document relevance mappings for training, which are often expensive and difficult to obtain with high quality. Extensive experiments on QReCC, TopiOCQA, and TREC CAsT demonstrate that RCEM consistently outperforms strong conversational retrieval baselines, achieving particularly large gains under distributional shift, including up to 20% improvement in Recall@10. RCEM further extends the base embedding model with conversational query rewriting capability while preserving its original retrieval functionality, allowing both standalone and conversational queries to be encoded by a single model and searched against existing document indexes without rebuilding the retrieval database.
TextManiA: Enriching Visual Feature by Text-driven Manifold Augmentation
Jul 31, 2023



Recent label mix-based augmentation methods have shown their effectiveness in generalization despite their simplicity, and their favorable effects are often attributed to semantic-level augmentation. However, we found that they are vulnerable to highly skewed class distribution, because scarce data classes are rarely sampled for inter-class perturbation. We propose TextManiA, a text-driven manifold augmentation method that semantically enriches visual feature spaces, regardless of data distribution. TextManiA augments visual data with intra-class semantic perturbation by exploiting easy-to-understand visually mimetic words, i.e., attributes. To this end, we bridge between the text representation and a target visual feature space, and propose an efficient vector augmentation. To empirically support the validity of our design, we devise two visualization-based analyses and show the plausibility of the bridge between two different modality spaces. Our experiments demonstrate that TextManiA is powerful in scarce samples with class imbalance as well as even distribution. We also show compatibility with the label mix-based approaches in evenly distributed scarce data.
Learning Customized Visual Models with Retrieval-Augmented Knowledge
Jan 17, 2023



Image-text contrastive learning models such as CLIP have demonstrated strong task transfer ability. The high generality and usability of these visual models is achieved via a web-scale data collection process to ensure broad concept coverage, followed by expensive pre-training to feed all the knowledge into model weights. Alternatively, we propose REACT, REtrieval-Augmented CusTomization, a framework to acquire the relevant web knowledge to build customized visual models for target domains. We retrieve the most relevant image-text pairs (~3% of CLIP pre-training data) from the web-scale database as external knowledge, and propose to customize the model by only training new modualized blocks while freezing all the original weights. The effectiveness of REACT is demonstrated via extensive experiments on classification, retrieval, detection and segmentation tasks, including zero, few, and full-shot settings. Particularly, on the zero-shot classification task, compared with CLIP, it achieves up to 5.4% improvement on ImageNet and 3.7% on the ELEVATER benchmark (20 datasets).
Bootstrapping Deep Neural Networks from Image Processing and Computer Vision Pipelines
Nov 29, 2018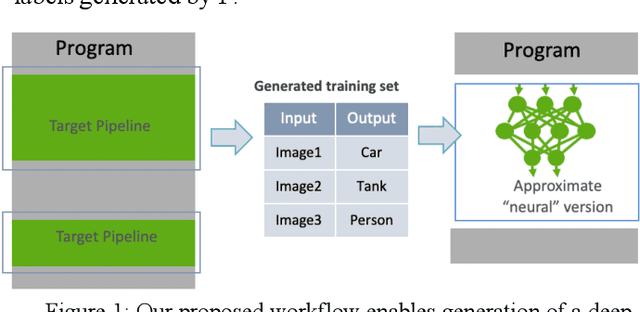
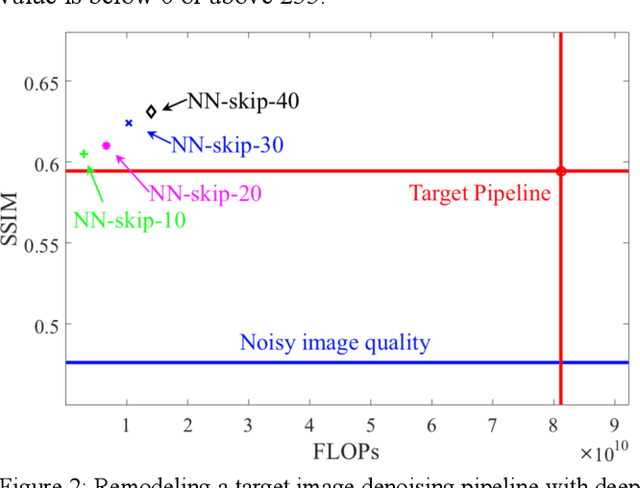
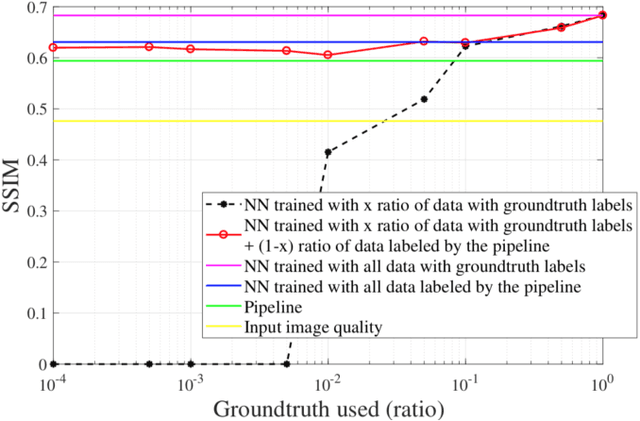
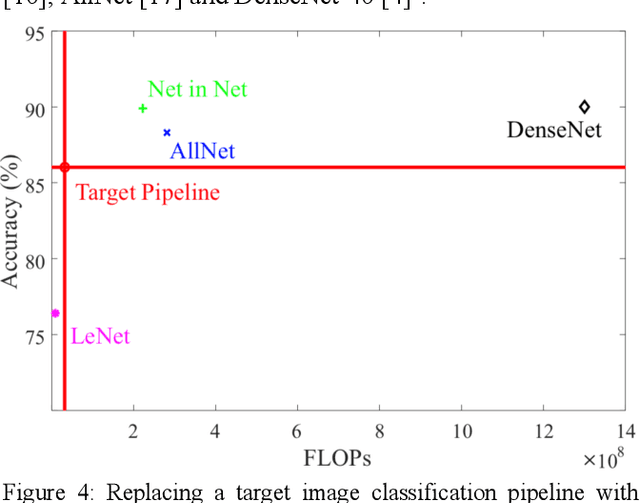
Complex image processing and computer vision systems often consist of a "pipeline" of "black boxes" that each solve part of the problem. We intend to replace parts or all of a target pipeline with deep neural networks to achieve benefits such as increased accuracy or reduced computational requirement. To acquire a large amounts of labeled data necessary to train the deep neural network, we propose a workflow that leverages the target pipeline to create a significantly larger labeled training set automatically, without prior domain knowledge of the target pipeline. We show experimentally that despite the noise introduced by automated labeling and only using a very small initially labeled data set, the trained deep neural networks can achieve similar or even better performance than the components they replace, while in some cases also reducing computational requirements.
Learning to Remove Multipath Distortions in Time-of-Flight Range Images for a Robotic Arm Setup
Feb 23, 2016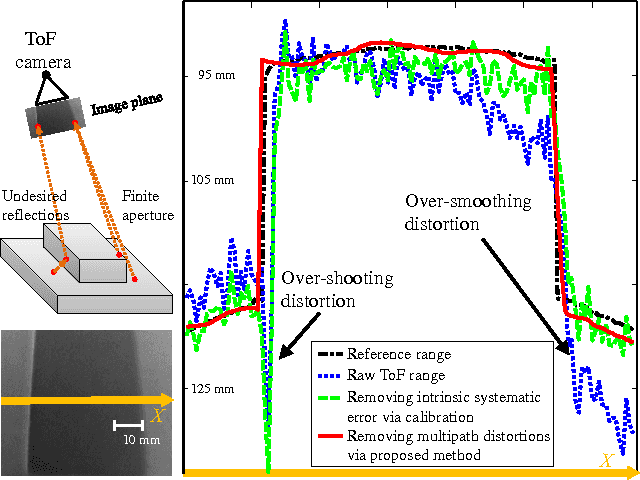



Range images captured by Time-of-Flight (ToF) cameras are corrupted with multipath distortions due to interaction between modulated light signals and scenes. The interaction is often complicated, which makes a model-based solution elusive. We propose a learning-based approach for removing the multipath distortions for a ToF camera in a robotic arm setup. Our approach is based on deep learning. We use the robotic arm to automatically collect a large amount of ToF range images containing various multipath distortions. The training images are automatically labeled by leveraging a high precision structured light sensor available only in the training time. In the test time, we apply the learned model to remove the multipath distortions. This allows our robotic arm setup to enjoy the speed and compact form of the ToF camera without compromising with its range measurement errors. We conduct extensive experimental validations and compare the proposed method to several baseline algorithms. The experiment results show that our method achieves 55% error reduction in range estimation and largely outperforms the baseline algorithms.