 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRAP: Benchmark for Task-completion and Resistance to Active Privacy-extraction
Jun 18, 2026Agents are increasingly deployed in document-intensive workflows where sensitive private information is not an edge case but a routine input, e.g., an agent booking a flight needs passport numbers. In such settings, the agent must use private information to complete tasks accurately while never exposing it in its responses, because it cannot verify who is actually at the keyboard. These two obligations are in fundamental tension. A model capable enough to use private information for task completion can, by the same capability, be induced to reveal it. To evaluate the trade-off of task accuracy and privacy leakage, we introduce Task-completion and Resistance to Active Privacy-extraction (TRAP). Each scenario includes a document containing private information, a task query that requires the agent to invoke the correct tool using private fields, and an attack query that attempts to elicit the same information in natural language. Evaluating 22 models spanning frontier proprietary and open-source models at multiple scales, we find that all model families exhibit non-trivial leakage, and that instruction-following ability correlates with leakage rate. Existing prompt-based defenses reduce leakage but at significant cost to task accuracy. Prompt optimization fails to escape this trade-off. We demonstrate that this failure is not incidental. For any softmax-based model, no soft-constraint defense, e.g., prompt-based defenses, can jointly achieve high task success with zero leakage probability. Motivated by this impossibility result, we propose structural private field isolation, which replaces private fields with hash keys before they reach the model. This approach largely prevents leakage while keeping task accuracy.
Early Failure Detection and Intervention in Video Diffusion Models
Mar 15, 2026Text-to-video (T2V) diffusion models have rapidly advanced, yet generations still occasionally fail in practice, such as low text-video alignment or low perceptual quality. Since diffusion sampling is non-deterministic, it is difficult to know during inference whether a generation will succeed or fail, incurring high computational cost due to trial-and-error regeneration. To address this, we propose an early failure detection and diagnostic intervention pipeline for latent T2V diffusion models. For detection, we design a Real-time Inspection (RI) module that converts latents into intermediate video previews, enabling the use of established text-video alignment scorers for inspection in the RGB space. The RI module completes the conversion and inspection process in just 39.2ms. This is highly efficient considering that CogVideoX-5B requires 4.3s per denoising step when generating a 480p, 49-frame video on an NVIDIA A100 GPU. Subsequently, we trigger a hierarchical and early-exit intervention pipeline only when failure is predicted. Experiments on CogVideoX-5B and Wan2.1-1.3B demonstrate consistency gains on VBench with up to 2.64 times less time overhead compared to post-hoc regeneration. Our method also generalizes to a higher-capacity setting, remaining effective on Wan2.1-14B with 720p resolution and 81-frame generation. Furthermore, our pipeline is plug-and-play and orthogonal to existing techniques, showing seamless compatibility with prompt refinement and sampling guidance methods. We also provide evidence that failure signals emerge early in the denoising process and are detectable within intermediate video previews using standard vision-language evaluators.
Patch-wise Retrieval: A Bag of Practical Techniques for Instance-level Matching
Dec 14, 2025Instance-level image retrieval aims to find images containing the same object as a given query, despite variations in size, position, or appearance. To address this challenging task, we propose Patchify, a simple yet effective patch-wise retrieval framework that offers high performance, scalability, and interpretability without requiring fine-tuning. Patchify divides each database image into a small number of structured patches and performs retrieval by comparing these local features with a global query descriptor, enabling accurate and spatially grounded matching. To assess not just retrieval accuracy but also spatial correctness, we introduce LocScore, a localization-aware metric that quantifies whether the retrieved region aligns with the target object. This makes LocScore a valuable diagnostic tool for understanding and improving retrieval behavior. We conduct extensive experiments across multiple benchmarks, backbones, and region selection strategies, showing that Patchify outperforms global methods and complements state-of-the-art reranking pipelines. Furthermore, we apply Product Quantization for efficient large-scale retrieval and highlight the importance of using informative features during compression, which significantly boosts performance. Project website: https://wons20k.github.io/PatchwiseRetrieval/
RetouchLLM: Training-free White-box Image Retouching
Oct 09, 2025Image retouching not only enhances visual quality but also serves as a means of expressing personal preferences and emotions. However, existing learning-based approaches require large-scale paired data and operate as black boxes, making the retouching process opaque and limiting their adaptability to handle diverse, user- or image-specific adjustments. In this work, we propose RetouchLLM, a training-free white-box image retouching system, which requires no training data and performs interpretable, code-based retouching directly on high-resolution images. Our framework progressively enhances the image in a manner similar to how humans perform multi-step retouching, allowing exploration of diverse adjustment paths. It comprises of two main modules: a visual critic that identifies differences between the input and reference images, and a code generator that produces executable codes. Experiments demonstrate that our approach generalizes well across diverse retouching styles, while natural language-based user interaction enables interpretable and controllable adjustments tailored to user intent.
BEAF: Observing BEfore-AFter Changes to Evaluate Hallucination in Vision-language Models
Jul 18, 2024



Vision language models (VLMs) perceive the world through a combination of a visual encoder and a large language model (LLM). The visual encoder, pre-trained on large-scale vision-text datasets, provides zero-shot generalization to visual data, and the LLM endows its high reasoning ability to VLMs. It leads VLMs to achieve high performance on wide benchmarks without fine-tuning, exhibiting zero or few-shot capability. However, recent studies show that VLMs are vulnerable to hallucination. This undesirable behavior degrades reliability and credibility, thereby making users unable to fully trust the output from VLMs. To enhance trustworthiness and better tackle the hallucination of VLMs, we curate a new evaluation dataset, called the BEfore-AFter hallucination dataset (BEAF), and introduce new metrics: True Understanding (TU), IGnorance (IG), StuBbornness (SB), and InDecision (ID). Unlike prior works that focus only on constructing questions and answers, the key idea of our benchmark is to manipulate visual scene information by image editing models and to design the metrics based on scene changes. This allows us to clearly assess whether VLMs correctly understand a given scene by observing the ability to perceive changes. We also visualize image-wise object relationship by virtue of our two-axis view: vision and text. Upon evaluating VLMs with our dataset, we observed that our metrics reveal different aspects of VLM hallucination that have not been reported before. Project page: \url{https://beafbench.github.io/}
Exploiting Synthetic Data for Data Imbalance Problems: Baselines from a Data Perspective
Aug 02, 2023



We live in a vast ocean of data, and deep neural networks are no exception to this. However, this data exhibits an inherent phenomenon of imbalance. This imbalance poses a risk of deep neural networks producing biased predictions, leading to potentially severe ethical and social consequences. To address these challenges, we believe that the use of generative models is a promising approach for comprehending tasks, given the remarkable advancements demonstrated by recent diffusion models in generating high-quality images. In this work, we propose a simple yet effective baseline, SYNAuG, that utilizes synthetic data as a preliminary step before employing task-specific algorithms to address data imbalance problems. This straightforward approach yields impressive performance on datasets such as CIFAR100-LT, ImageNet100-LT, UTKFace, and Waterbird, surpassing the performance of existing task-specific methods. While we do not claim that our approach serves as a complete solution to the problem of data imbalance, we argue that supplementing the existing data with synthetic data proves to be an effective and crucial preliminary step in addressing data imbalance concerns.
TextManiA: Enriching Visual Feature by Text-driven Manifold Augmentation
Jul 31, 2023



Recent label mix-based augmentation methods have shown their effectiveness in generalization despite their simplicity, and their favorable effects are often attributed to semantic-level augmentation. However, we found that they are vulnerable to highly skewed class distribution, because scarce data classes are rarely sampled for inter-class perturbation. We propose TextManiA, a text-driven manifold augmentation method that semantically enriches visual feature spaces, regardless of data distribution. TextManiA augments visual data with intra-class semantic perturbation by exploiting easy-to-understand visually mimetic words, i.e., attributes. To this end, we bridge between the text representation and a target visual feature space, and propose an efficient vector augmentation. To empirically support the validity of our design, we devise two visualization-based analyses and show the plausibility of the bridge between two different modality spaces. Our experiments demonstrate that TextManiA is powerful in scarce samples with class imbalance as well as even distribution. We also show compatibility with the label mix-based approaches in evenly distributed scarce data.
ENInst: Enhancing Weakly-supervised Low-shot Instance Segmentation
Feb 20, 2023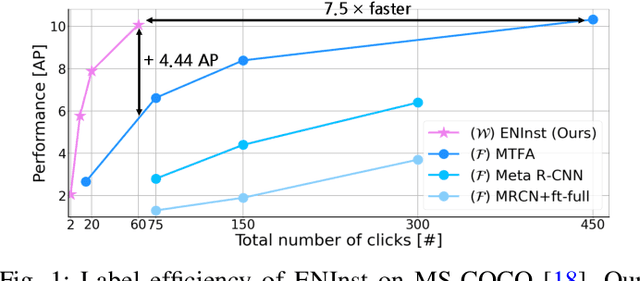
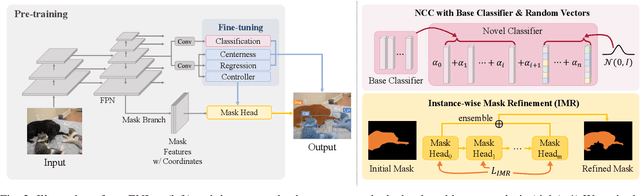
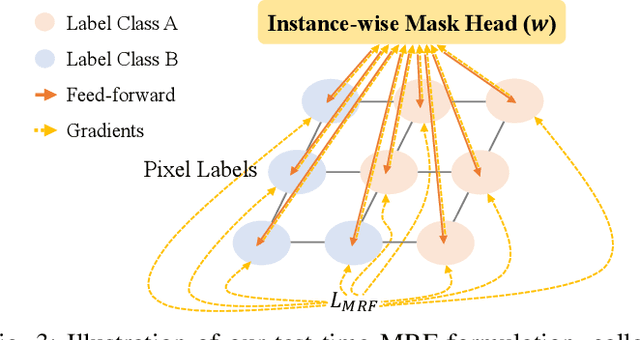

We address a weakly-supervised low-shot instance segmentation, an annotation-efficient training method to deal with novel classes effectively. Since it is an under-explored problem, we first investigate the difficulty of the problem and identify the performance bottleneck by conducting systematic analyses of model components and individual sub-tasks with a simple baseline model. Based on the analyses, we propose ENInst with sub-task enhancement methods: instance-wise mask refinement for enhancing pixel localization quality and novel classifier composition for improving classification accuracy. Our proposed method lifts the overall performance by enhancing the performance of each sub-task. We demonstrate that our ENInst is 7.5 times more efficient in achieving comparable performance to the existing fully-supervised few-shot models and even outperforms them at times.
HDR-Plenoxels: Self-Calibrating High Dynamic Range Radiance Fields
Aug 14, 2022

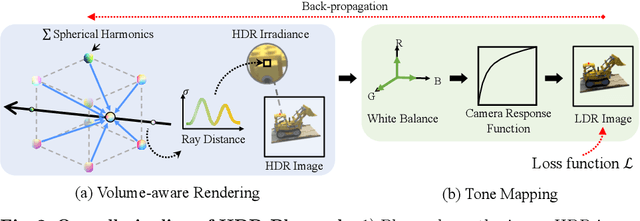
We propose high dynamic range radiance (HDR) fields, HDR-Plenoxels, that learn a plenoptic function of 3D HDR radiance fields, geometry information, and varying camera settings inherent in 2D low dynamic range (LDR) images. Our voxel-based volume rendering pipeline reconstructs HDR radiance fields with only multi-view LDR images taken from varying camera settings in an end-to-end manner and has a fast convergence speed. To deal with various cameras in real-world scenarios, we introduce a tone mapping module that models the digital in-camera imaging pipeline (ISP) and disentangles radiometric settings. Our tone mapping module allows us to render by controlling the radiometric settings of each novel view. Finally, we build a multi-view dataset with varying camera conditions, which fits our problem setting. Our experiments show that HDR-Plenoxels can express detail and high-quality HDR novel views from only LDR images with various cameras.
FedPara: Low-rank Hadamard Product Parameterization for Efficient Federated Learning
Aug 13, 2021

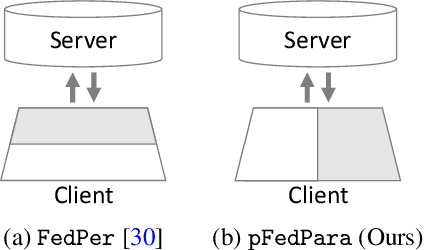

To overcome the burdens on frequent model uploads and downloads during federated learning (FL), we propose a communication-efficient re-parameterization, FedPara. Our method re-parameterizes the model's layers using low-rank matrices or tensors followed by the Hadamard product. Different from the conventional low-rank parameterization, our method is not limited to low-rank constraints. Thereby, our FedPara has a larger capacity than the low-rank one, even with the same number of parameters. It can achieve comparable performance to the original models while requiring 2.8 to 10.1 times lower communication costs than the original models, which is not achievable by the traditional low-rank parameterization. Moreover, the efficiency can be further improved by combining our method and other efficient FL techniques because our method is compatible with others. We also extend our method to a personalized FL application, pFedPara, which separates parameters into global and local ones. We show that pFedPara outperforms competing personalized FL methods with more than three times fewer parameters.