 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempered Self-Similarity Alignment for Physically Plausible Video Generation
May 24, 2026Despite remarkable advances in video generative models, they still struggle to generate physically realistic videos, frequently exhibiting appearance drift, implausible motion, and temporal inconsistencies. In this work, we address this limitation by transferring relational knowledge encoded in spatio-temporal self-similarity (STSS) from visual foundation models into video generative models. STSS represents pairwise similarities among features across space and time, revealing the relational structure of how objects interact with other entities throughout a video, effectively capturing real-world dynamics, including object motion and semantic transformations. To transfer this relational knowledge, we propose Tempered Self-similarity Alignment (TSA) loss, which transforms STSS into probabilistic correspondence distributions and trains the video generative model to align its correspondence distributions with those of the visual foundation model on dynamically changing regions. Evaluated on VideoPhy and VideoPhy2 benchmarks, our method demonstrates substantial improvements in physical plausibility across diverse interaction scenarios, validating the effectiveness of transferring relational knowledge for physically realistic video generation.
Robust Promptable Video Object Segmentation
May 12, 2026The performance of promptable video object segmentation (PVOS) models substantially degrades under input corruptions, which prevents PVOS deployment in safety-critical domains. This paper offers the first comprehensive study on robust PVOS (RobustPVOS). We first construct a new, comprehensive benchmark with two real-world evaluation datasets of 351 video clips and more than 2,500 object masks under real-world adverse conditions. At the same time, we generate synthetic training data by applying diverse and temporally varying corruptions to existing VOS datasets. Moreover, we present a new RobustPVOS method, dubbed Memory-object-conditioned Gated-rank Adaptation (MoGA). The key to successfully performing RobustPVOS is two-fold: effectively handling object-specific degradation and ensuring temporal consistency in predictions. MoGA leverages object-specific representations maintained in memory across frames to condition the robustification process, which allows the model to handle each tracked object differently in a temporally consistent way. Extensive experiments on our benchmark validate MoGA's efficacy, showing consistent and significant improvements across diverse corruption types on both synthetic and real-world datasets, establishing a strong baseline for future RobustPVOS research. Our benchmark is publicly available at https://sohyun-l.github.io/RobustPVOS_project_page/.
Structured State-Space Regularization for Compact and Generation-Friendly Image Tokenization
Apr 13, 2026Image tokenizers are central to modern vision models as they often operate in latent spaces. An ideal latent space must be simultaneously compact and generation-friendly: it should capture image's essential content compactly while remaining easy to model with generative approaches. In this work, we introduce a novel regularizer to align latent spaces with these two objectives. The key idea is to guide tokenizers to mimic the hidden state dynamics of state-space models (SSMs), thereby transferring their critical property, frequency awareness, to latent features. Grounded in a theoretical analysis of SSMs, our regularizer enforces encoding of fine spatial structures and frequency-domain cues into compact latent features; leading to more effective use of representation capacity and improved generative modelability. Experiments demonstrate that our method improves generation quality in diffusion models while incurring only minimal loss in reconstruction fidelity.
RePL: Pseudo-label Refinement for Semi-supervised LiDAR Semantic Segmentation
Apr 08, 2026Semi-supervised learning for LiDAR semantic segmentation often suffers from error propagation and confirmation bias caused by noisy pseudo-labels. To tackle this chronic issue, we introduce RePL, a novel framework that enhances pseudo-label quality by identifying and correcting potential errors in pseudo-labels through masked reconstruction, along with a dedicated training strategy. We also provide a theoretical analysis demonstrating the condition under which the pseudo-label refinement is beneficial, and empirically confirm that the condition is mild and clearly met by RePL. Extensive evaluations on the nuScenes-lidarseg and SemanticKITTI datasets show that RePL improves pseudo-label quality a lot and, as a result, achieves the state of the art in LiDAR semantic segmentation.
Planning in 8 Tokens: A Compact Discrete Tokenizer for Latent World Model
Mar 05, 2026World models provide a powerful framework for simulating environment dynamics conditioned on actions or instructions, enabling downstream tasks such as action planning or policy learning. Recent approaches leverage world models as learned simulators, but its application to decision-time planning remains computationally prohibitive for real-time control. A key bottleneck lies in latent representations: conventional tokenizers encode each observation into hundreds of tokens, making planning both slow and resource-intensive. To address this, we propose CompACT, a discrete tokenizer that compresses each observation into as few as 8 tokens, drastically reducing computational cost while preserving essential information for planning. An action-conditioned world model that occupies CompACT tokenizer achieves competitive planning performance with orders-of-magnitude faster planning, offering a practical step toward real-world deployment of world models.
TextME: Bridging Unseen Modalities Through Text Descriptions
Feb 03, 2026Expanding multimodal representations to novel modalities is constrained by reliance on large-scale paired datasets (e.g., text-image, text-audio, text-3D, text-molecule), which are costly and often infeasible in domains requiring expert annotation such as medical imaging and molecular analysis. We introduce TextME, the first text-only modality expansion framework, to the best of our knowledge, projecting diverse modalities into LLM embedding space as a unified anchor. Our approach exploits the geometric structure of pretrained contrastive encoders to enable zero-shot cross-modal transfer using only text descriptions, without paired supervision. We empirically validate that such consistent modality gaps exist across image, video, audio, 3D, X-ray, and molecular domains, demonstrating that text-only training can preserve substantial performance of pretrained encoders. We further show that our framework enables emergent cross-modal retrieval between modality pairs not explicitly aligned during training (e.g., audio-to-image, 3D-to-image). These results establish text-only training as a practical alternative to paired supervision for modality expansion.
Learned split-spectrum metalens for obstruction-free broadband imaging in the visible
Jan 27, 2026Obstructions such as raindrops, fences, or dust degrade captured images, especially when mechanical cleaning is infeasible. Conventional solutions to obstructions rely on a bulky compound optics array or computational inpainting, which compromise compactness or fidelity. Metalenses composed of subwavelength meta-atoms promise compact imaging, but simultaneous achievement of broadband and obstruction-free imaging remains a challenge, since a metalens that images distant scenes across a broadband spectrum cannot properly defocus near-depth occlusions. Here, we introduce a learned split-spectrum metalens that enables broadband obstruction-free imaging. Our approach divides the spectrum of each RGB channel into pass and stop bands with multi-band spectral filtering and learns the metalens to focus light from far objects through pass bands, while filtering focused near-depth light through stop bands. This optical signal is further enhanced using a neural network. Our learned split-spectrum metalens achieves broadband and obstruction-free imaging with relative PSNR gains of 32.29% and improves object detection and semantic segmentation accuracies with absolute gains of +13.54% mAP, +48.45% IoU, and +20.35% mIoU over a conventional hyperbolic design. This promises robust obstruction-free sensing and vision for space-constrained systems, such as mobile robots, drones, and endoscopes.
VIRO: Robust and Efficient Neuro-Symbolic Reasoning with Verification for Referring Expression Comprehension
Jan 19, 2026Referring Expression Comprehension (REC) aims to localize the image region corresponding to a natural-language query. Recent neuro-symbolic REC approaches leverage large language models (LLMs) and vision-language models (VLMs) to perform compositional reasoning, decomposing queries 4 structured programs and executing them step-by-step. While such approaches achieve interpretable reasoning and strong zero-shot generalization, they assume that intermediate reasoning steps are accurate. However, this assumption causes cascading errors: false detections and invalid relations propagate through the reasoning chain, yielding high-confidence false positives even when no target is present in the image. To address this limitation, we introduce Verification-Integrated Reasoning Operators (VIRO), a neuro-symbolic framework that embeds lightweight operator-level verifiers within reasoning steps. Each operator executes and validates its output, such as object existence or spatial relationship, thereby allowing the system to robustly handle no-target cases when verification conditions are not met. Our framework achieves state-of-the-art performance, reaching 61.1% balanced accuracy across target-present and no-target settings, and demonstrates generalization to real-world egocentric data. Furthermore, VIRO shows superior computational efficiency in terms of throughput, high reliability with a program failure rate of less than 0.3%, and scalability through decoupled program generation from execution.
Part-Aware Bottom-Up Group Reasoning for Fine-Grained Social Interaction Detection
Nov 05, 2025


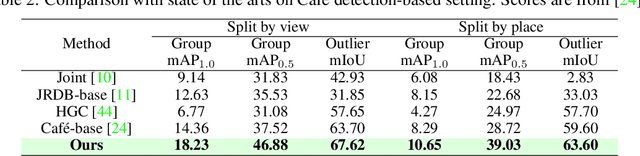
Social interactions often emerge from subtle, fine-grained cues such as facial expressions, gaze, and gestures. However, existing methods for social interaction detection overlook such nuanced cues and primarily rely on holistic representations of individuals. Moreover, they directly detect social groups without explicitly modeling the underlying interactions between individuals. These drawbacks limit their ability to capture localized social signals and introduce ambiguity when group configurations should be inferred from social interactions grounded in nuanced cues. In this work, we propose a part-aware bottom-up group reasoning framework for fine-grained social interaction detection. The proposed method infers social groups and their interactions using body part features and their interpersonal relations. Our model first detects individuals and enhances their features using part-aware cues, and then infers group configuration by associating individuals via similarity-based reasoning, which considers not only spatial relations but also subtle social cues that signal interactions, leading to more accurate group inference. Experiments on the NVI dataset demonstrate that our method outperforms prior methods, achieving the new state of the art.
Improving Sound Source Localization with Joint Slot Attention on Image and Audio
Apr 21, 2025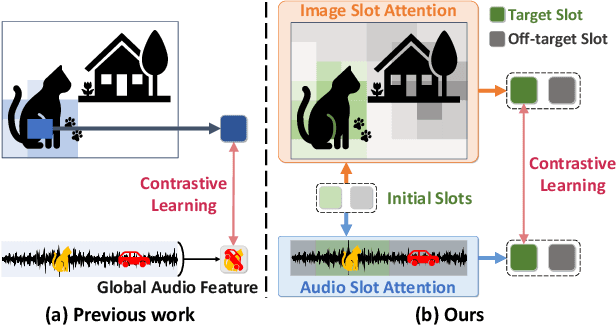
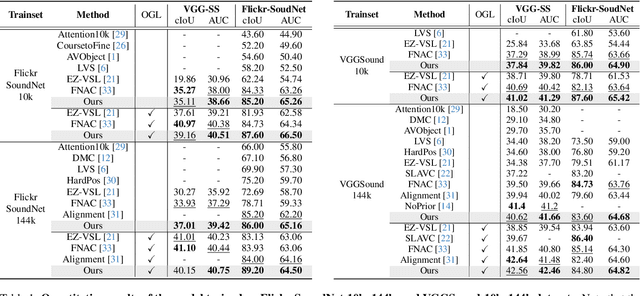
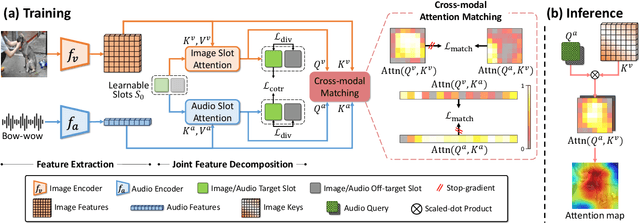
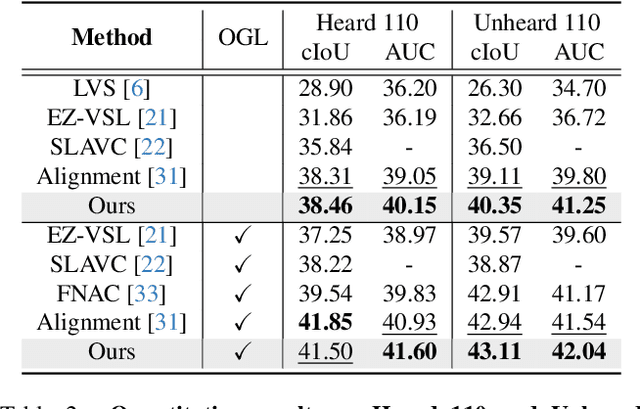
Sound source localization (SSL) is the task of locating the source of sound within an image. Due to the lack of localization labels, the de facto standard in SSL has been to represent an image and audio as a single embedding vector each, and use them to learn SSL via contrastive learning. To this end, previous work samples one of local image features as the image embedding and aggregates all local audio features to obtain the audio embedding, which is far from optimal due to the presence of noise and background irrelevant to the actual target in the input. We present a novel SSL method that addresses this chronic issue by joint slot attention on image and audio. To be specific, two slots competitively attend image and audio features to decompose them into target and off-target representations, and only target representations of image and audio are used for contrastive learning. Also, we introduce cross-modal attention matching to further align local features of image and audio. Our method achieved the best in almost all settings on three public benchmarks for SSL, and substantially outperformed all the prior work in cross-modal retrieval.