 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeartcare Suite: Multi-dimensional Understanding of ECG with Raw Multi-lead Signal Modeling
Jun 06, 2025We present Heartcare Suite, a multimodal comprehensive framework for finegrained electrocardiogram (ECG) understanding. It comprises three key components: (i) Heartcare-220K, a high-quality, structured, and comprehensive multimodal ECG dataset covering essential tasks such as disease diagnosis, waveform morphology analysis, and rhythm interpretation. (ii) Heartcare-Bench, a systematic and multi-dimensional benchmark designed to evaluate diagnostic intelligence and guide the optimization of Medical Multimodal Large Language Models (Med-MLLMs) in ECG scenarios. and (iii) HeartcareGPT with a tailored tokenizer Bidirectional ECG Abstract Tokenization (Beat), which compresses raw multi-lead signals into semantically rich discrete tokens via duallevel vector quantization and query-guided bidirectional diffusion mechanism. Built upon Heartcare-220K, HeartcareGPT achieves strong generalization and SoTA performance across multiple clinically meaningful tasks. Extensive experiments demonstrate that Heartcare Suite is highly effective in advancing ECGspecific multimodal understanding and evaluation. Our project is available at https://github.com/Wznnnnn/Heartcare-Suite .
Deeply Supervised Flow-Based Generative Models
Mar 18, 2025Flow based generative models have charted an impressive path across multiple visual generation tasks by adhering to a simple principle: learning velocity representations of a linear interpolant. However, we observe that training velocity solely from the final layer output underutilizes the rich inter layer representations, potentially impeding model convergence. To address this limitation, we introduce DeepFlow, a novel framework that enhances velocity representation through inter layer communication. DeepFlow partitions transformer layers into balanced branches with deep supervision and inserts a lightweight Velocity Refiner with Acceleration (VeRA) block between adjacent branches, which aligns the intermediate velocity features within transformer blocks. Powered by the improved deep supervision via the internal velocity alignment, DeepFlow converges 8 times faster on ImageNet with equivalent performance and further reduces FID by 2.6 while halving training time compared to previous flow based models without a classifier free guidance. DeepFlow also outperforms baselines in text to image generation tasks, as evidenced by evaluations on MSCOCO and zero shot GenEval.
COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
Feb 04, 2025This paper introduces the COCONut-PanCap dataset, created to enhance panoptic segmentation and grounded image captioning. Building upon the COCO dataset with advanced COCONut panoptic masks, this dataset aims to overcome limitations in existing image-text datasets that often lack detailed, scene-comprehensive descriptions. The COCONut-PanCap dataset incorporates fine-grained, region-level captions grounded in panoptic segmentation masks, ensuring consistency and improving the detail of generated captions. Through human-edited, densely annotated descriptions, COCONut-PanCap supports improved training of vision-language models (VLMs) for image understanding and generative models for text-to-image tasks. Experimental results demonstrate that COCONut-PanCap significantly boosts performance across understanding and generation tasks, offering complementary benefits to large-scale datasets. This dataset sets a new benchmark for evaluating models on joint panoptic segmentation and grounded captioning tasks, addressing the need for high-quality, detailed image-text annotations in multi-modal learning.
Democratizing Text-to-Image Masked Generative Models with Compact Text-Aware One-Dimensional Tokens
Jan 13, 2025



Image tokenizers form the foundation of modern text-to-image generative models but are notoriously difficult to train. Furthermore, most existing text-to-image models rely on large-scale, high-quality private datasets, making them challenging to replicate. In this work, we introduce Text-Aware Transformer-based 1-Dimensional Tokenizer (TA-TiTok), an efficient and powerful image tokenizer that can utilize either discrete or continuous 1-dimensional tokens. TA-TiTok uniquely integrates textual information during the tokenizer decoding stage (i.e., de-tokenization), accelerating convergence and enhancing performance. TA-TiTok also benefits from a simplified, yet effective, one-stage training process, eliminating the need for the complex two-stage distillation used in previous 1-dimensional tokenizers. This design allows for seamless scalability to large datasets. Building on this, we introduce a family of text-to-image Masked Generative Models (MaskGen), trained exclusively on open data while achieving comparable performance to models trained on private data. We aim to release both the efficient, strong TA-TiTok tokenizers and the open-data, open-weight MaskGen models to promote broader access and democratize the field of text-to-image masked generative models.
1.58-bit FLUX
Dec 24, 2024We present 1.58-bit FLUX, the first successful approach to quantizing the state-of-the-art text-to-image generation model, FLUX.1-dev, using 1.58-bit weights (i.e., values in {-1, 0, +1}) while maintaining comparable performance for generating 1024 x 1024 images. Notably, our quantization method operates without access to image data, relying solely on self-supervision from the FLUX.1-dev model. Additionally, we develop a custom kernel optimized for 1.58-bit operations, achieving a 7.7x reduction in model storage, a 5.1x reduction in inference memory, and improved inference latency. Extensive evaluations on the GenEval and T2I Compbench benchmarks demonstrate the effectiveness of 1.58-bit FLUX in maintaining generation quality while significantly enhancing computational efficiency.
IG Captioner: Information Gain Captioners are Strong Zero-shot Classifiers
Nov 27, 2023



Generative training has been demonstrated to be powerful for building visual-language models. However, on zero-shot discriminative benchmarks, there is still a performance gap between models trained with generative and discriminative objectives. In this paper, we aim to narrow this gap by improving the efficacy of generative training on classification tasks, without any finetuning processes or additional modules. Specifically, we focus on narrowing the gap between the generative captioner and the CLIP classifier. We begin by analysing the predictions made by the captioner and classifier and observe that the caption generation inherits the distribution bias from the language model trained with pure text modality, making it less grounded on the visual signal. To tackle this problem, we redesign the scoring objective for the captioner to alleviate the distributional bias and focus on measuring the gain of information brought by the visual inputs. We further design a generative training objective to match the evaluation objective. We name our model trained and evaluated from the novel procedures as Information Gain (IG) captioner. We pretrain the models on the public Laion-5B dataset and perform a series of discriminative evaluations. For the zero-shot classification on ImageNet, IG captioner achieves $> 18\%$ improvements over the standard captioner, achieving comparable performances with the CLIP classifier. IG captioner also demonstrated strong performance on zero-shot image-text retrieval tasks on MSCOCO and Flickr30K. We hope this paper inspires further research towards unifying generative and discriminative training procedures for visual-language models.
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
Oct 04, 2022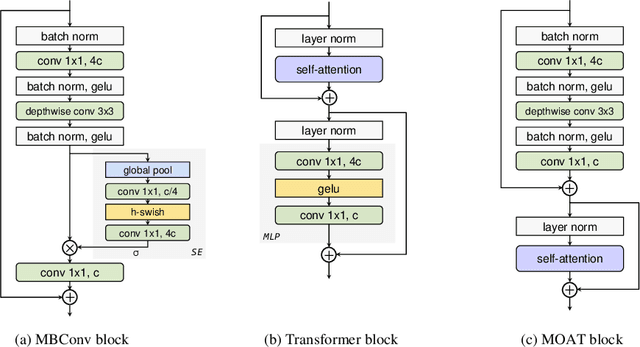

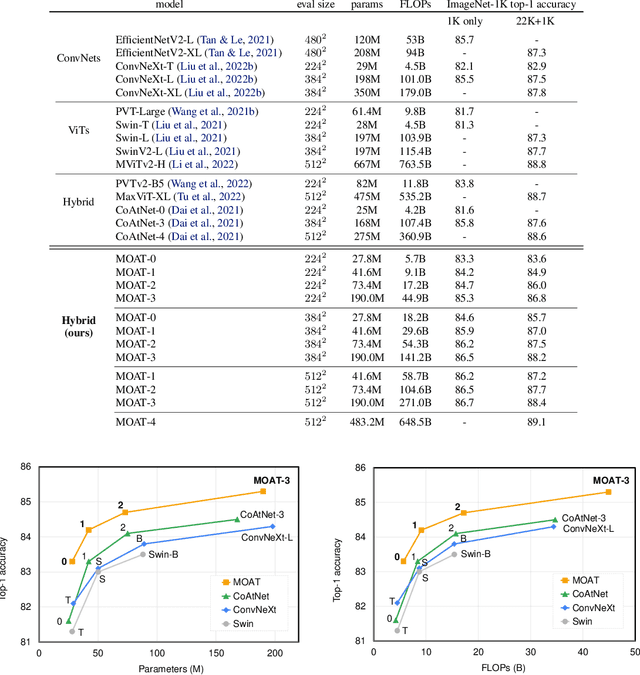
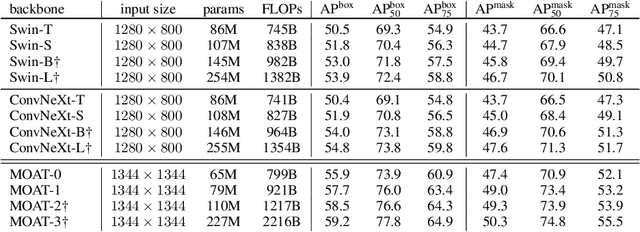
This paper presents MOAT, a family of neural networks that build on top of MObile convolution (i.e., inverted residual blocks) and ATtention. Unlike the current works that stack separate mobile convolution and transformer blocks, we effectively merge them into a MOAT block. Starting with a standard Transformer block, we replace its multi-layer perceptron with a mobile convolution block, and further reorder it before the self-attention operation. The mobile convolution block not only enhances the network representation capacity, but also produces better downsampled features. Our conceptually simple MOAT networks are surprisingly effective, achieving 89.1% top-1 accuracy on ImageNet-1K with ImageNet-22K pretraining. Additionally, MOAT can be seamlessly applied to downstream tasks that require large resolution inputs by simply converting the global attention to window attention. Thanks to the mobile convolution that effectively exchanges local information between pixels (and thus cross-windows), MOAT does not need the extra window-shifting mechanism. As a result, on COCO object detection, MOAT achieves 59.2% box AP with 227M model parameters (single-scale inference, and hard NMS), and on ADE20K semantic segmentation, MOAT attains 57.6% mIoU with 496M model parameters (single-scale inference). Finally, the tiny-MOAT family, obtained by simply reducing the channel sizes, also surprisingly outperforms several mobile-specific transformer-based models on ImageNet. We hope our simple yet effective MOAT will inspire more seamless integration of convolution and self-attention. Code is made publicly available.
Lite Vision Transformer with Enhanced Self-Attention
Dec 20, 2021
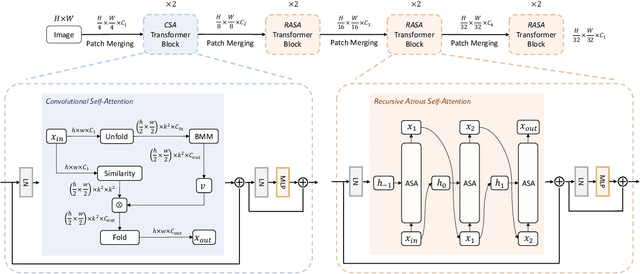
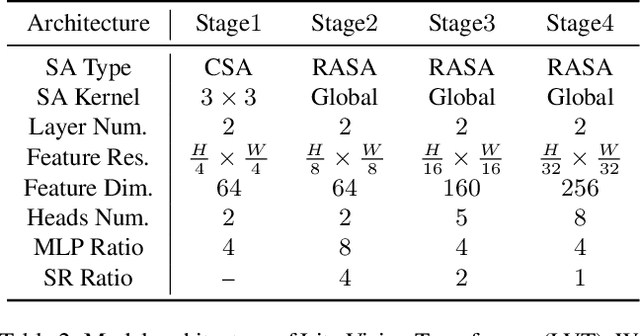
Despite the impressive representation capacity of vision transformer models, current light-weight vision transformer models still suffer from inconsistent and incorrect dense predictions at local regions. We suspect that the power of their self-attention mechanism is limited in shallower and thinner networks. We propose Lite Vision Transformer (LVT), a novel light-weight transformer network with two enhanced self-attention mechanisms to improve the model performances for mobile deployment. For the low-level features, we introduce Convolutional Self-Attention (CSA). Unlike previous approaches of merging convolution and self-attention, CSA introduces local self-attention into the convolution within a kernel of size 3x3 to enrich low-level features in the first stage of LVT. For the high-level features, we propose Recursive Atrous Self-Attention (RASA), which utilizes the multi-scale context when calculating the similarity map and a recursive mechanism to increase the representation capability with marginal extra parameter cost. The superiority of LVT is demonstrated on ImageNet recognition, ADE20K semantic segmentation, and COCO panoptic segmentation. The code is made publicly available.
Locally Enhanced Self-Attention: Rethinking Self-Attention as Local and Context Terms
Jul 12, 2021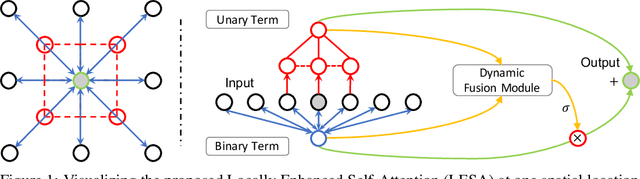

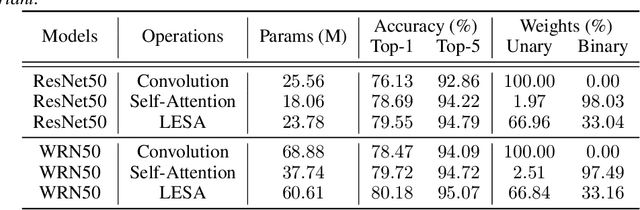
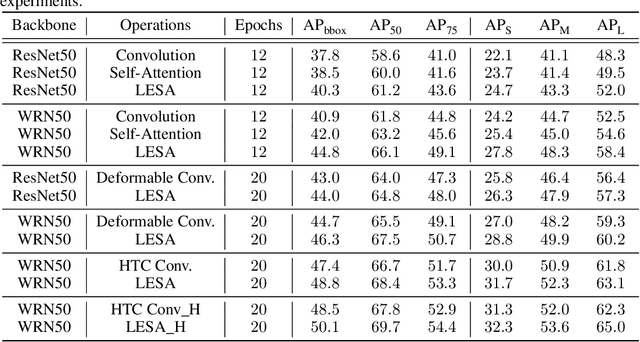
Self-Attention has become prevalent in computer vision models. Inspired by fully connected Conditional Random Fields (CRFs), we decompose it into local and context terms. They correspond to the unary and binary terms in CRF and are implemented by attention mechanisms with projection matrices. We observe that the unary terms only make small contributions to the outputs, and meanwhile standard CNNs that rely solely on the unary terms achieve great performances on a variety of tasks. Therefore, we propose Locally Enhanced Self-Attention (LESA), which enhances the unary term by incorporating it with convolutions, and utilizes a fusion module to dynamically couple the unary and binary operations. In our experiments, we replace the self-attention modules with LESA. The results on ImageNet and COCO show the superiority of LESA over convolution and self-attention baselines for the tasks of image recognition, object detection, and instance segmentation. The code is made publicly available.
Meticulous Object Segmentation
Dec 13, 2020Compared with common image segmentation tasks targeted at low-resolution images, higher resolution detailed image segmentation receives much less attention. In this paper, we propose and study a task named Meticulous Object Segmentation (MOS), which is focused on segmenting well-defined foreground objects with elaborate shapes in high resolution images (e.g. 2k - 4k). To this end, we propose the MeticulousNet which leverages a dedicated decoder to capture the object boundary details. Specifically, we design a Hierarchical Point-wise Refining (HierPR) block to better delineate object boundaries, and reformulate the decoding process as a recursive coarse to fine refinement of the object mask. To evaluate segmentation quality near object boundaries, we propose the Meticulosity Quality (MQ) score considering both the mask coverage and boundary precision. In addition, we collect a MOS benchmark dataset including 600 high quality images with complex objects. We provide comprehensive empirical evidence showing that MeticulousNet can reveal pixel-accurate segmentation boundaries and is superior to state-of-the-art methods for high resolution object segmentation tasks.