 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamFreeDiff: Camera-free Image to Panorama Generation with Diffusion Model
Jul 09, 2024



This paper introduces Camera-free Diffusion (CamFreeDiff) model for 360-degree image outpainting from a single camera-free image and text description. This method distinguishes itself from existing strategies, such as MVDiffusion, by eliminating the requirement for predefined camera poses. Instead, our model incorporates a mechanism for predicting homography directly within the multi-view diffusion framework. The core of our approach is to formulate camera estimation by predicting the homography transformation from the input view to a predefined canonical view. The homography provides point-level correspondences between the input image and targeting panoramic images, allowing connections enforced by correspondence-aware attention in a fully differentiable manner. Qualitative and quantitative experimental results demonstrate our model's strong robustness and generalization ability for 360-degree image outpainting in the challenging context of camera-free inputs.
Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior
Jan 17, 2024Score distillation sampling (SDS) and its variants have greatly boosted the development of text-to-3D generation, but are vulnerable to geometry collapse and poor textures yet. To solve this issue, we first deeply analyze the SDS and find that its distillation sampling process indeed corresponds to the trajectory sampling of a stochastic differential equation (SDE): SDS samples along an SDE trajectory to yield a less noisy sample which then serves as a guidance to optimize a 3D model. However, the randomness in SDE sampling often leads to a diverse and unpredictable sample which is not always less noisy, and thus is not a consistently correct guidance, explaining the vulnerability of SDS. Since for any SDE, there always exists an ordinary differential equation (ODE) whose trajectory sampling can deterministically and consistently converge to the desired target point as the SDE, we propose a novel and effective "Consistent3D" method that explores the ODE deterministic sampling prior for text-to-3D generation. Specifically, at each training iteration, given a rendered image by a 3D model, we first estimate its desired 3D score function by a pre-trained 2D diffusion model, and build an ODE for trajectory sampling. Next, we design a consistency distillation sampling loss which samples along the ODE trajectory to generate two adjacent samples and uses the less noisy sample to guide another more noisy one for distilling the deterministic prior into the 3D model. Experimental results show the efficacy of our Consistent3D in generating high-fidelity and diverse 3D objects and large-scale scenes, as shown in Fig. 1. The codes are available at https://github.com/sail-sg/Consistent3D.
Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape
Aug 22, 2023



Accurately estimating the 3D pose and shape is an essential step towards understanding animal behavior, and can potentially benefit many downstream applications, such as wildlife conservation. However, research in this area is held back by the lack of a comprehensive and diverse dataset with high-quality 3D pose and shape annotations. In this paper, we propose Animal3D, the first comprehensive dataset for mammal animal 3D pose and shape estimation. Animal3D consists of 3379 images collected from 40 mammal species, high-quality annotations of 26 keypoints, and importantly the pose and shape parameters of the SMAL model. All annotations were labeled and checked manually in a multi-stage process to ensure highest quality results. Based on the Animal3D dataset, we benchmark representative shape and pose estimation models at: (1) supervised learning from only the Animal3D data, (2) synthetic to real transfer from synthetically generated images, and (3) fine-tuning human pose and shape estimation models. Our experimental results demonstrate that predicting the 3D shape and pose of animals across species remains a very challenging task, despite significant advances in human pose estimation. Our results further demonstrate that synthetic pre-training is a viable strategy to boost the model performance. Overall, Animal3D opens new directions for facilitating future research in animal 3D pose and shape estimation, and is publicly available.
Robust Category-Level 3D Pose Estimation from Synthetic Data
May 25, 2023Obtaining accurate 3D object poses is vital for numerous computer vision applications, such as 3D reconstruction and scene understanding. However, annotating real-world objects is time-consuming and challenging. While synthetically generated training data is a viable alternative, the domain shift between real and synthetic data is a significant challenge. In this work, we aim to narrow the performance gap between models trained on synthetic data and few real images and fully supervised models trained on large-scale data. We achieve this by approaching the problem from two perspectives: 1) We introduce SyntheticP3D, a new synthetic dataset for object pose estimation generated from CAD models and enhanced with a novel algorithm. 2) We propose a novel approach (CC3D) for training neural mesh models that perform pose estimation via inverse rendering. In particular, we exploit the spatial relationships between features on the mesh surface and a contrastive learning scheme to guide the domain adaptation process. Combined, these two approaches enable our models to perform competitively with state-of-the-art models using only 10% of the respective real training images, while outperforming the SOTA model by 10.4% with a threshold of pi/18 using only 50% of the real training data. Our trained model further demonstrates robust generalization to out-of-distribution scenarios despite being trained with minimal real data.
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
Oct 04, 2022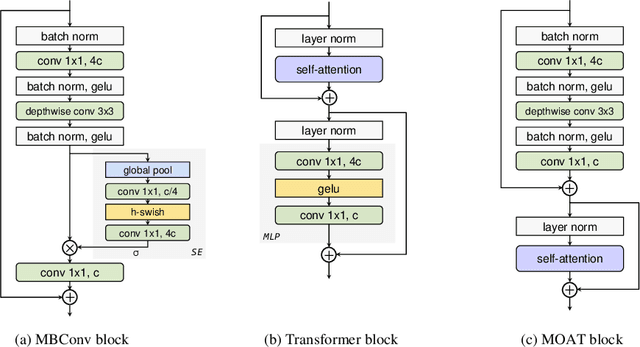

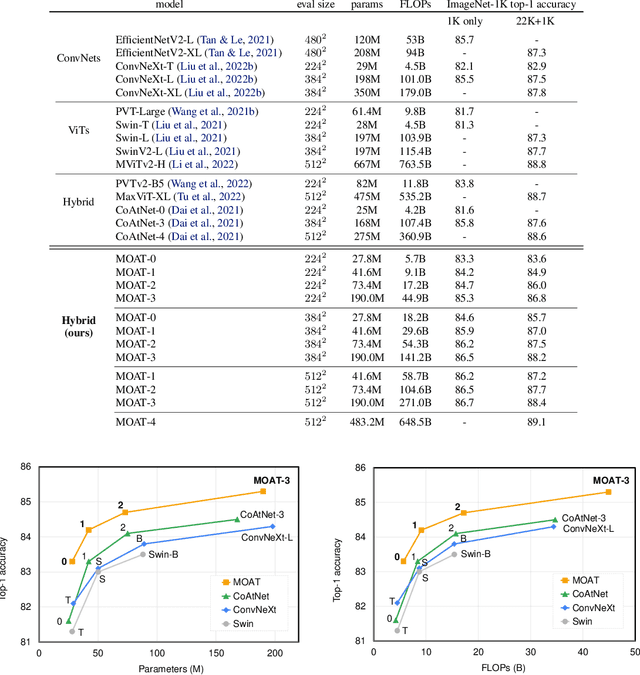
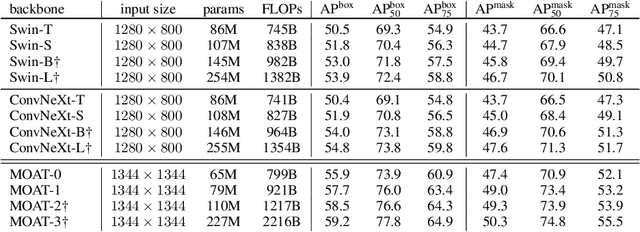
This paper presents MOAT, a family of neural networks that build on top of MObile convolution (i.e., inverted residual blocks) and ATtention. Unlike the current works that stack separate mobile convolution and transformer blocks, we effectively merge them into a MOAT block. Starting with a standard Transformer block, we replace its multi-layer perceptron with a mobile convolution block, and further reorder it before the self-attention operation. The mobile convolution block not only enhances the network representation capacity, but also produces better downsampled features. Our conceptually simple MOAT networks are surprisingly effective, achieving 89.1% top-1 accuracy on ImageNet-1K with ImageNet-22K pretraining. Additionally, MOAT can be seamlessly applied to downstream tasks that require large resolution inputs by simply converting the global attention to window attention. Thanks to the mobile convolution that effectively exchanges local information between pixels (and thus cross-windows), MOAT does not need the extra window-shifting mechanism. As a result, on COCO object detection, MOAT achieves 59.2% box AP with 227M model parameters (single-scale inference, and hard NMS), and on ADE20K semantic segmentation, MOAT attains 57.6% mIoU with 496M model parameters (single-scale inference). Finally, the tiny-MOAT family, obtained by simply reducing the channel sizes, also surprisingly outperforms several mobile-specific transformer-based models on ImageNet. We hope our simple yet effective MOAT will inspire more seamless integration of convolution and self-attention. Code is made publicly available.
PartImageNet: A Large, High-Quality Dataset of Parts
Dec 02, 2021
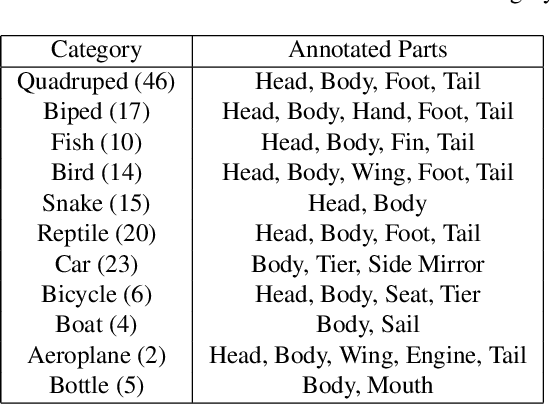

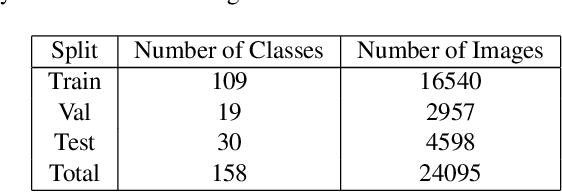
A part-based object understanding facilitates efficient compositional learning and knowledge transfer, robustness to occlusion, and has the potential to increase the performance on general recognition and localization tasks. However, research on part-based models is hindered due to the lack of datasets with part annotations, which is caused by the extreme difficulty and high cost of annotating object parts in images. In this paper, we propose PartImageNet, a large, high-quality dataset with part segmentation annotations. It consists of 158 classes from ImageNet with approximately 24000 images. PartImageNet is unique because it offers part-level annotations on a general set of classes with non-rigid, articulated objects, while having an order of magnitude larger size compared to existing datasets. It can be utilized in multiple vision tasks including but not limited to: Part Discovery, Semantic Segmentation, Few-shot Learning. Comprehensive experiments are conducted to set up a set of baselines on PartImageNet and we find that existing works on part discovery can not always produce satisfactory results during complex variations. The exploit of parts on downstream tasks also remains insufficient. We believe that our PartImageNet will greatly facilitate the research on part-based models and their applications. The dataset and scripts will soon be released at https://github.com/TACJu/PartImageNet.
CGPart: A Part Segmentation Dataset Based on 3D Computer Graphics Models
Mar 25, 2021
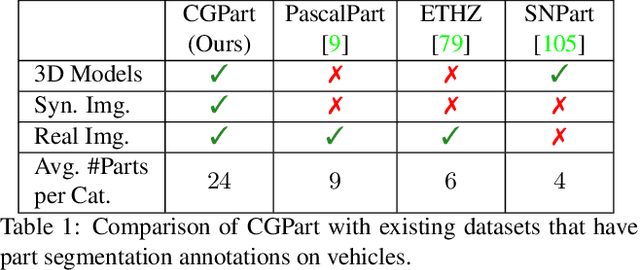
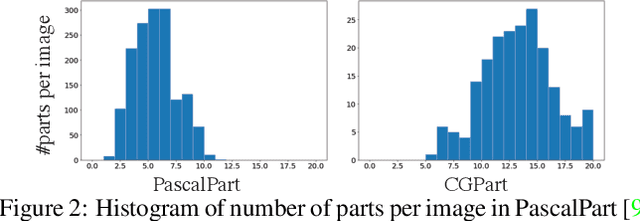
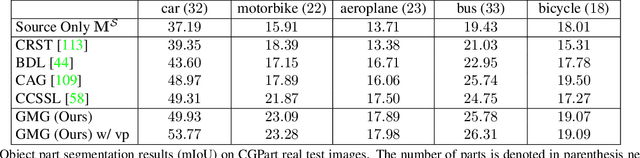
Part segmentations provide a rich and detailed part-level description of objects, but their annotation requires an enormous amount of work. In this paper, we introduce CGPart, a comprehensive part segmentation dataset that provides detailed annotations on 3D CAD models, synthetic images, and real test images. CGPart includes $21$ 3D CAD models covering $5$ vehicle categories, each with detailed per-mesh part labeling. The average number of parts per category is $24$, which is larger than any existing datasets for part segmentation on vehicle objects. By varying the rendering parameters, we make $168,000$ synthetic images from these CAD models, each with automatically generated part segmentation ground-truth. We also annotate part segmentations on $200$ real images for evaluation purposes. To illustrate the value of CGPart, we apply it to image part segmentation through unsupervised domain adaptation (UDA). We evaluate several baseline methods by adapting top-performing UDA algorithms from related tasks to part segmentation. Moreover, we introduce a new method called Geometric-Matching Guided domain adaptation (GMG), which leverages the spatial object structure to guide the knowledge transfer from the synthetic to the real images. Experimental results demonstrate the advantage of our new algorithm and reveal insights for future improvement. We will release our data and code.
Robust Instance Segmentation through Reasoning about Multi-Object Occlusion
Dec 03, 2020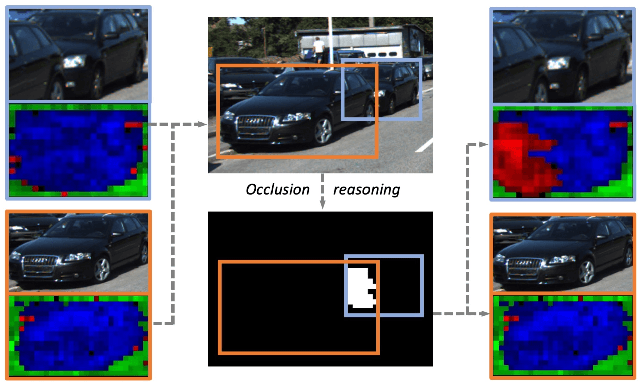
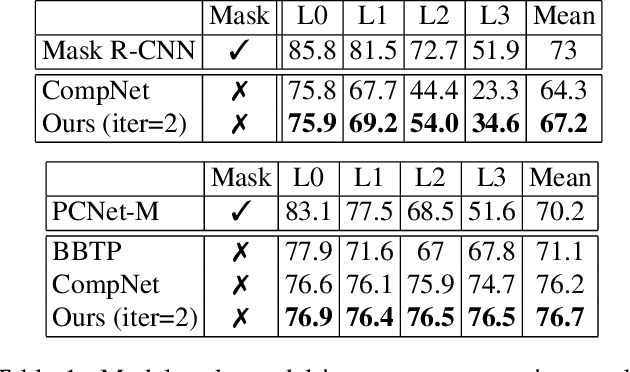
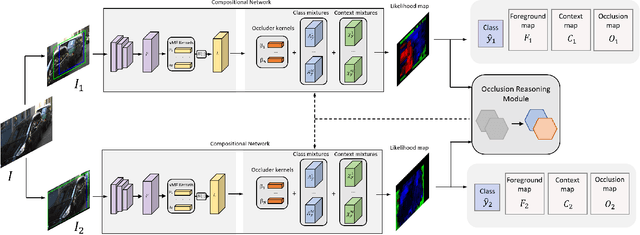
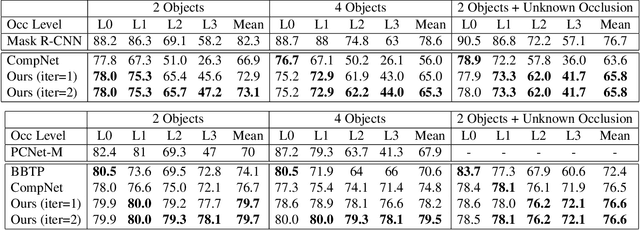
Analyzing complex scenes with Deep Neural Networks is a challenging task, particularly when images contain multiple objects that partially occlude each other. Existing approaches to image analysis mostly process objects independently and do not take into account the relative occlusion of nearby objects. In this paper, we propose a deep network for multi-object instance segmentation that is robust to occlusion and can be trained from bounding box supervision only. Our work builds on Compositional Networks, which learn a generative model of neural feature activations to locate occluders and to classify objects based on their non-occluded parts. We extend their generative model to include multiple objects and introduce a framework for the efficient inference in challenging occlusion scenarios. In particular, we obtain feed-forward predictions of the object classes and their instance and occluder segmentations. We introduce an Occlusion Reasoning Module (ORM) that locates erroneous segmentations and estimates the occlusion ordering to correct them. The improved segmentation masks are, in turn, integrated into the network in a top-down manner to improve the image classification. Our experiments on the KITTI INStance dataset (KINS) and a synthetic occlusion dataset demonstrate the effectiveness and robustness of our model at multi-object instance segmentation under occlusion.