 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSevolve: Enabling Real-Time Adaptive Scheduling on Dynamic Shop Floor with LLM-Evolved Heuristic Portfolios
Mar 29, 2026In dynamic manufacturing environments, disruptions such as machine breakdowns and new order arrivals continuously shift the optimal dispatching strategy, making adaptive rule selection essential. Existing LLM-powered Automatic Heuristic Design (AHD) frameworks evolve toward a single elite rule that cannot meet this adaptability demand. To address this, we present DSevolve, an industrial scheduling framework that evolves a quality-diverse portfolio of dispatching rules offline and adaptively deploys them online with second-level response time. Multi-persona seeding and topology-aware evolutionary operators produce a behaviorally diverse rule archive indexed by a MAP-Elites feature space. Upon each disruption event, a probe-based fingerprinting mechanism characterizes the current shop floor state, retrieves high-quality candidate rules from an offline knowledge base, and selects the best one via rapid look-ahead simulation. Evaluated on 500 dynamic flexible job shop instances derived from real industrial data, DSevolve outperforms state-of-the-art AHD frameworks, classical dispatching rules, genetic programming, and deep reinforcement learning, offering a practical and deployable solution for intelligent shop floor scheduling.
Autoregressive Image Generation with Masked Bit Modeling
Feb 09, 2026This paper challenges the dominance of continuous pipelines in visual generation. We systematically investigate the performance gap between discrete and continuous methods. Contrary to the belief that discrete tokenizers are intrinsically inferior, we demonstrate that the disparity arises primarily from the total number of bits allocated in the latent space (i.e., the compression ratio). We show that scaling up the codebook size effectively bridges this gap, allowing discrete tokenizers to match or surpass their continuous counterparts. However, existing discrete generation methods struggle to capitalize on this insight, suffering from performance degradation or prohibitive training costs with scaled codebook. To address this, we propose masked Bit AutoRegressive modeling (BAR), a scalable framework that supports arbitrary codebook sizes. By equipping an autoregressive transformer with a masked bit modeling head, BAR predicts discrete tokens through progressively generating their constituent bits. BAR achieves a new state-of-the-art gFID of 0.99 on ImageNet-256, outperforming leading methods across both continuous and discrete paradigms, while significantly reducing sampling costs and converging faster than prior continuous approaches. Project page is available at https://bar-gen.github.io/
Generative Adversarial Reasoner: Enhancing LLM Reasoning with Adversarial Reinforcement Learning
Dec 18, 2025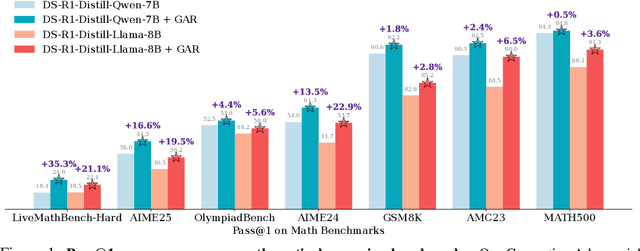

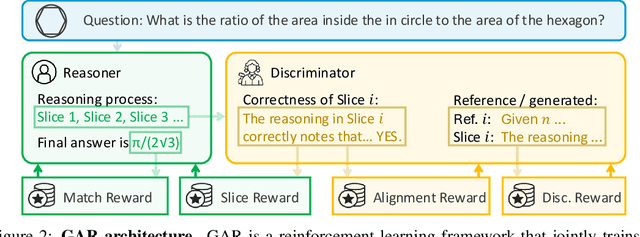

Large language models (LLMs) with explicit reasoning capabilities excel at mathematical reasoning yet still commit process errors, such as incorrect calculations, brittle logic, and superficially plausible but invalid steps. In this paper, we introduce Generative Adversarial Reasoner, an on-policy joint training framework designed to enhance reasoning by co-evolving an LLM reasoner and an LLM-based discriminator through adversarial reinforcement learning. A compute-efficient review schedule partitions each reasoning chain into logically complete slices of comparable length, and the discriminator evaluates each slice's soundness with concise, structured justifications. Learning couples complementary signals: the LLM reasoner is rewarded for logically consistent steps that yield correct answers, while the discriminator earns rewards for correctly detecting errors or distinguishing traces in the reasoning process. This produces dense, well-calibrated, on-policy step-level rewards that supplement sparse exact-match signals, improving credit assignment, increasing sample efficiency, and enhancing overall reasoning quality of LLMs. Across various mathematical benchmarks, the method delivers consistent gains over strong baselines with standard RL post-training. Specifically, on AIME24, we improve DeepSeek-R1-Distill-Qwen-7B from 54.0 to 61.3 (+7.3) and DeepSeek-R1-Distill-Llama-8B from 43.7 to 53.7 (+10.0). The modular discriminator also enables flexible reward shaping for objectives such as teacher distillation, preference alignment, and mathematical proof-based reasoning.
Differences That Matter: Auditing Models for Capability Gap Discovery and Rectification
Dec 18, 2025

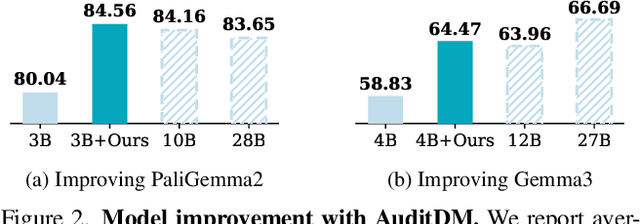
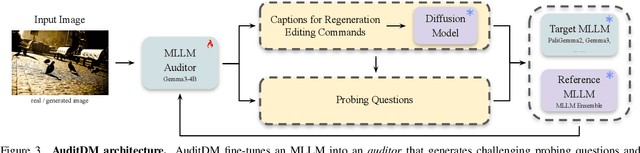
Conventional evaluation methods for multimodal LLMs (MLLMs) lack interpretability and are often insufficient to fully disclose significant capability gaps across models. To address this, we introduce AuditDM, an automated framework that actively discovers and rectifies MLLM failure modes by auditing their divergence. AuditDM fine-tunes an MLLM as an auditor via reinforcement learning to generate challenging questions and counterfactual images that maximize disagreement among target models. Once trained, the auditor uncovers diverse, interpretable exemplars that reveal model weaknesses and serve as annotation-free data for rectification. When applied to SoTA models like Gemma-3 and PaliGemma-2, AuditDM discovers more than 20 distinct failure types. Fine-tuning on these discoveries consistently improves all models across 16 benchmarks, and enables a 3B model to surpass its 28B counterpart. Our results suggest that as data scaling hits diminishing returns, targeted model auditing offers an effective path to model diagnosis and improvement.
ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction
Apr 30, 2025In recent years, video generation has seen significant advancements. However, challenges still persist in generating complex motions and interactions. To address these challenges, we introduce ReVision, a plug-and-play framework that explicitly integrates parameterized 3D physical knowledge into a pretrained conditional video generation model, significantly enhancing its ability to generate high-quality videos with complex motion and interactions. Specifically, ReVision consists of three stages. First, a video diffusion model is used to generate a coarse video. Next, we extract a set of 2D and 3D features from the coarse video to construct a 3D object-centric representation, which is then refined by our proposed parameterized physical prior model to produce an accurate 3D motion sequence. Finally, this refined motion sequence is fed back into the same video diffusion model as additional conditioning, enabling the generation of motion-consistent videos, even in scenarios involving complex actions and interactions. We validate the effectiveness of our approach on Stable Video Diffusion, where ReVision significantly improves motion fidelity and coherence. Remarkably, with only 1.5B parameters, it even outperforms a state-of-the-art video generation model with over 13B parameters on complex video generation by a substantial margin. Our results suggest that, by incorporating 3D physical knowledge, even a relatively small video diffusion model can generate complex motions and interactions with greater realism and controllability, offering a promising solution for physically plausible video generation.
SpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning
Apr 28, 2025



Recent studies in 3D spatial reasoning explore data-driven approaches and achieve enhanced spatial reasoning performance with reinforcement learning (RL). However, these methods typically perform spatial reasoning in an implicit manner, and it remains underexplored whether the acquired 3D knowledge generalizes to unseen question types at any stage of the training. In this work we introduce SpatialReasoner, a novel large vision-language model (LVLM) that address 3D spatial reasoning with explicit 3D representations shared between stages -- 3D perception, computation, and reasoning. Explicit 3D representations provide a coherent interface that supports advanced 3D spatial reasoning and enable us to study the factual errors made by LVLMs. Results show that our SpatialReasoner achieve improved performance on a variety of spatial reasoning benchmarks and generalizes better when evaluating on novel 3D spatial reasoning questions. Our study bridges the 3D parsing capabilities of prior visual foundation models with the powerful reasoning abilities of large language models, opening new directions for 3D spatial reasoning.
Automatic MILP Model Construction for Multi-Robot Task Allocation and Scheduling Based on Large Language Models
Mar 18, 2025With the accelerated development of Industry 4.0, intelligent manufacturing systems increasingly require efficient task allocation and scheduling in multi-robot systems. However, existing methods rely on domain expertise and face challenges in adapting to dynamic production constraints. Additionally, enterprises have high privacy requirements for production scheduling data, which prevents the use of cloud-based large language models (LLMs) for solution development. To address these challenges, there is an urgent need for an automated modeling solution that meets data privacy requirements. This study proposes a knowledge-augmented mixed integer linear programming (MILP) automated formulation framework, integrating local LLMs with domain-specific knowledge bases to generate executable code from natural language descriptions automatically. The framework employs a knowledge-guided DeepSeek-R1-Distill-Qwen-32B model to extract complex spatiotemporal constraints (82% average accuracy) and leverages a supervised fine-tuned Qwen2.5-Coder-7B-Instruct model for efficient MILP code generation (90% average accuracy). Experimental results demonstrate that the framework successfully achieves automatic modeling in the aircraft skin manufacturing case while ensuring data privacy and computational efficiency. This research provides a low-barrier and highly reliable technical path for modeling in complex industrial scenarios.
FlowTok: Flowing Seamlessly Across Text and Image Tokens
Mar 13, 2025Bridging different modalities lies at the heart of cross-modality generation. While conventional approaches treat the text modality as a conditioning signal that gradually guides the denoising process from Gaussian noise to the target image modality, we explore a much simpler paradigm-directly evolving between text and image modalities through flow matching. This requires projecting both modalities into a shared latent space, which poses a significant challenge due to their inherently different representations: text is highly semantic and encoded as 1D tokens, whereas images are spatially redundant and represented as 2D latent embeddings. To address this, we introduce FlowTok, a minimal framework that seamlessly flows across text and images by encoding images into a compact 1D token representation. Compared to prior methods, this design reduces the latent space size by 3.3x at an image resolution of 256, eliminating the need for complex conditioning mechanisms or noise scheduling. Moreover, FlowTok naturally extends to image-to-text generation under the same formulation. With its streamlined architecture centered around compact 1D tokens, FlowTok is highly memory-efficient, requires significantly fewer training resources, and achieves much faster sampling speeds-all while delivering performance comparable to state-of-the-art models. Code will be available at https://github.com/bytedance/1d-tokenizer.
Flowing from Words to Pixels: A Framework for Cross-Modality Evolution
Dec 19, 2024



Diffusion models, and their generalization, flow matching, have had a remarkable impact on the field of media generation. Here, the conventional approach is to learn the complex mapping from a simple source distribution of Gaussian noise to the target media distribution. For cross-modal tasks such as text-to-image generation, this same mapping from noise to image is learnt whilst including a conditioning mechanism in the model. One key and thus far relatively unexplored feature of flow matching is that, unlike Diffusion models, they are not constrained for the source distribution to be noise. Hence, in this paper, we propose a paradigm shift, and ask the question of whether we can instead train flow matching models to learn a direct mapping from the distribution of one modality to the distribution of another, thus obviating the need for both the noise distribution and conditioning mechanism. We present a general and simple framework, CrossFlow, for cross-modal flow matching. We show the importance of applying Variational Encoders to the input data, and introduce a method to enable Classifier-free guidance. Surprisingly, for text-to-image, CrossFlow with a vanilla transformer without cross attention slightly outperforms standard flow matching, and we show that it scales better with training steps and model size, while also allowing for interesting latent arithmetic which results in semantically meaningful edits in the output space. To demonstrate the generalizability of our approach, we also show that CrossFlow is on par with or outperforms the state-of-the-art for various cross-modal / intra-modal mapping tasks, viz. image captioning, depth estimation, and image super-resolution. We hope this paper contributes to accelerating progress in cross-modal media generation.
Automatic programming via large language models with population self-evolution for dynamic job shop scheduling problem
Oct 30, 2024Heuristic dispatching rules (HDRs) are widely regarded as effective methods for solving dynamic job shop scheduling problems (DJSSP) in real-world production environments. However, their performance is highly scenario-dependent, often requiring expert customization. To address this, genetic programming (GP) and gene expression programming (GEP) have been extensively used for automatic algorithm design. Nevertheless, these approaches often face challenges due to high randomness in the search process and limited generalization ability, hindering the application of trained dispatching rules to new scenarios or dynamic environments. Recently, the integration of large language models (LLMs) with evolutionary algorithms has opened new avenues for prompt engineering and automatic algorithm design. To enhance the capabilities of LLMs in automatic HDRs design, this paper proposes a novel population self-evolutionary (SeEvo) method, a general search framework inspired by the self-reflective design strategies of human experts. The SeEvo method accelerates the search process and enhances exploration capabilities. Experimental results show that the proposed SeEvo method outperforms GP, GEP, end-to-end deep reinforcement learning methods, and more than 10 common HDRs from the literature, particularly in unseen and dynamic scenarios.