 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman detectors are surprisingly powerful reward models
Jan 21, 2026Video generation models have recently achieved impressive visual fidelity and temporal coherence. Yet, they continue to struggle with complex, non-rigid motions, especially when synthesizing humans performing dynamic actions such as sports, dance, etc. Generated videos often exhibit missing or extra limbs, distorted poses, or physically implausible actions. In this work, we propose a remarkably simple reward model, HuDA, to quantify and improve the human motion in generated videos. HuDA integrates human detection confidence for appearance quality, and a temporal prompt alignment score to capture motion realism. We show this simple reward function that leverages off-the-shelf models without any additional training, outperforms specialized models finetuned with manually annotated data. Using HuDA for Group Reward Policy Optimization (GRPO) post-training of video models, we significantly enhance video generation, especially when generating complex human motions, outperforming state-of-the-art models like Wan 2.1, with win-rate of 73%. Finally, we demonstrate that HuDA improves generation quality beyond just humans, for instance, significantly improving generation of animal videos and human-object interactions.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
Mar 27, 2025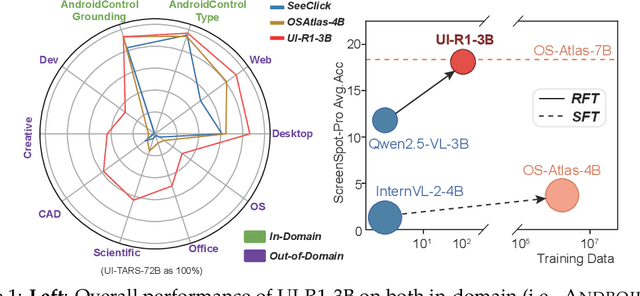
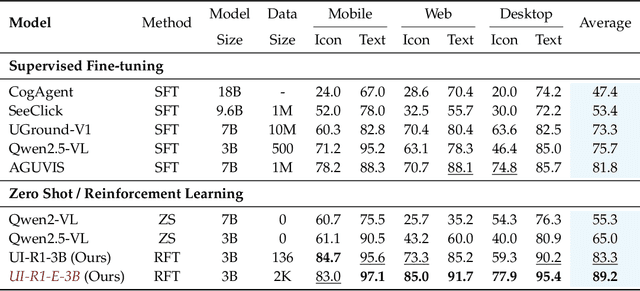
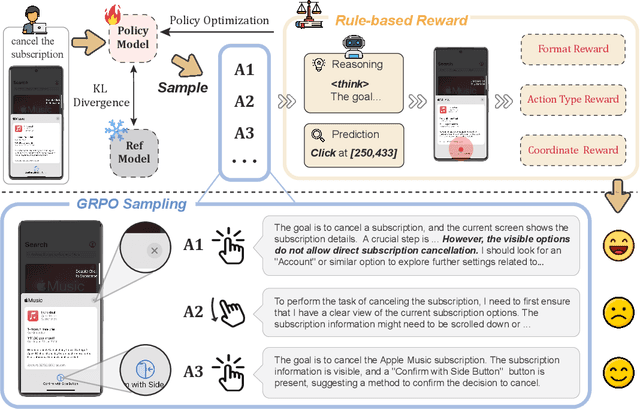
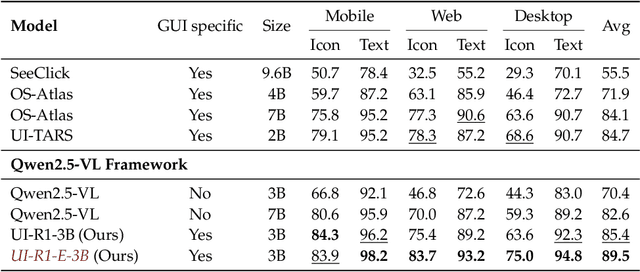
The recent DeepSeek-R1 has showcased the emergence of reasoning capabilities in LLMs through reinforcement learning (RL) with rule-based rewards. Building on this idea, we are the first to explore how rule-based RL can enhance the reasoning capabilities of multimodal large language models (MLLMs) for graphic user interface (GUI) action prediction tasks. To this end, we curate a small yet high-quality dataset of 136 challenging tasks, encompassing five common action types on mobile devices. We also introduce a unified rule-based action reward, enabling model optimization via policy-based algorithms such as Group Relative Policy Optimization (GRPO). Experimental results demonstrate that our proposed data-efficient model, UI-R1-3B, achieves substantial improvements on both in-domain (ID) and out-of-domain (OOD) tasks. Specifically, on the ID benchmark AndroidControl, the action type accuracy improves by 15%, while grounding accuracy increases by 10.3%, compared with the base model (i.e. Qwen2.5-VL-3B). On the OOD GUI grounding benchmark ScreenSpot-Pro, our model surpasses the base model by 6.0% and achieves competitive performance with larger models (e.g., OS-Atlas-7B), which are trained via supervised fine-tuning (SFT) on 76K data. These results underscore the potential of rule-based reinforcement learning to advance GUI understanding and control, paving the way for future research in this domain.
Generating Multi-Image Synthetic Data for Text-to-Image Customization
Feb 03, 2025Customization of text-to-image models enables users to insert custom concepts and generate the concepts in unseen settings. Existing methods either rely on costly test-time optimization or train encoders on single-image training datasets without multi-image supervision, leading to worse image quality. We propose a simple approach that addresses both limitations. We first leverage existing text-to-image models and 3D datasets to create a high-quality Synthetic Customization Dataset (SynCD) consisting of multiple images of the same object in different lighting, backgrounds, and poses. We then propose a new encoder architecture based on shared attention mechanisms that better incorporate fine-grained visual details from input images. Finally, we propose a new inference technique that mitigates overexposure issues during inference by normalizing the text and image guidance vectors. Through extensive experiments, we show that our model, trained on the synthetic dataset with the proposed encoder and inference algorithm, outperforms existing tuning-free methods on standard customization benchmarks.
MotiF: Making Text Count in Image Animation with Motion Focal Loss
Dec 20, 2024Text-Image-to-Video (TI2V) generation aims to generate a video from an image following a text description, which is also referred to as text-guided image animation. Most existing methods struggle to generate videos that align well with the text prompts, particularly when motion is specified. To overcome this limitation, we introduce MotiF, a simple yet effective approach that directs the model's learning to the regions with more motion, thereby improving the text alignment and motion generation. We use optical flow to generate a motion heatmap and weight the loss according to the intensity of the motion. This modified objective leads to noticeable improvements and complements existing methods that utilize motion priors as model inputs. Additionally, due to the lack of a diverse benchmark for evaluating TI2V generation, we propose TI2V Bench, a dataset consists of 320 image-text pairs for robust evaluation. We present a human evaluation protocol that asks the annotators to select an overall preference between two videos followed by their justifications. Through a comprehensive evaluation on TI2V Bench, MotiF outperforms nine open-sourced models, achieving an average preference of 72%. The TI2V Bench is released in https://wang-sj16.github.io/motif/.
Flowing from Words to Pixels: A Framework for Cross-Modality Evolution
Dec 19, 2024



Diffusion models, and their generalization, flow matching, have had a remarkable impact on the field of media generation. Here, the conventional approach is to learn the complex mapping from a simple source distribution of Gaussian noise to the target media distribution. For cross-modal tasks such as text-to-image generation, this same mapping from noise to image is learnt whilst including a conditioning mechanism in the model. One key and thus far relatively unexplored feature of flow matching is that, unlike Diffusion models, they are not constrained for the source distribution to be noise. Hence, in this paper, we propose a paradigm shift, and ask the question of whether we can instead train flow matching models to learn a direct mapping from the distribution of one modality to the distribution of another, thus obviating the need for both the noise distribution and conditioning mechanism. We present a general and simple framework, CrossFlow, for cross-modal flow matching. We show the importance of applying Variational Encoders to the input data, and introduce a method to enable Classifier-free guidance. Surprisingly, for text-to-image, CrossFlow with a vanilla transformer without cross attention slightly outperforms standard flow matching, and we show that it scales better with training steps and model size, while also allowing for interesting latent arithmetic which results in semantically meaningful edits in the output space. To demonstrate the generalizability of our approach, we also show that CrossFlow is on par with or outperforms the state-of-the-art for various cross-modal / intra-modal mapping tasks, viz. image captioning, depth estimation, and image super-resolution. We hope this paper contributes to accelerating progress in cross-modal media generation.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Proactive Schemes: A Survey of Adversarial Attacks for Social Good
Sep 24, 2024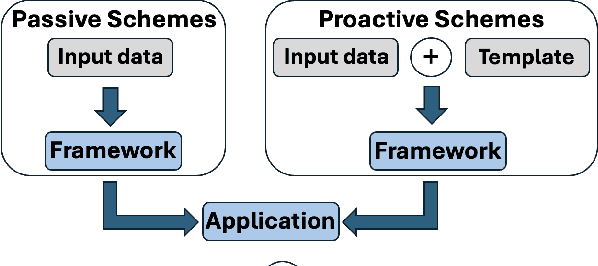

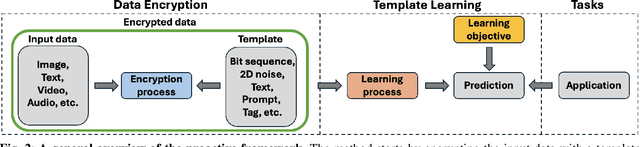
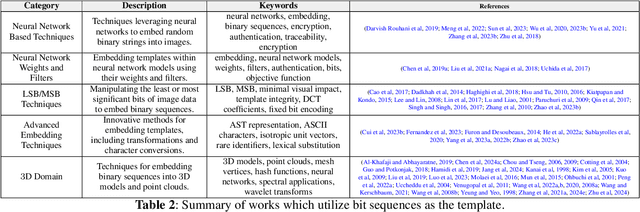
Adversarial attacks in computer vision exploit the vulnerabilities of machine learning models by introducing subtle perturbations to input data, often leading to incorrect predictions or classifications. These attacks have evolved in sophistication with the advent of deep learning, presenting significant challenges in critical applications, which can be harmful for society. However, there is also a rich line of research from a transformative perspective that leverages adversarial techniques for social good. Specifically, we examine the rise of proactive schemes-methods that encrypt input data using additional signals termed templates, to enhance the performance of deep learning models. By embedding these imperceptible templates into digital media, proactive schemes are applied across various applications, from simple image enhancements to complicated deep learning frameworks to aid performance, as compared to the passive schemes, which don't change the input data distribution for their framework. The survey delves into the methodologies behind these proactive schemes, the encryption and learning processes, and their application to modern computer vision and natural language processing applications. Additionally, it discusses the challenges, potential vulnerabilities, and future directions for proactive schemes, ultimately highlighting their potential to foster the responsible and secure advancement of deep learning technologies.
AcademicGPT: Empowering Academic Research
Nov 21, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Yet, many of these advanced LLMs are tailored for broad, general-purpose applications. In this technical report, we introduce AcademicGPT, designed specifically to empower academic research. AcademicGPT is a continual training model derived from LLaMA2-70B. Our training corpus mainly consists of academic papers, thesis, content from some academic domain, high-quality Chinese data and others. While it may not be extensive in data scale, AcademicGPT marks our initial venture into a domain-specific GPT tailored for research area. We evaluate AcademicGPT on several established public benchmarks such as MMLU and CEval, as well as on some specialized academic benchmarks like PubMedQA, SCIEval, and our newly-created ComputerScienceQA, to demonstrate its ability from general knowledge ability, to Chinese ability, and to academic ability. Building upon AcademicGPT's foundation model, we also developed several applications catered to the academic area, including General Academic Question Answering, AI-assisted Paper Reading, Paper Review, and AI-assisted Title and Abstract Generation.
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Nov 17, 2023We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions--adjusted noise schedules for diffusion, and multi-stage training--that enable us to directly generate high quality and high resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work--81% vs. Google's Imagen Video, 90% vs. Nvidia's PYOCO, and 96% vs. Meta's Make-A-Video. Our model outperforms commercial solutions such as RunwayML's Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user's text prompt, where our generations are preferred 96% over prior work.