 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Generating Multi-Image Synthetic Data for Text-to-Image Customization
Feb 03, 2025Customization of text-to-image models enables users to insert custom concepts and generate the concepts in unseen settings. Existing methods either rely on costly test-time optimization or train encoders on single-image training datasets without multi-image supervision, leading to worse image quality. We propose a simple approach that addresses both limitations. We first leverage existing text-to-image models and 3D datasets to create a high-quality Synthetic Customization Dataset (SynCD) consisting of multiple images of the same object in different lighting, backgrounds, and poses. We then propose a new encoder architecture based on shared attention mechanisms that better incorporate fine-grained visual details from input images. Finally, we propose a new inference technique that mitigates overexposure issues during inference by normalizing the text and image guidance vectors. Through extensive experiments, we show that our model, trained on the synthetic dataset with the proposed encoder and inference algorithm, outperforms existing tuning-free methods on standard customization benchmarks.
MotiF: Making Text Count in Image Animation with Motion Focal Loss
Dec 20, 2024Text-Image-to-Video (TI2V) generation aims to generate a video from an image following a text description, which is also referred to as text-guided image animation. Most existing methods struggle to generate videos that align well with the text prompts, particularly when motion is specified. To overcome this limitation, we introduce MotiF, a simple yet effective approach that directs the model's learning to the regions with more motion, thereby improving the text alignment and motion generation. We use optical flow to generate a motion heatmap and weight the loss according to the intensity of the motion. This modified objective leads to noticeable improvements and complements existing methods that utilize motion priors as model inputs. Additionally, due to the lack of a diverse benchmark for evaluating TI2V generation, we propose TI2V Bench, a dataset consists of 320 image-text pairs for robust evaluation. We present a human evaluation protocol that asks the annotators to select an overall preference between two videos followed by their justifications. Through a comprehensive evaluation on TI2V Bench, MotiF outperforms nine open-sourced models, achieving an average preference of 72%. The TI2V Bench is released in https://wang-sj16.github.io/motif/.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Motion-Conditioned Image Animation for Video Editing
Nov 30, 2023



We introduce MoCA, a Motion-Conditioned Image Animation approach for video editing. It leverages a simple decomposition of the video editing problem into image editing followed by motion-conditioned image animation. Furthermore, given the lack of robust evaluation datasets for video editing, we introduce a new benchmark that measures edit capability across a wide variety of tasks, such as object replacement, background changes, style changes, and motion edits. We present a comprehensive human evaluation of the latest video editing methods along with MoCA, on our proposed benchmark. MoCA establishes a new state-of-the-art, demonstrating greater human preference win-rate, and outperforming notable recent approaches including Dreamix (63%), MasaCtrl (75%), and Tune-A-Video (72%), with especially significant improvements for motion edits.
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
Nov 17, 2023We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions--adjusted noise schedules for diffusion, and multi-stage training--that enable us to directly generate high quality and high resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work--81% vs. Google's Imagen Video, 90% vs. Nvidia's PYOCO, and 96% vs. Meta's Make-A-Video. Our model outperforms commercial solutions such as RunwayML's Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user's text prompt, where our generations are preferred 96% over prior work.
Make-An-Animation: Large-Scale Text-conditional 3D Human Motion Generation
May 16, 2023Text-guided human motion generation has drawn significant interest because of its impactful applications spanning animation and robotics. Recently, application of diffusion models for motion generation has enabled improvements in the quality of generated motions. However, existing approaches are limited by their reliance on relatively small-scale motion capture data, leading to poor performance on more diverse, in-the-wild prompts. In this paper, we introduce Make-An-Animation, a text-conditioned human motion generation model which learns more diverse poses and prompts from large-scale image-text datasets, enabling significant improvement in performance over prior works. Make-An-Animation is trained in two stages. First, we train on a curated large-scale dataset of (text, static pseudo-pose) pairs extracted from image-text datasets. Second, we fine-tune on motion capture data, adding additional layers to model the temporal dimension. Unlike prior diffusion models for motion generation, Make-An-Animation uses a U-Net architecture similar to recent text-to-video generation models. Human evaluation of motion realism and alignment with input text shows that our model reaches state-of-the-art performance on text-to-motion generation.
Text-Conditional Contextualized Avatars For Zero-Shot Personalization
Apr 14, 2023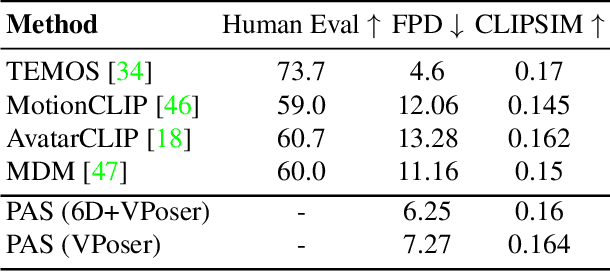
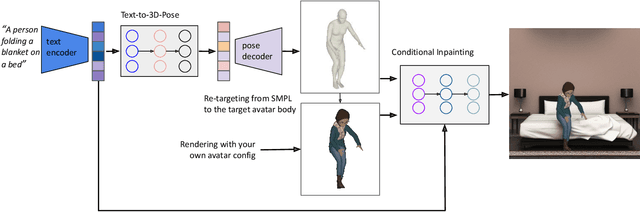
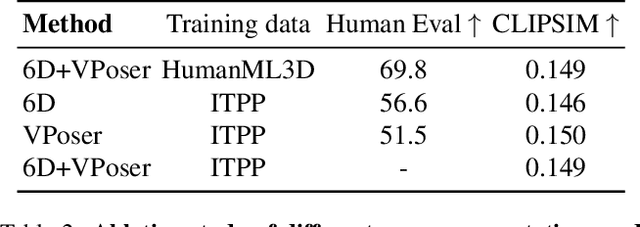
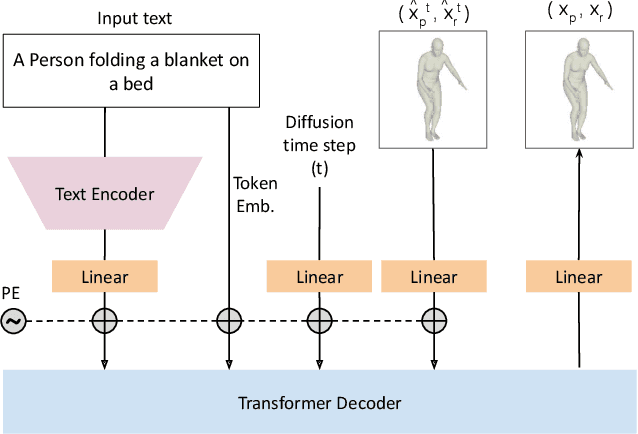
Recent large-scale text-to-image generation models have made significant improvements in the quality, realism, and diversity of the synthesized images and enable users to control the created content through language. However, the personalization aspect of these generative models is still challenging and under-explored. In this work, we propose a pipeline that enables personalization of image generation with avatars capturing a user's identity in a delightful way. Our pipeline is zero-shot, avatar texture and style agnostic, and does not require training on the avatar at all - it is scalable to millions of users who can generate a scene with their avatar. To render the avatar in a pose faithful to the given text prompt, we propose a novel text-to-3D pose diffusion model trained on a curated large-scale dataset of in-the-wild human poses improving the performance of the SOTA text-to-motion models significantly. We show, for the first time, how to leverage large-scale image datasets to learn human 3D pose parameters and overcome the limitations of motion capture datasets.
Shape-Guided Diffusion with Inside-Outside Attention
Dec 01, 2022
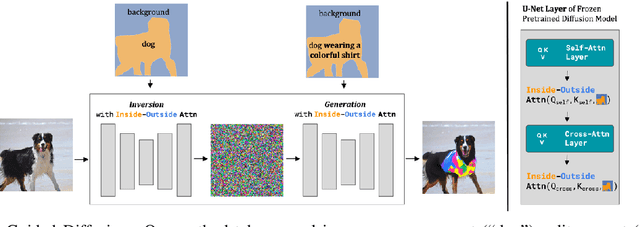

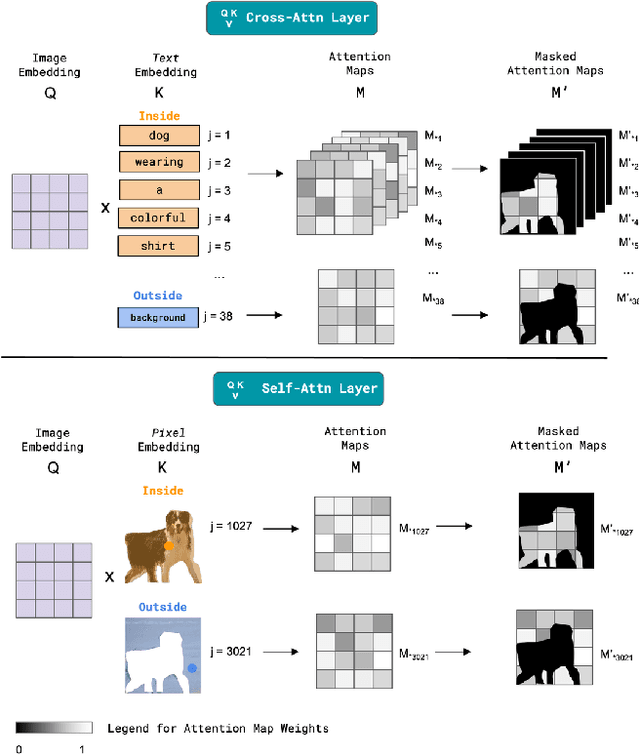
Shape can specify key object constraints, yet existing text-to-image diffusion models ignore this cue and synthesize objects that are incorrectly scaled, cut off, or replaced with background content. We propose a training-free method, Shape-Guided Diffusion, which uses a novel Inside-Outside Attention mechanism to constrain the cross-attention (and self-attention) maps such that prompt tokens (and pixels) referring to the inside of the shape cannot attend outside the shape, and vice versa. To demonstrate the efficacy of our method, we propose a new image editing task where the model must replace an object specified by its mask and a text prompt. We curate a new ShapePrompts benchmark based on MS-COCO and achieve SOTA results in shape faithfulness, text alignment, and realism according to both quantitative metrics and human preferences. Our data and code will be made available at https://shape-guided-diffusion.github.io.
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
Dec 14, 2021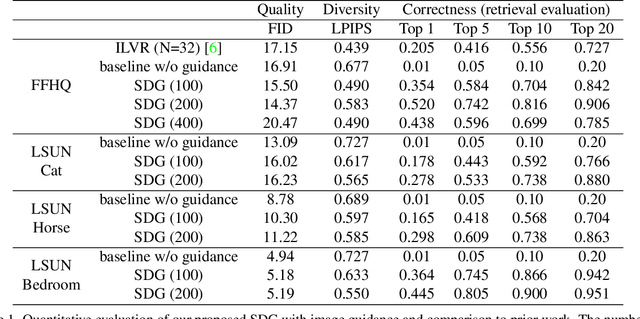
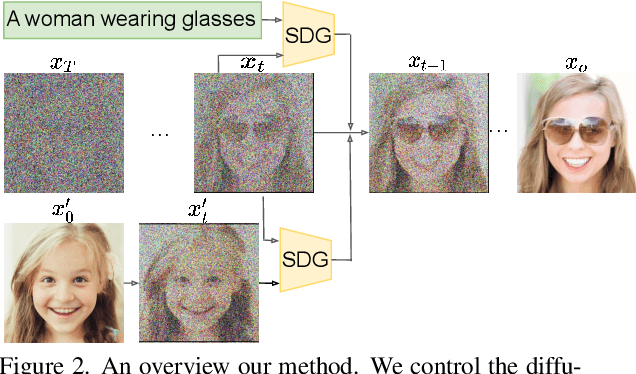
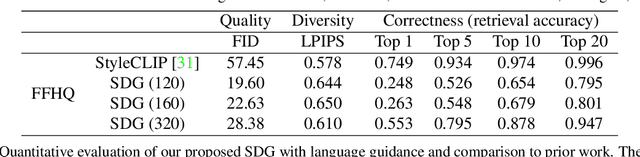

Controllable image synthesis models allow creation of diverse images based on text instructions or guidance from an example image. Recently, denoising diffusion probabilistic models have been shown to generate more realistic imagery than prior methods, and have been successfully demonstrated in unconditional and class-conditional settings. We explore fine-grained, continuous control of this model class, and introduce a novel unified framework for semantic diffusion guidance, which allows either language or image guidance, or both. Guidance is injected into a pretrained unconditional diffusion model using the gradient of image-text or image matching scores. We explore CLIP-based textual guidance as well as both content and style-based image guidance in a unified form. Our text-guided synthesis approach can be applied to datasets without associated text annotations. We conduct experiments on FFHQ and LSUN datasets, and show results on fine-grained text-guided image synthesis, synthesis of images related to a style or content example image, and examples with both textual and image guidance.