 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Reinforcement Learning for Diffusion Models
Jan 20, 2024Text-to-image diffusion models are a class of deep generative models that have demonstrated an impressive capacity for high-quality image generation. However, these models are susceptible to implicit biases that arise from web-scale text-image training pairs and may inaccurately model aspects of images we care about. This can result in suboptimal samples, model bias, and images that do not align with human ethics and preferences. In this paper, we present an effective scalable algorithm to improve diffusion models using Reinforcement Learning (RL) across a diverse set of reward functions, such as human preference, compositionality, and fairness over millions of images. We illustrate how our approach substantially outperforms existing methods for aligning diffusion models with human preferences. We further illustrate how this substantially improves pretrained Stable Diffusion (SD) models, generating samples that are preferred by humans 80.3% of the time over those from the base SD model while simultaneously improving both the composition and diversity of generated samples.
Toward Transformer-Based Object Detection
Dec 17, 2020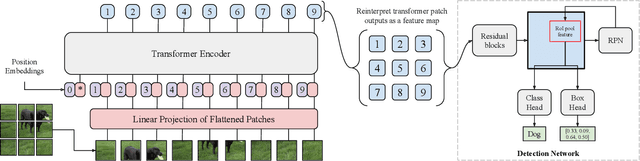
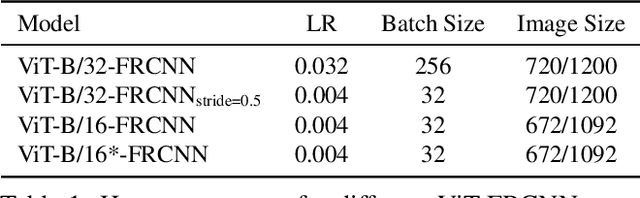
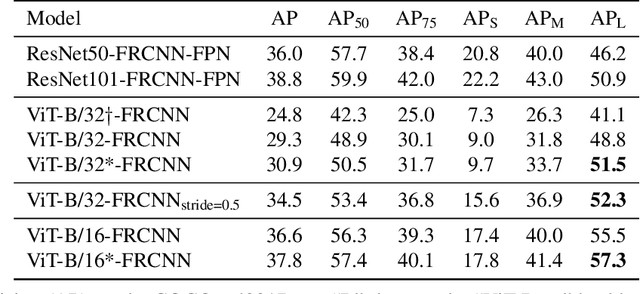
Transformers have become the dominant model in natural language processing, owing to their ability to pretrain on massive amounts of data, then transfer to smaller, more specific tasks via fine-tuning. The Vision Transformer was the first major attempt to apply a pure transformer model directly to images as input, demonstrating that as compared to convolutional networks, transformer-based architectures can achieve competitive results on benchmark classification tasks. However, the computational complexity of the attention operator means that we are limited to low-resolution inputs. For more complex tasks such as detection or segmentation, maintaining a high input resolution is crucial to ensure that models can properly identify and reflect fine details in their output. This naturally raises the question of whether or not transformer-based architectures such as the Vision Transformer are capable of performing tasks other than classification. In this paper, we determine that Vision Transformers can be used as a backbone by a common detection task head to produce competitive COCO results. The model that we propose, ViT-FRCNN, demonstrates several known properties associated with transformers, including large pretraining capacity and fast fine-tuning performance. We also investigate improvements over a standard detection backbone, including superior performance on out-of-domain images, better performance on large objects, and a lessened reliance on non-maximum suppression. We view ViT-FRCNN as an important stepping stone toward a pure-transformer solution of complex vision tasks such as object detection.
Revisiting Few-shot Activity Detection with Class Similarity Control
Mar 31, 2020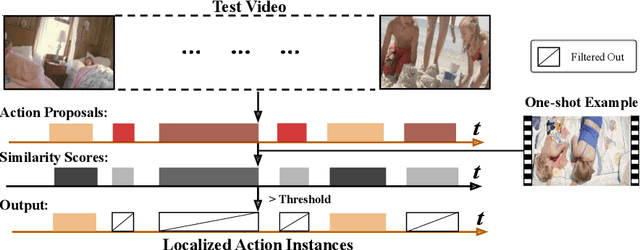


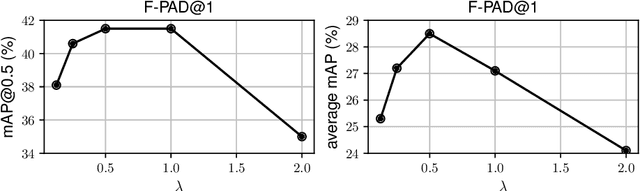
Many interesting events in the real world are rare making preannotated machine learning ready videos a rarity in consequence. Thus, temporal activity detection models that are able to learn from a few examples are desirable. In this paper, we present a conceptually simple and general yet novel framework for few-shot temporal activity detection based on proposal regression which detects the start and end time of the activities in untrimmed videos. Our model is end-to-end trainable, takes into account the frame rate differences between few-shot activities and untrimmed test videos, and can benefit from additional few-shot examples. We experiment on three large scale benchmarks for temporal activity detection (ActivityNet1.2, ActivityNet1.3 and THUMOS14 datasets) in a few-shot setting. We also study the effect on performance of different amount of overlap with activities used to pretrain the video classification backbone and propose corrective measures for future works in this domain. Our code will be made available.
Semantic Bottleneck Scene Generation
Nov 26, 2019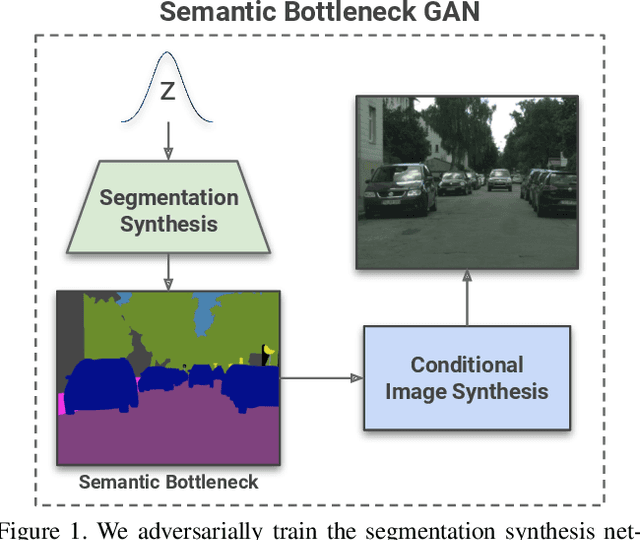


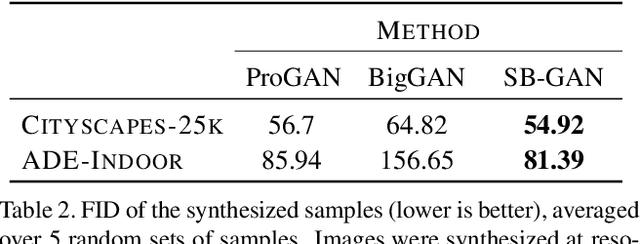
Coupling the high-fidelity generation capabilities of label-conditional image synthesis methods with the flexibility of unconditional generative models, we propose a semantic bottleneck GAN model for unconditional synthesis of complex scenes. We assume pixel-wise segmentation labels are available during training and use them to learn the scene structure. During inference, our model first synthesizes a realistic segmentation layout from scratch, then synthesizes a realistic scene conditioned on that layout. For the former, we use an unconditional progressive segmentation generation network that captures the distribution of realistic semantic scene layouts. For the latter, we use a conditional segmentation-to-image synthesis network that captures the distribution of photo-realistic images conditioned on the semantic layout. When trained end-to-end, the resulting model outperforms state-of-the-art generative models in unsupervised image synthesis on two challenging domains in terms of the Frechet Inception Distance and user-study evaluations. Moreover, we demonstrate the generated segmentation maps can be used as additional training data to strongly improve recent segmentation-to-image synthesis networks.
Unsupervised Domain Adaptation through Self-Supervision
Sep 29, 2019

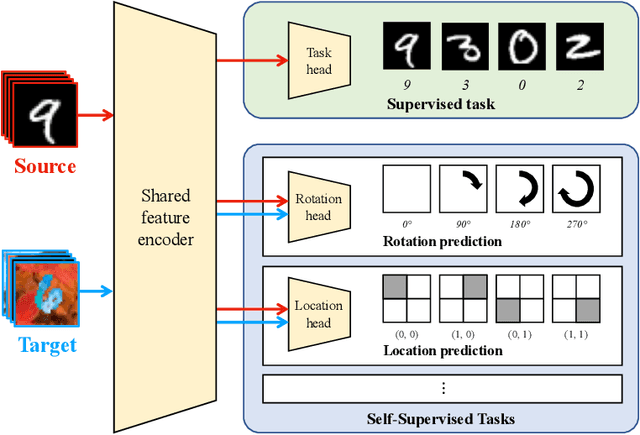
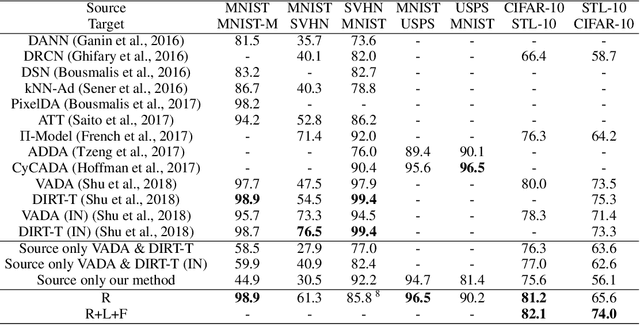
This paper addresses unsupervised domain adaptation, the setting where labeled training data is available on a source domain, but the goal is to have good performance on a target domain with only unlabeled data. Like much of previous work, we seek to align the learned representations of the source and target domains while preserving discriminability. The way we accomplish alignment is by learning to perform auxiliary self-supervised task(s) on both domains simultaneously. Each self-supervised task brings the two domains closer together along the direction relevant to that task. Training this jointly with the main task classifier on the source domain is shown to successfully generalize to the unlabeled target domain. The presented objective is straightforward to implement and easy to optimize. We achieve state-of-the-art results on four out of seven standard benchmarks, and competitive results on segmentation adaptation. We also demonstrate that our method composes well with another popular pixel-level adaptation method.
Learning a Unified Embedding for Visual Search at Pinterest
Aug 05, 2019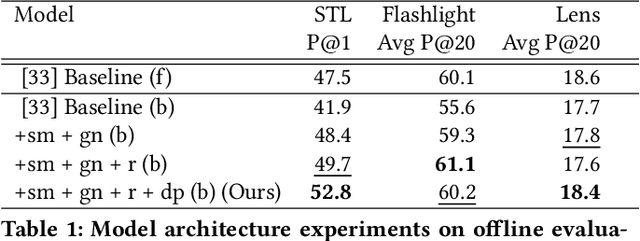

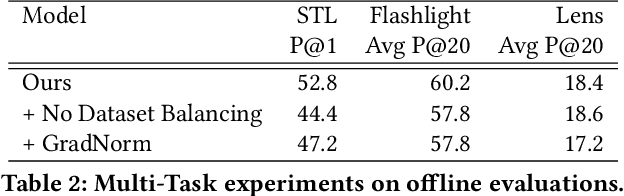
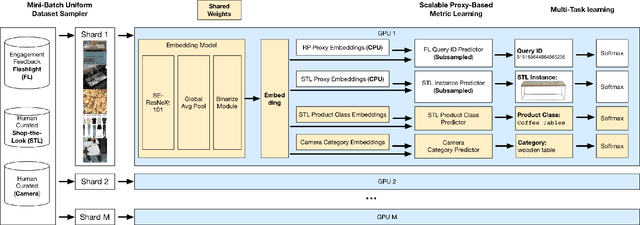
At Pinterest, we utilize image embeddings throughout our search and recommendation systems to help our users navigate through visual content by powering experiences like browsing of related content and searching for exact products for shopping. In this work we describe a multi-task deep metric learning system to learn a single unified image embedding which can be used to power our multiple visual search products. The solution we present not only allows us to train for multiple application objectives in a single deep neural network architecture, but takes advantage of correlated information in the combination of all training data from each application to generate a unified embedding that outperforms all specialized embeddings previously deployed for each product. We discuss the challenges of handling images from different domains such as camera photos, high quality web images, and clean product catalog images. We also detail how to jointly train for multiple product objectives and how to leverage both engagement data and human labeled data. In addition, our trained embeddings can also be binarized for efficient storage and retrieval without compromising precision and recall. Through comprehensive evaluations on offline metrics, user studies, and online A/B experiments, we demonstrate that our proposed unified embedding improves both relevance and engagement of our visual search products for both browsing and searching purposes when compared to existing specialized embeddings. Finally, the deployment of the unified embedding at Pinterest has drastically reduced the operation and engineering cost of maintaining multiple embeddings while improving quality.
SPLAT: Semantic Pixel-Level Adaptation Transforms for Detection
Dec 03, 2018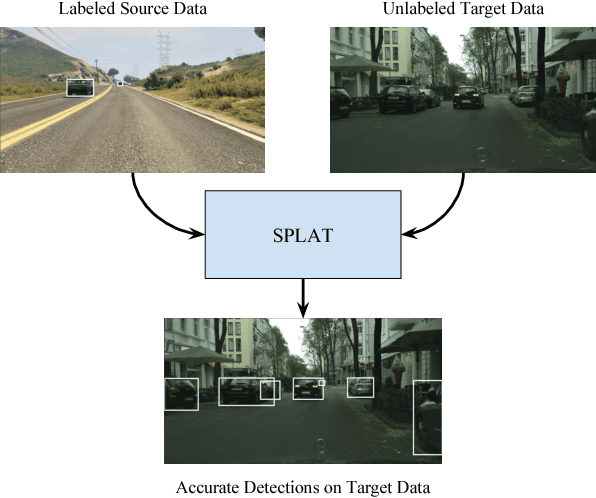


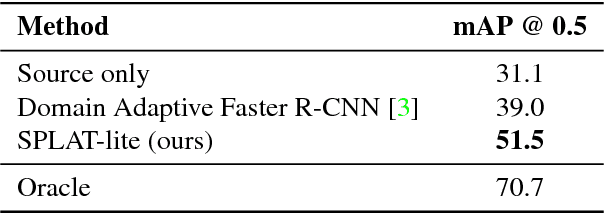
Domain adaptation of visual detectors is a critical challenge, yet existing methods have overlooked pixel appearance transformations, focusing instead on bootstrapping and/or domain confusion losses. We propose a Semantic Pixel-Level Adaptation Transform (SPLAT) approach to detector adaptation that efficiently generates cross-domain image pairs. Our model uses aligned-pair and/or pseudo-label losses to adapt an object detector to the target domain, and can learn transformations with or without densely labeled data in the source (e.g. semantic segmentation annotations). Without dense labels, as is the case when only detection labels are available in the source, transformations are learned using CycleGAN alignment. Otherwise, when dense labels are available we introduce a more efficient cycle-free method, which exploits pixel-level semantic labels to condition the training of the transformation network. The end task is then trained using detection box labels from the source, potentially including labels inferred on unlabeled source data. We show both that pixel-level transforms outperform prior approaches to detector domain adaptation, and that our cycle-free method outperforms prior models for unconstrained cycle-based learning of generic transformations while running 3.8 times faster. Our combined model improves on prior detection baselines by 12.5 mAP adapting from Sim 10K to Cityscapes, recovering over 50% of the missing performance between the unadapted baseline and the labeled-target upper bound.
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
Dec 29, 2017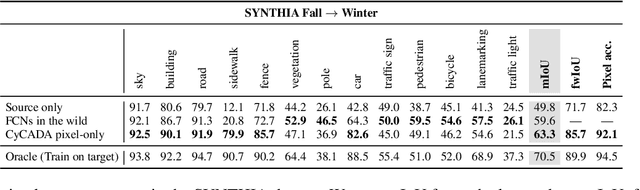
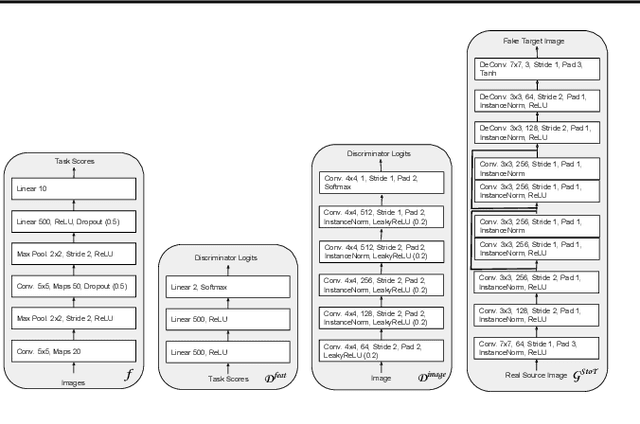


Domain adaptation is critical for success in new, unseen environments. Adversarial adaptation models applied in feature spaces discover domain invariant representations, but are difficult to visualize and sometimes fail to capture pixel-level and low-level domain shifts. Recent work has shown that generative adversarial networks combined with cycle-consistency constraints are surprisingly effective at mapping images between domains, even without the use of aligned image pairs. We propose a novel discriminatively-trained Cycle-Consistent Adversarial Domain Adaptation model. CyCADA adapts representations at both the pixel-level and feature-level, enforces cycle-consistency while leveraging a task loss, and does not require aligned pairs. Our model can be applied in a variety of visual recognition and prediction settings. We show new state-of-the-art results across multiple adaptation tasks, including digit classification and semantic segmentation of road scenes demonstrating transfer from synthetic to real world domains.
Adapting Deep Visuomotor Representations with Weak Pairwise Constraints
May 25, 2017

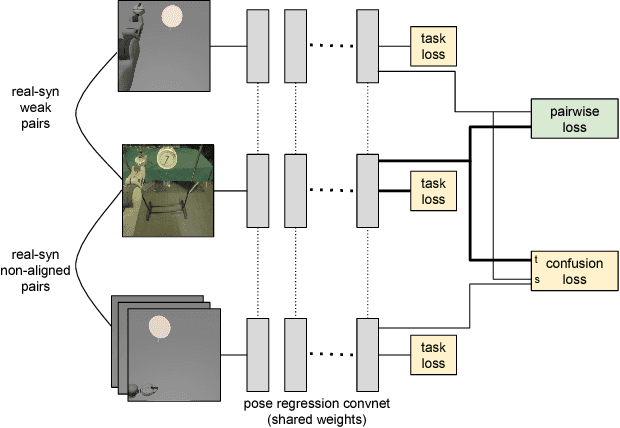
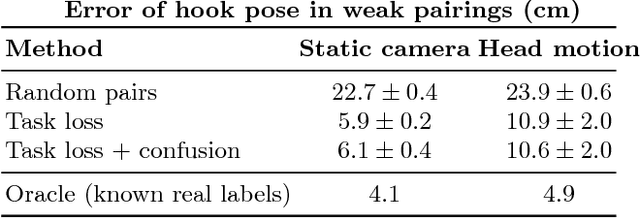
Real-world robotics problems often occur in domains that differ significantly from the robot's prior training environment. For many robotic control tasks, real world experience is expensive to obtain, but data is easy to collect in either an instrumented environment or in simulation. We propose a novel domain adaptation approach for robot perception that adapts visual representations learned on a large easy-to-obtain source dataset (e.g. synthetic images) to a target real-world domain, without requiring expensive manual data annotation of real world data before policy search. Supervised domain adaptation methods minimize cross-domain differences using pairs of aligned images that contain the same object or scene in both the source and target domains, thus learning a domain-invariant representation. However, they require manual alignment of such image pairs. Fully unsupervised adaptation methods rely on minimizing the discrepancy between the feature distributions across domains. We propose a novel, more powerful combination of both distribution and pairwise image alignment, and remove the requirement for expensive annotation by using weakly aligned pairs of images in the source and target domains. Focusing on adapting from simulation to real world data using a PR2 robot, we evaluate our approach on a manipulation task and show that by using weakly paired images, our method compensates for domain shift more effectively than previous techniques, enabling better robot performance in the real world.
Visual Discovery at Pinterest
Mar 25, 2017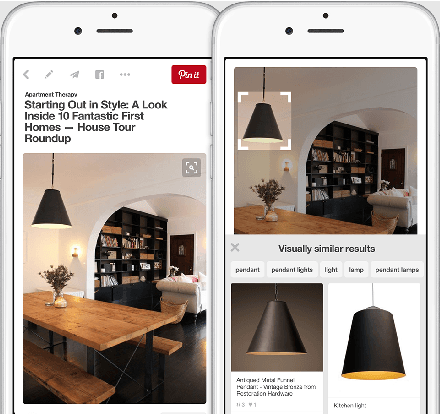
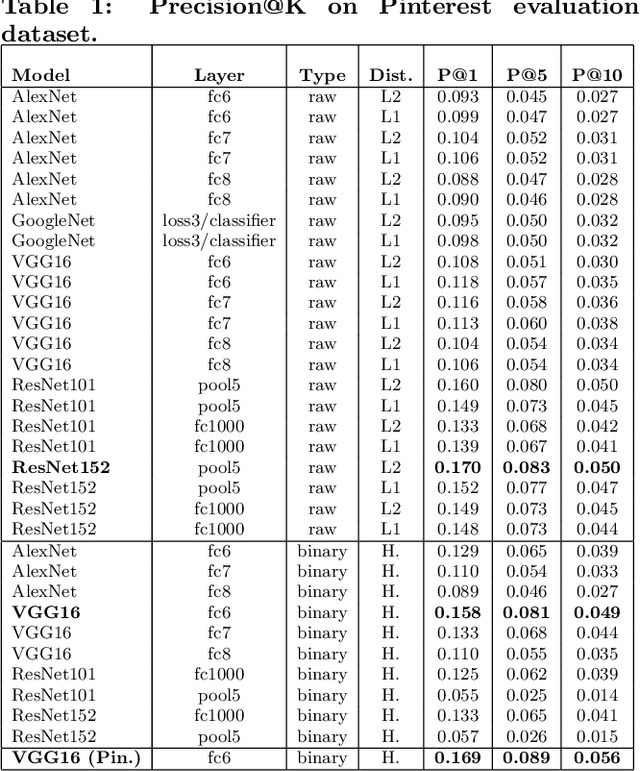
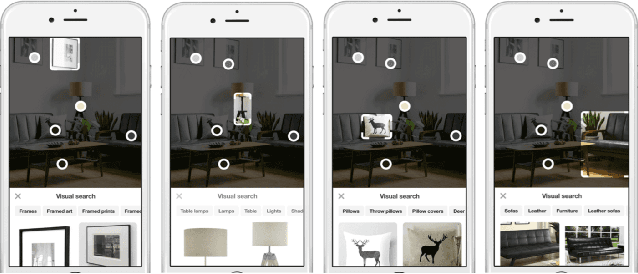
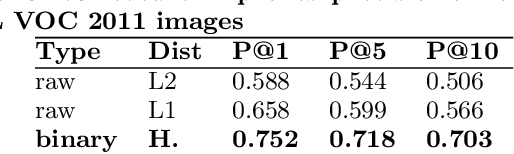
Over the past three years Pinterest has experimented with several visual search and recommendation services, including Related Pins (2014), Similar Looks (2015), Flashlight (2016) and Lens (2017). This paper presents an overview of our visual discovery engine powering these services, and shares the rationales behind our technical and product decisions such as the use of object detection and interactive user interfaces. We conclude that this visual discovery engine significantly improves engagement in both search and recommendation tasks.