 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboCrowd: Scaling Robot Data Collection through Crowdsourcing
Nov 04, 2024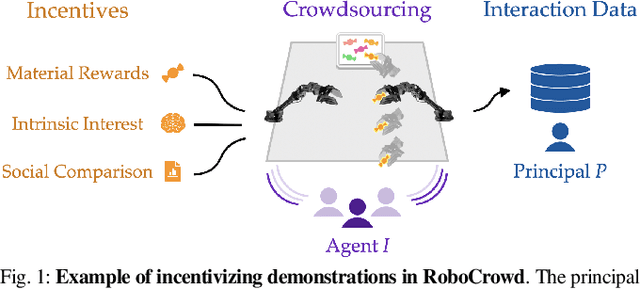
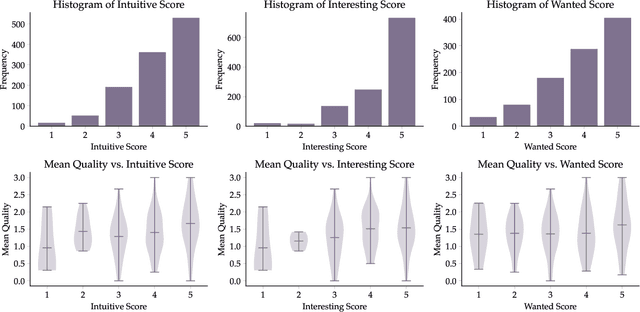
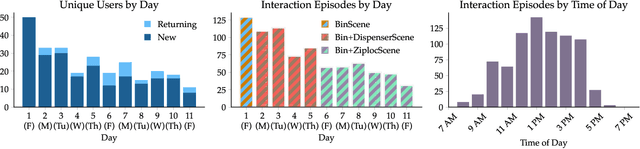
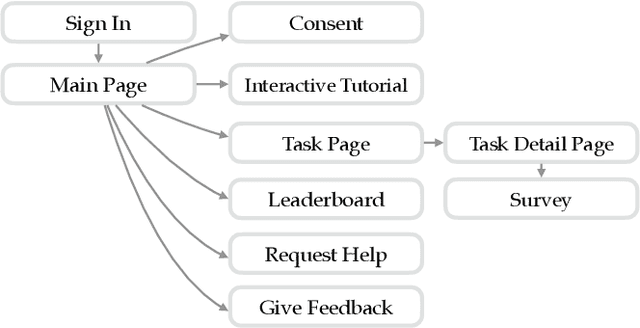
In recent years, imitation learning from large-scale human demonstrations has emerged as a promising paradigm for training robot policies. However, the burden of collecting large quantities of human demonstrations is significant in terms of collection time and the need for access to expert operators. We introduce a new data collection paradigm, RoboCrowd, which distributes the workload by utilizing crowdsourcing principles and incentive design. RoboCrowd helps enable scalable data collection and facilitates more efficient learning of robot policies. We build RoboCrowd on top of ALOHA (Zhao et al. 2023) -- a bimanual platform that supports data collection via puppeteering -- to explore the design space for crowdsourcing in-person demonstrations in a public environment. We propose three classes of incentive mechanisms to appeal to users' varying sources of motivation for interacting with the system: material rewards, intrinsic interest, and social comparison. We instantiate these incentives through tasks that include physical rewards, engaging or challenging manipulations, as well as gamification elements such as a leaderboard. We conduct a large-scale, two-week field experiment in which the platform is situated in a university cafe. We observe significant engagement with the system -- over 200 individuals independently volunteered to provide a total of over 800 interaction episodes. Our findings validate the proposed incentives as mechanisms for shaping users' data quantity and quality. Further, we demonstrate that the crowdsourced data can serve as useful pre-training data for policies fine-tuned on expert demonstrations -- boosting performance up to 20% compared to when this data is not available. These results suggest the potential for RoboCrowd to reduce the burden of robot data collection by carefully implementing crowdsourcing and incentive design principles.
Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning
Apr 16, 2024Inductive biases are crucial in disentangled representation learning for narrowing down an underspecified solution set. In this work, we consider endowing a neural network autoencoder with three select inductive biases from the literature: data compression into a grid-like latent space via quantization, collective independence amongst latents, and minimal functional influence of any latent on how other latents determine data generation. In principle, these inductive biases are deeply complementary: they most directly specify properties of the latent space, encoder, and decoder, respectively. In practice, however, naively combining existing techniques instantiating these inductive biases fails to yield significant benefits. To address this, we propose adaptations to the three techniques that simplify the learning problem, equip key regularization terms with stabilizing invariances, and quash degenerate incentives. The resulting model, Tripod, achieves state-of-the-art results on a suite of four image disentanglement benchmarks. We also verify that Tripod significantly improves upon its naive incarnation and that all three of its "legs" are necessary for best performance.
GenCHiP: Generating Robot Policy Code for High-Precision and Contact-Rich Manipulation Tasks
Apr 09, 2024



Large Language Models (LLMs) have been successful at generating robot policy code, but so far these results have been limited to high-level tasks that do not require precise movement. It is an open question how well such approaches work for tasks that require reasoning over contact forces and working within tight success tolerances. We find that, with the right action space, LLMs are capable of successfully generating policies for a variety of contact-rich and high-precision manipulation tasks, even under noisy conditions, such as perceptual errors or grasping inaccuracies. Specifically, we reparameterize the action space to include compliance with constraints on the interaction forces and stiffnesses involved in reaching a target pose. We validate this approach on subtasks derived from the Functional Manipulation Benchmark (FMB) and NIST Task Board Benchmarks. Exposing this action space alongside methods for estimating object poses improves policy generation with an LLM by greater than 3x and 4x when compared to non-compliant action spaces
Neural Functional Transformers
May 22, 2023
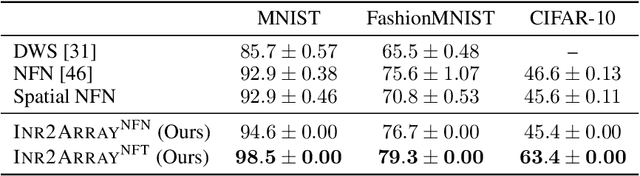
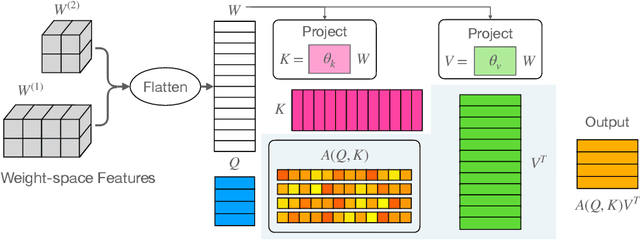

The recent success of neural networks as implicit representation of data has driven growing interest in neural functionals: models that can process other neural networks as input by operating directly over their weight spaces. Nevertheless, constructing expressive and efficient neural functional architectures that can handle high-dimensional weight-space objects remains challenging. This paper uses the attention mechanism to define a novel set of permutation equivariant weight-space layers and composes them into deep equivariant models called neural functional Transformers (NFTs). NFTs respect weight-space permutation symmetries while incorporating the advantages of attention, which have exhibited remarkable success across multiple domains. In experiments processing the weights of feedforward MLPs and CNNs, we find that NFTs match or exceed the performance of prior weight-space methods. We also leverage NFTs to develop Inr2Array, a novel method for computing permutation invariant latent representations from the weights of implicit neural representations (INRs). Our proposed method improves INR classification accuracy by up to $+17\%$ over existing methods. We provide an implementation of our layers at https://github.com/AllanYangZhou/nfn.
Permutation Equivariant Neural Functionals
Feb 27, 2023



This work studies the design of neural networks that can process the weights or gradients of other neural networks, which we refer to as neural functional networks (NFNs). Despite a wide range of potential applications, including learned optimization, processing implicit neural representations, network editing, and policy evaluation, there are few unifying principles for designing effective architectures that process the weights of other networks. We approach the design of neural functionals through the lens of symmetry, in particular by focusing on the permutation symmetries that arise in the weights of deep feedforward networks because hidden layer neurons have no inherent order. We introduce a framework for building permutation equivariant neural functionals, whose architectures encode these symmetries as an inductive bias. The key building blocks of this framework are NF-Layers (neural functional layers) that we constrain to be permutation equivariant through an appropriate parameter sharing scheme. In our experiments, we find that permutation equivariant neural functionals are effective on a diverse set of tasks that require processing the weights of MLPs and CNNs, such as predicting classifier generalization, producing "winning ticket" sparsity masks for initializations, and editing the weights of implicit neural representations (INRs). In addition, we provide code for our models and experiments at https://github.com/AllanYangZhou/nfn.
Offline Reinforcement Learning at Multiple Frequencies
Jul 26, 2022
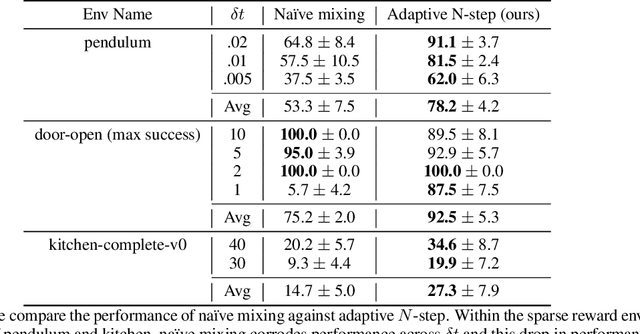

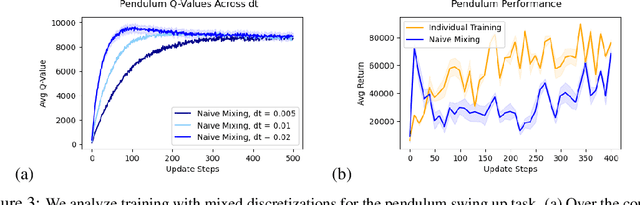
Leveraging many sources of offline robot data requires grappling with the heterogeneity of such data. In this paper, we focus on one particular aspect of heterogeneity: learning from offline data collected at different control frequencies. Across labs, the discretization of controllers, sampling rates of sensors, and demands of a task of interest may differ, giving rise to a mixture of frequencies in an aggregated dataset. We study how well offline reinforcement learning (RL) algorithms can accommodate data with a mixture of frequencies during training. We observe that the $Q$-value propagates at different rates for different discretizations, leading to a number of learning challenges for off-the-shelf offline RL. We present a simple yet effective solution that enforces consistency in the rate of $Q$-value updates to stabilize learning. By scaling the value of $N$ in $N$-step returns with the discretization size, we effectively balance $Q$-value propagation, leading to more stable convergence. On three simulated robotic control problems, we empirically find that this simple approach outperforms na\"ive mixing by 50% on average.
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Mar 03, 2022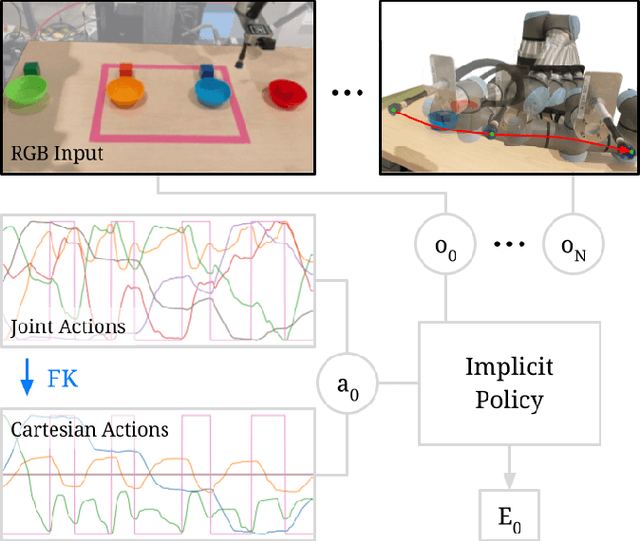
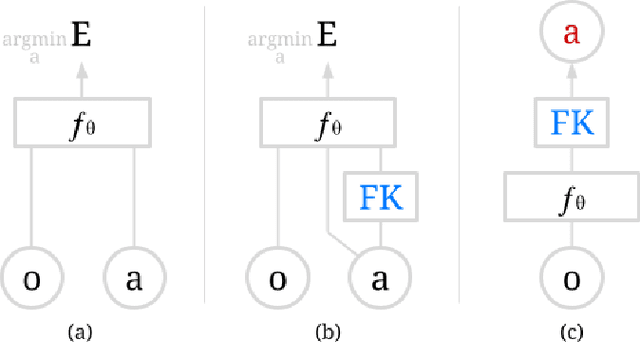
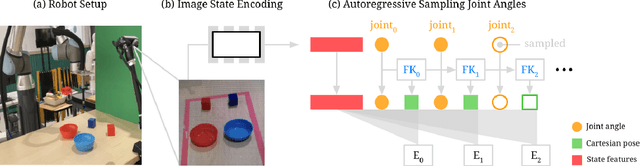
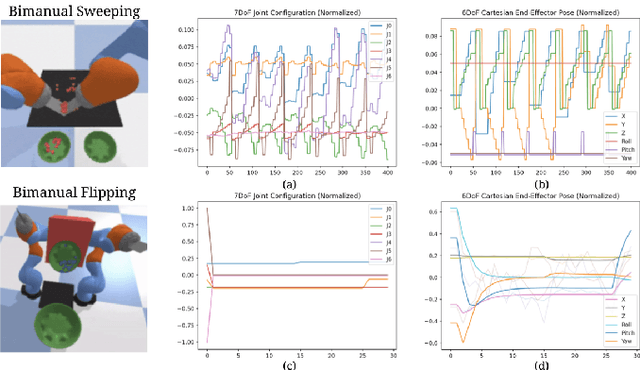
Action representation is an important yet often overlooked aspect in end-to-end robot learning with deep networks. Choosing one action space over another (e.g. target joint positions, or Cartesian end-effector poses) can result in surprisingly stark performance differences between various downstream tasks -- and as a result, considerable research has been devoted to finding the right action space for a given application. However, in this work, we instead investigate how our models can discover and learn for themselves which action space to use. Leveraging recent work on implicit behavioral cloning, which takes both observations and actions as input, we demonstrate that it is possible to present the same action in multiple different spaces to the same policy -- allowing it to learn inductive patterns from each space. Specifically, we study the benefits of combining Cartesian and joint action spaces in the context of learning manipulation skills. To this end, we present Implicit Kinematic Policies (IKP), which incorporates the kinematic chain as a differentiable module within the deep network. Quantitative experiments across several simulated continuous control tasks -- from scooping piles of small objects, to lifting boxes with elbows, to precise block insertion with miscalibrated robots -- suggest IKP not only learns complex prehensile and non-prehensile manipulation from pixels better than baseline alternatives, but also can learn to compensate for small joint encoder offset errors. Finally, we also run qualitative experiments on a real UR5e to demonstrate the feasibility of our algorithm on a physical robotic system with real data. See https://tinyurl.com/4wz3nf86 for code and supplementary material.
Neural Abstructions: Abstractions that Support Construction for Grounded Language Learning
Jul 20, 2021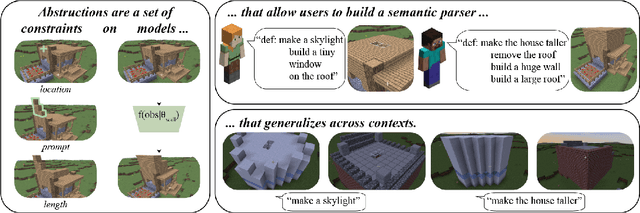


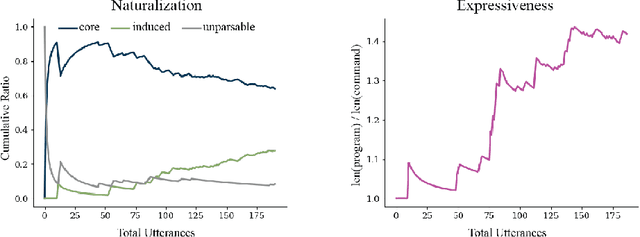
Although virtual agents are increasingly situated in environments where natural language is the most effective mode of interaction with humans, these exchanges are rarely used as an opportunity for learning. Leveraging language interactions effectively requires addressing limitations in the two most common approaches to language grounding: semantic parsers built on top of fixed object categories are precise but inflexible and end-to-end models are maximally expressive, but fickle and opaque. Our goal is to develop a system that balances the strengths of each approach so that users can teach agents new instructions that generalize broadly from a single example. We introduce the idea of neural abstructions: a set of constraints on the inference procedure of a label-conditioned generative model that can affect the meaning of the label in context. Starting from a core programming language that operates over abstructions, users can define increasingly complex mappings from natural language to actions. We show that with this method a user population is able to build a semantic parser for an open-ended house modification task in Minecraft. The semantic parser that results is both flexible and expressive: the percentage of utterances sourced from redefinitions increases steadily over the course of 191 total exchanges, achieving a final value of 28%.
SPLAT: Semantic Pixel-Level Adaptation Transforms for Detection
Dec 03, 2018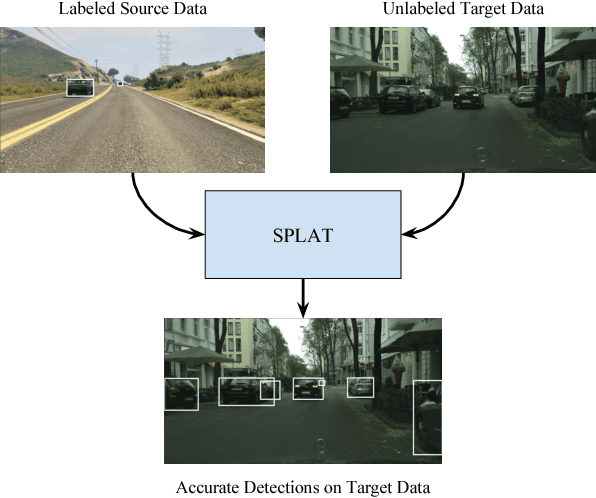


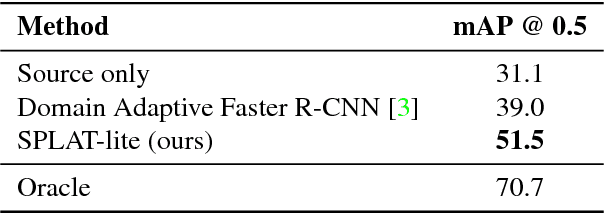
Domain adaptation of visual detectors is a critical challenge, yet existing methods have overlooked pixel appearance transformations, focusing instead on bootstrapping and/or domain confusion losses. We propose a Semantic Pixel-Level Adaptation Transform (SPLAT) approach to detector adaptation that efficiently generates cross-domain image pairs. Our model uses aligned-pair and/or pseudo-label losses to adapt an object detector to the target domain, and can learn transformations with or without densely labeled data in the source (e.g. semantic segmentation annotations). Without dense labels, as is the case when only detection labels are available in the source, transformations are learned using CycleGAN alignment. Otherwise, when dense labels are available we introduce a more efficient cycle-free method, which exploits pixel-level semantic labels to condition the training of the transformation network. The end task is then trained using detection box labels from the source, potentially including labels inferred on unlabeled source data. We show both that pixel-level transforms outperform prior approaches to detector domain adaptation, and that our cycle-free method outperforms prior models for unconstrained cycle-based learning of generic transformations while running 3.8 times faster. Our combined model improves on prior detection baselines by 12.5 mAP adapting from Sim 10K to Cityscapes, recovering over 50% of the missing performance between the unadapted baseline and the labeled-target upper bound.
Object Hallucination in Image Captioning
Sep 06, 2018


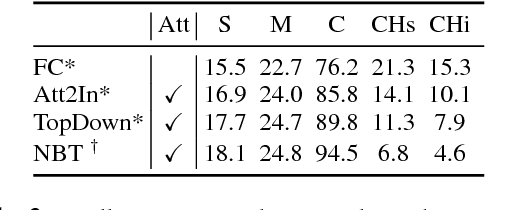
Despite continuously improving performance, contemporary image captioning models are prone to "hallucinating" objects that are not actually in a scene. One problem is that standard metrics only measure similarity to ground truth captions and may not fully capture image relevance. In this work, we propose a new image relevance metric to evaluate current models with veridical visual labels and assess their rate of object hallucination. We analyze how captioning model architectures and learning objectives contribute to object hallucination, explore when hallucination is likely due to image misclassification or language priors, and assess how well current sentence metrics capture object hallucination. We investigate these questions on the standard image caption- ing benchmark, MSCOCO, using a diverse set of models. Our analysis yields several interesting findings, including that models which score best on standard sentence metrics do not always have lower hallucination and that models which hallucinate more tend to make errors driven by language priors.