 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization
Mar 14, 2025Since the advent of popular visual generation frameworks like VQGAN and latent diffusion models, state-of-the-art image generation systems have generally been two-stage systems that first tokenize or compress visual data into a lower-dimensional latent space before learning a generative model. Tokenizer training typically follows a standard recipe in which images are compressed and reconstructed subject to a combination of MSE, perceptual, and adversarial losses. Diffusion autoencoders have been proposed in prior work as a way to learn end-to-end perceptually-oriented image compression, but have not yet shown state-of-the-art performance on the competitive task of ImageNet-1K reconstruction. We propose FlowMo, a transformer-based diffusion autoencoder that achieves a new state-of-the-art for image tokenization at multiple compression rates without using convolutions, adversarial losses, spatially-aligned two-dimensional latent codes, or distilling from other tokenizers. Our key insight is that FlowMo training should be broken into a mode-matching pre-training stage and a mode-seeking post-training stage. In addition, we conduct extensive analyses and explore the training of generative models atop the FlowMo tokenizer. Our code and models will be available at http://kylesargent.github.io/flowmo .
FSPO: Few-Shot Preference Optimization of Synthetic Preference Data in LLMs Elicits Effective Personalization to Real Users
Feb 26, 2025Effective personalization of LLMs is critical for a broad range of user-interfacing applications such as virtual assistants and content curation. Inspired by the strong in-context learning capabilities of LLMs, we propose Few-Shot Preference Optimization (FSPO), which reframes reward modeling as a meta-learning problem. Under this framework, an LLM learns to quickly adapt to a user via a few labeled preferences from that user, constructing a personalized reward function for them. Additionally, since real-world preference data is scarce and challenging to collect at scale, we propose careful design choices to construct synthetic preference datasets for personalization, generating over 1M synthetic personalized preferences using publicly available LLMs. In particular, to successfully transfer from synthetic data to real users, we find it crucial for the data to exhibit both high diversity and coherent, self-consistent structure. We evaluate FSPO on personalized open-ended generation for up to 1,500 synthetic users across across three domains: movie reviews, pedagogical adaptation based on educational background, and general question answering, along with a controlled human study. Overall, FSPO achieves an 87% Alpaca Eval winrate on average in generating responses that are personalized to synthetic users and a 72% winrate with real human users in open-ended question answering.
Don't Cut Corners: Exact Conditions for Modularity in Biologically Inspired Representations
Oct 08, 2024



Why do biological and artificial neurons sometimes modularise, each encoding a single meaningful variable, and sometimes entangle their representation of many variables? In this work, we develop a theory of when biologically inspired representations -- those that are nonnegative and energy efficient -- modularise with respect to source variables (sources). We derive necessary and sufficient conditions on a sample of sources that determine whether the neurons in an optimal biologically-inspired linear autoencoder modularise. Our theory applies to any dataset, extending far beyond the case of statistical independence studied in previous work. Rather, we show that sources modularise if their support is "sufficiently spread". From this theory, we extract and validate predictions in a variety of empirical studies on how data distribution affects modularisation in nonlinear feedforward and recurrent neural networks trained on supervised and unsupervised tasks. Furthermore, we apply these ideas to neuroscience data. First, we explain why two studies that recorded prefrontal activity in working memory tasks conflict on whether memories are encoded in orthogonal subspaces: the support of the sources differed due to a critical discrepancy in experimental protocol. Second, we use similar arguments to understand why preparatory and potent subspaces in RNN models of motor cortex are only sometimes orthogonal. Third, we study spatial and reward information mixing in entorhinal recordings, and show our theory matches data better than previous work. And fourth, we suggest a suite of surprising settings in which neurons can be (or appear) mixed selective, without requiring complex nonlinear readouts as in traditional theories. In sum, our theory prescribes precise conditions on when neural activities modularise, providing tools for inducing and elucidating modular representations in brains and machines.
Evaluating Real-World Robot Manipulation Policies in Simulation
May 09, 2024



The field of robotics has made significant advances towards generalist robot manipulation policies. However, real-world evaluation of such policies is not scalable and faces reproducibility challenges, which are likely to worsen as policies broaden the spectrum of tasks they can perform. We identify control and visual disparities between real and simulated environments as key challenges for reliable simulated evaluation and propose approaches for mitigating these gaps without needing to craft full-fidelity digital twins of real-world environments. We then employ these approaches to create SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. Through paired sim-and-real evaluations of manipulation policies, we demonstrate strong correlation between policy performance in SIMPLER environments and in the real world. Additionally, we find that SIMPLER evaluations accurately reflect real-world policy behavior modes such as sensitivity to various distribution shifts. We open-source all SIMPLER environments along with our workflow for creating new environments at https://simpler-env.github.io to facilitate research on general-purpose manipulation policies and simulated evaluation frameworks.
Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning
Apr 16, 2024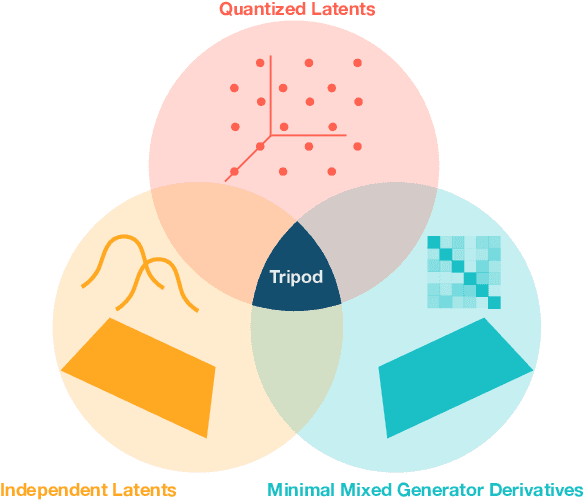


Inductive biases are crucial in disentangled representation learning for narrowing down an underspecified solution set. In this work, we consider endowing a neural network autoencoder with three select inductive biases from the literature: data compression into a grid-like latent space via quantization, collective independence amongst latents, and minimal functional influence of any latent on how other latents determine data generation. In principle, these inductive biases are deeply complementary: they most directly specify properties of the latent space, encoder, and decoder, respectively. In practice, however, naively combining existing techniques instantiating these inductive biases fails to yield significant benefits. To address this, we propose adaptations to the three techniques that simplify the learning problem, equip key regularization terms with stabilizing invariances, and quash degenerate incentives. The resulting model, Tripod, achieves state-of-the-art results on a suite of four image disentanglement benchmarks. We also verify that Tripod significantly improves upon its naive incarnation and that all three of its "legs" are necessary for best performance.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
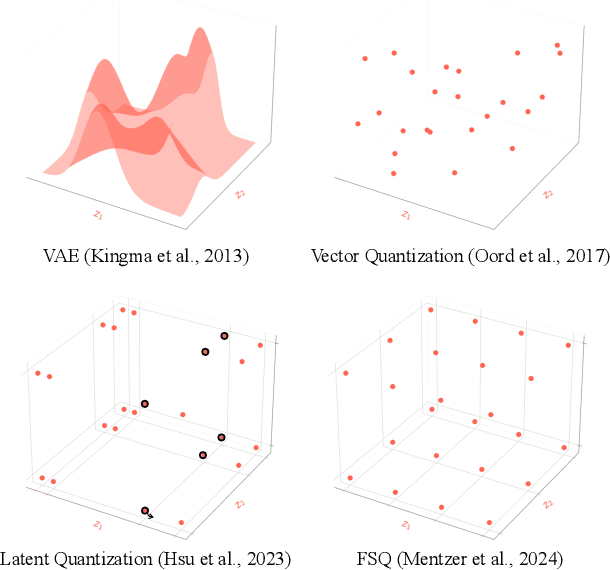
Disentanglement via Latent Quantization
May 28, 2023



In disentangled representation learning, a model is asked to tease apart a dataset's underlying sources of variation and represent them independently of one another. Since the model is provided with no ground truth information about these sources, inductive biases take a paramount role in enabling disentanglement. In this work, we construct an inductive bias towards compositionally encoding and decoding data by enforcing a harsh communication bottleneck. Concretely, we do this by (i) quantizing the latent space into learnable discrete codes with a separate scalar codebook per dimension and (ii) applying strong model regularization via an unusually high weight decay. Intuitively, the quantization forces the encoder to use a small number of latent values across many datapoints, which in turn enables the decoder to assign a consistent meaning to each value. Regularization then serves to drive the model towards this parsimonious strategy. We demonstrate the broad applicability of this approach by adding it to both basic data-reconstructing (vanilla autoencoder) and latent-reconstructing (InfoGAN) generative models. In order to reliably assess these models, we also propose InfoMEC, new metrics for disentanglement that are cohesively grounded in information theory and fix well-established shortcomings in previous metrics. Together with regularization, latent quantization dramatically improves the modularity and explicitness of learned representations on a representative suite of benchmark datasets. In particular, our quantized-latent autoencoder (QLAE) consistently outperforms strong methods from prior work in these key disentanglement properties without compromising data reconstruction.
Vision-Based Manipulators Need to Also See from Their Hands
Mar 15, 2022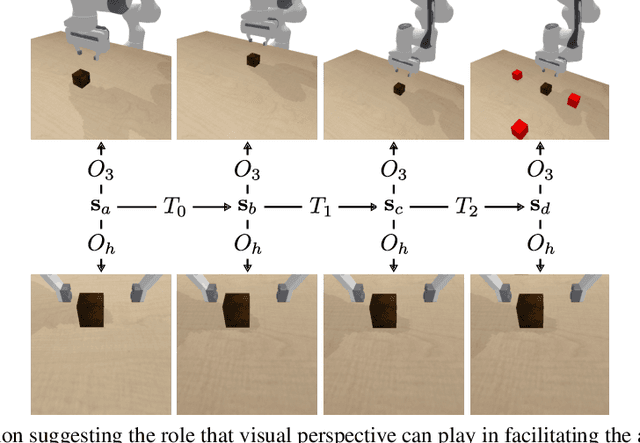


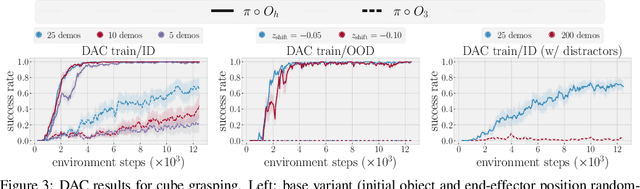
We study how the choice of visual perspective affects learning and generalization in the context of physical manipulation from raw sensor observations. Compared with the more commonly used global third-person perspective, a hand-centric (eye-in-hand) perspective affords reduced observability, but we find that it consistently improves training efficiency and out-of-distribution generalization. These benefits hold across a variety of learning algorithms, experimental settings, and distribution shifts, and for both simulated and real robot apparatuses. However, this is only the case when hand-centric observability is sufficient; otherwise, including a third-person perspective is necessary for learning, but also harms out-of-distribution generalization. To mitigate this, we propose to regularize the third-person information stream via a variational information bottleneck. On six representative manipulation tasks with varying hand-centric observability adapted from the Meta-World benchmark, this results in a state-of-the-art reinforcement learning agent operating from both perspectives improving its out-of-distribution generalization on every task. While some practitioners have long put cameras in the hands of robots, our work systematically analyzes the benefits of doing so and provides simple and broadly applicable insights for improving end-to-end learned vision-based robotic manipulation.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Differentiable Annealed Importance Sampling and the Perils of Gradient Noise
Jul 21, 2021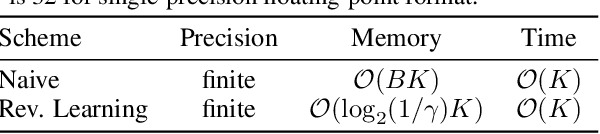
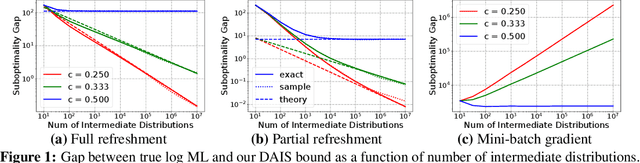

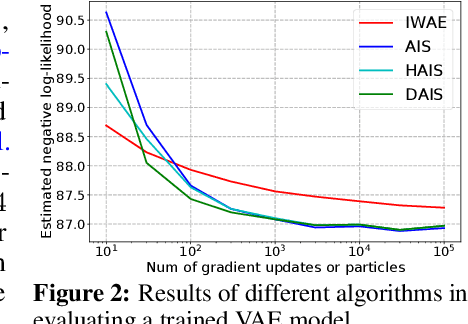
Annealed importance sampling (AIS) and related algorithms are highly effective tools for marginal likelihood estimation, but are not fully differentiable due to the use of Metropolis-Hastings (MH) correction steps. Differentiability is a desirable property as it would admit the possibility of optimizing marginal likelihood as an objective using gradient-based methods. To this end, we propose a differentiable AIS algorithm by abandoning MH steps, which further unlocks mini-batch computation. We provide a detailed convergence analysis for Bayesian linear regression which goes beyond previous analyses by explicitly accounting for non-perfect transitions. Using this analysis, we prove that our algorithm is consistent in the full-batch setting and provide a sublinear convergence rate. However, we show that the algorithm is inconsistent when mini-batch gradients are used due to a fundamental incompatibility between the goals of last-iterate convergence to the posterior and elimination of the pathwise stochastic error. This result is in stark contrast to our experience with stochastic optimization and stochastic gradient Langevin dynamics, where the effects of gradient noise can be washed out by taking more steps of a smaller size. Our negative result relies crucially on our explicit consideration of convergence to the stationary distribution, and it helps explain the difficulty of developing practically effective AIS-like algorithms that exploit mini-batch gradients.