 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcc-VLM: Occupancy Grounded Vision Language Model for Indoor Scene Understanding
Jun 18, 2026Recently, vision-language models (VLMs) have made significant progress in 3D scene understanding, driving advances in applications such as embodied intelligence and robotic vision. However, existing approaches typically either rely directly on explicit 3D inputs (e.g., point clouds or RGB-D sequences), or introduce an additional 3D geometry encoder to derive 3D-aware visual tokens from 2D images. Such designs structurally decouple 3D geometric perception from the rich 2D semantics learned via vision-language pre-training, hindering the development of a unified 3D vision-language representation. In this work, we propose Occ-VLM, a novel framework for 3D scene understanding that operates purely on posed RGB images and employs a single 2D vision encoder. Specifically, Occ-VLM reconstructs 3D scene occupancy as an auxiliary geometric prior, which is utilized to spatially associate foreground 2D tokens with 3D space. These tokens are then decoded by a Large Language Model (LLM) for unified scene understanding. Extensive experiments demonstrate that Occ-VLM achieves both accurate geometric perception and robust vision-language reasoning: it attains state-of-the-art performance on multi-view occupancy prediction, while performing on par with 3D-input VLMs on 3D Visual Question Answering (VQA) and 3D dense captioning benchmarks.
Agentic Discovery of Non-Canonical Antimicrobial Peptides with AMPGAN v3
Jun 15, 2026Antimicrobial resistance causes to over a million deaths annually. Antimicrobial peptides (AMPs) are a promising solution, but generative AMP models are not yet ready to design peptides with non-natural amino acids and/or chemical modifications, which are essential for real-world peptide drugs. We present AMPGAN v3, a multi-objective conditional GAN that expands the generative vocabulary to D-amino acids and N/C-terminus modifications such as amidation. By separating adversarial and activity-aware supervision across two specialized discriminators, AMPGAN v3 substantially improves training stability and outperforms prior generative AMP models on external classifiers. We validated five candidates spanning three structural classes in vitro; two showed activity against Gram-positive strains, with the best candidate reaching MIC 8 μg/mL against B. subtilis. To support downstream curation, we further present PepCraft, a multi-agent framework for end-to-end AMP discovery in which a Planning Agent orchestrates specialized executors for generation, filtering, and verification. Its prioritization recommendations align with our in vitro outcomes. Together, these contributions let us examine, on a small but real scale, how generative and agentic AI compose in therapeutic peptide discovery. Code: https://github.com/marszzibros/AMPGANv3
Looping Back to Move Forward: Recursive Transformers for Efficient and Flexible Large Multimodal Models
Feb 09, 2026Large Multimodal Models (LMMs) have achieved remarkable success in vision-language tasks, yet their vast parameter counts are often underutilized during both training and inference. In this work, we embrace the idea of looping back to move forward: reusing model parameters through recursive refinement to extract stronger multimodal representations without increasing model size. We propose RecursiveVLM, a recursive Transformer architecture tailored for LMMs. Two key innovations enable effective looping: (i) a Recursive Connector that aligns features across recursion steps by fusing intermediate-layer hidden states and applying modality-specific projections, respecting the distinct statistical structures of vision and language tokens; (ii) a Monotonic Recursion Loss that supervises every step and guarantees performance improves monotonically with recursion depth. This design transforms recursion into an on-demand refinement mechanism: delivering strong results with few loops on resource-constrained devices and progressively improving outputs when more computation resources are available. Experiments show consistent gains of +3% over standard Transformers and +7% over vanilla recursive baselines, demonstrating that strategic looping is a powerful path toward efficient, deployment-adaptive LMMs.
EventFlash: Towards Efficient MLLMs for Event-Based Vision
Feb 03, 2026Event-based multimodal large language models (MLLMs) enable robust perception in high-speed and low-light scenarios, addressing key limitations of frame-based MLLMs. However, current event-based MLLMs often rely on dense image-like processing paradigms, overlooking the spatiotemporal sparsity of event streams and resulting in high computational cost. In this paper, we propose EventFlash, a novel and efficient MLLM to explore spatiotemporal token sparsification for reducing data redundancy and accelerating inference. Technically, we build EventMind, a large-scale and scene-diverse dataset with over 500k instruction sets, providing both short and long event stream sequences to support our curriculum training strategy. We then present an adaptive temporal window aggregation module for efficient temporal sampling, which adaptively compresses temporal tokens while retaining key temporal cues. Finally, a sparse density-guided attention module is designed to improve spatial token efficiency by selecting informative regions and suppressing empty or sparse areas. Experimental results show that EventFlash achieves a $12.4\times$ throughput improvement over the baseline (EventFlash-Zero) while maintaining comparable performance. It supports long-range event stream processing with up to 1,000 bins, significantly outperforming the 5-bin limit of EventGPT. We believe EventFlash serves as an efficient foundation model for event-based vision.
Resource-Efficient Reinforcement for Reasoning Large Language Models via Dynamic One-Shot Policy Refinement
Jan 31, 2026Large language models (LLMs) have exhibited remarkable performance on complex reasoning tasks, with reinforcement learning under verifiable rewards (RLVR) emerging as a principled framework for aligning model behavior with reasoning chains. Despite its promise, RLVR remains prohibitively resource-intensive, requiring extensive reward signals and incurring substantial rollout costs during training. In this work, we revisit the fundamental question of data and compute efficiency in RLVR. We first establish a theoretical lower bound on the sample complexity required to unlock reasoning capabilities, and empirically validate that strong performance can be achieved with a surprisingly small number of training instances. To tackle the computational burden, we propose Dynamic One-Shot Policy Refinement (DoPR), an uncertainty-aware RL strategy that dynamically selects a single informative training sample per batch for policy updates, guided by reward volatility and exploration-driven acquisition. DoPR reduces rollout overhead by nearly an order of magnitude while preserving competitive reasoning accuracy, offering a scalable and resource-efficient solution for LLM post-training. This approach offers a practical path toward more efficient and accessible RL-based training for reasoning-intensive LLM applications.
NFCDS: A Plug-and-Play Noise Frequency-Controlled Diffusion Sampling Strategy for Image Restoration
Jan 29, 2026Diffusion sampling-based Plug-and-Play (PnP) methods produce images with high perceptual quality but often suffer from reduced data fidelity, primarily due to the noise introduced during reverse diffusion. To address this trade-off, we propose Noise Frequency-Controlled Diffusion Sampling (NFCDS), a spectral modulation mechanism for reverse diffusion noise. We show that the fidelity-perception conflict can be fundamentally understood through noise frequency: low-frequency components induce blur and degrade fidelity, while high-frequency components drive detail generation. Based on this insight, we design a Fourier-domain filter that progressively suppresses low-frequency noise and preserves high-frequency content. This controlled refinement injects a data-consistency prior directly into sampling, enabling fast convergence to results that are both high-fidelity and perceptually convincing--without additional training. As a PnP module, NFCDS seamlessly integrates into existing diffusion-based restoration frameworks and improves the fidelity-perception balance across diverse zero-shot tasks.
Learning to Remove Lens Flare in Event Camera
Dec 09, 2025Event cameras have the potential to revolutionize vision systems with their high temporal resolution and dynamic range, yet they remain susceptible to lens flare, a fundamental optical artifact that causes severe degradation. In event streams, this optical artifact forms a complex, spatio-temporal distortion that has been largely overlooked. We present E-Deflare, the first systematic framework for removing lens flare from event camera data. We first establish the theoretical foundation by deriving a physics-grounded forward model of the non-linear suppression mechanism. This insight enables the creation of the E-Deflare Benchmark, a comprehensive resource featuring a large-scale simulated training set, E-Flare-2.7K, and the first-ever paired real-world test set, E-Flare-R, captured by our novel optical system. Empowered by this benchmark, we design E-DeflareNet, which achieves state-of-the-art restoration performance. Extensive experiments validate our approach and demonstrate clear benefits for downstream tasks. Code and datasets are publicly available.
AUVIC: Adversarial Unlearning of Visual Concepts for Multi-modal Large Language Models
Nov 14, 2025Multimodal Large Language Models (MLLMs) achieve impressive performance once optimized on massive datasets. Such datasets often contain sensitive or copyrighted content, raising significant data privacy concerns. Regulatory frameworks mandating the 'right to be forgotten' drive the need for machine unlearning. This technique allows for the removal of target data without resource-consuming retraining. However, while well-studied for text, visual concept unlearning in MLLMs remains underexplored. A primary challenge is precisely removing a target visual concept without disrupting model performance on related entities. To address this, we introduce AUVIC, a novel visual concept unlearning framework for MLLMs. AUVIC applies adversarial perturbations to enable precise forgetting. This approach effectively isolates the target concept while avoiding unintended effects on similar entities. To evaluate our method, we construct VCUBench. It is the first benchmark designed to assess visual concept unlearning in group contexts. Experimental results demonstrate that AUVIC achieves state-of-the-art target forgetting rates while incurs minimal performance degradation on non-target concepts.
CoCo-MILP: Inter-Variable Contrastive and Intra-Constraint Competitive MILP Solution Prediction
Nov 12, 2025Mixed-Integer Linear Programming (MILP) is a cornerstone of combinatorial optimization, yet solving large-scale instances remains a significant computational challenge. Recently, Graph Neural Networks (GNNs) have shown promise in accelerating MILP solvers by predicting high-quality solutions. However, we identify that existing methods misalign with the intrinsic structure of MILP problems at two levels. At the leaning objective level, the Binary Cross-Entropy (BCE) loss treats variables independently, neglecting their relative priority and yielding plausible logits. At the model architecture level, standard GNN message passing inherently smooths the representations across variables, missing the natural competitive relationships within constraints. To address these challenges, we propose CoCo-MILP, which explicitly models inter-variable Contrast and intra-constraint Competition for advanced MILP solution prediction. At the objective level, CoCo-MILP introduces the Inter-Variable Contrastive Loss (VCL), which explicitly maximizes the embedding margin between variables assigned one versus zero. At the architectural level, we design an Intra-Constraint Competitive GNN layer that, instead of homogenizing features, learns to differentiate representations of competing variables within a constraint, capturing their exclusionary nature. Experimental results on standard benchmarks demonstrate that CoCo-MILP significantly outperforms existing learning-based approaches, reducing the solution gap by up to 68.12% compared to traditional solvers. Our code is available at https://github.com/happypu326/CoCo-MILP.
Long-Distance Field Demonstration of Imaging-Free Drone Identification in Intracity Environments
Apr 26, 2025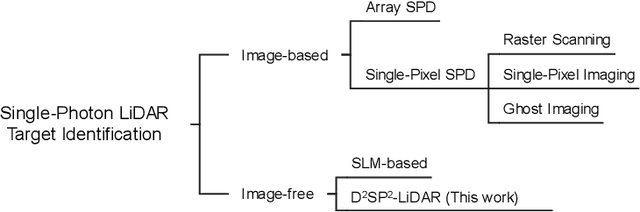
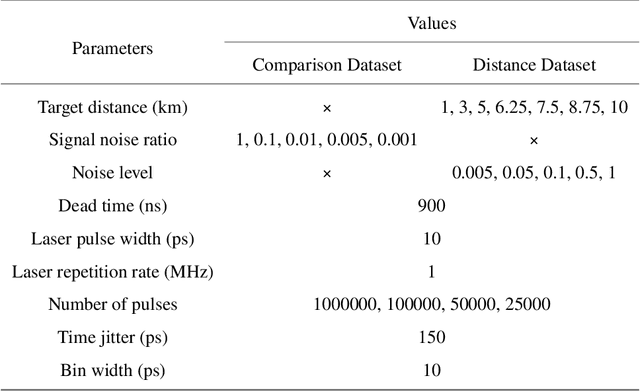
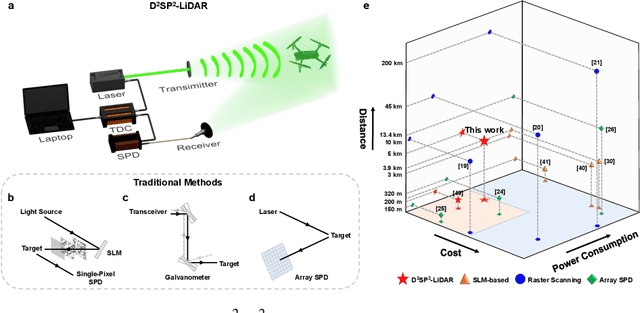
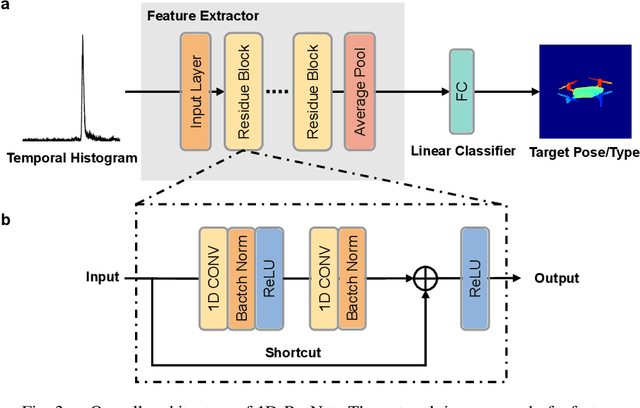
Detecting small objects, such as drones, over long distances presents a significant challenge with broad implications for security, surveillance, environmental monitoring, and autonomous systems. Traditional imaging-based methods rely on high-resolution image acquisition, but are often constrained by range, power consumption, and cost. In contrast, data-driven single-photon-single-pixel light detection and ranging (\text{D\textsuperscript{2}SP\textsuperscript{2}-LiDAR}) provides an imaging-free alternative, directly enabling target identification while reducing system complexity and cost. However, its detection range has been limited to a few hundred meters. Here, we introduce a novel integration of residual neural networks (ResNet) with \text{D\textsuperscript{2}SP\textsuperscript{2}-LiDAR}, incorporating a refined observation model to extend the detection range to 5~\si{\kilo\meter} in an intracity environment while enabling high-accuracy identification of drone poses and types. Experimental results demonstrate that our approach not only outperforms conventional imaging-based recognition systems, but also achieves 94.93\% pose identification accuracy and 97.99\% type classification accuracy, even under weak signal conditions with long distances and low signal-to-noise ratios (SNRs). These findings highlight the potential of imaging-free methods for robust long-range detection of small targets in real-world scenarios.