 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-wise Parallelizable Spiking Neuron with Multiplication-free Dynamics and Large Temporal Receptive Fields
Jan 24, 2025Spiking Neural Networks (SNNs) are distinguished from Artificial Neural Networks (ANNs) for their sophisticated neuronal dynamics and sparse binary activations (spikes) inspired by the biological neural system. Traditional neuron models use iterative step-by-step dynamics, resulting in serial computation and slow training speed of SNNs. Recently, parallelizable spiking neuron models have been proposed to fully utilize the massive parallel computing ability of graphics processing units to accelerate the training of SNNs. However, existing parallelizable spiking neuron models involve dense floating operations and can only achieve high long-term dependencies learning ability with a large order at the cost of huge computational and memory costs. To solve the dilemma of performance and costs, we propose the mul-free channel-wise Parallel Spiking Neuron, which is hardware-friendly and suitable for SNNs' resource-restricted application scenarios. The proposed neuron imports the channel-wise convolution to enhance the learning ability, induces the sawtooth dilations to reduce the neuron order, and employs the bit shift operation to avoid multiplications. The algorithm for design and implementation of acceleration methods is discussed meticulously. Our methods are validated in neuromorphic Spiking Heidelberg Digits voices, sequential CIFAR images, and neuromorphic DVS-Lip vision datasets, achieving the best accuracy among SNNs. Training speed results demonstrate the effectiveness of our acceleration methods, providing a practical reference for future research.
HDI-Former: Hybrid Dynamic Interaction ANN-SNN Transformer for Object Detection Using Frames and Events
Nov 27, 2024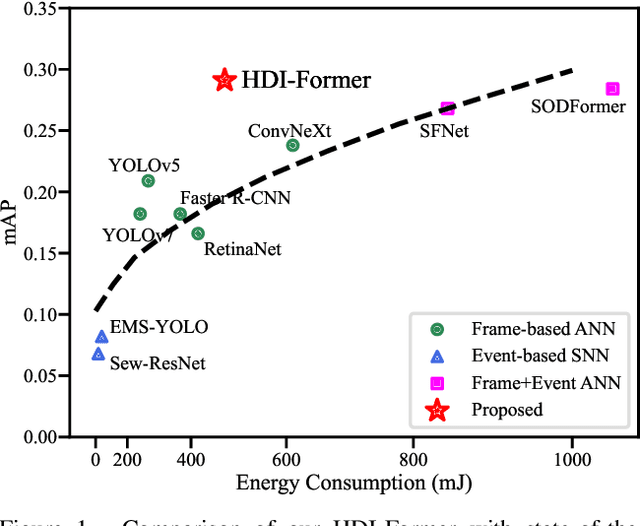
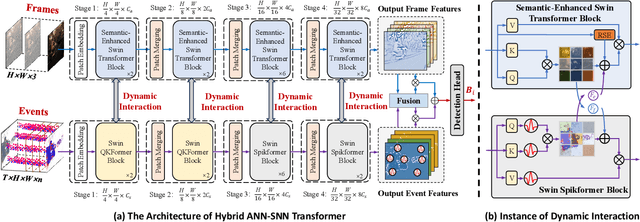

Combining the complementary benefits of frames and events has been widely used for object detection in challenging scenarios. However, most object detection methods use two independent Artificial Neural Network (ANN) branches, limiting cross-modality information interaction across the two visual streams and encountering challenges in extracting temporal cues from event streams with low power consumption. To address these challenges, we propose HDI-Former, a Hybrid Dynamic Interaction ANN-SNN Transformer, marking the first trial to design a directly trained hybrid ANN-SNN architecture for high-accuracy and energy-efficient object detection using frames and events. Technically, we first present a novel semantic-enhanced self-attention mechanism that strengthens the correlation between image encoding tokens within the ANN Transformer branch for better performance. Then, we design a Spiking Swin Transformer branch to model temporal cues from event streams with low power consumption. Finally, we propose a bio-inspired dynamic interaction mechanism between ANN and SNN sub-networks for cross-modality information interaction. The results demonstrate that our HDI-Former outperforms eleven state-of-the-art methods and our four baselines by a large margin. Our SNN branch also shows comparable performance to the ANN with the same architecture while consuming 10.57$\times$ less energy on the DSEC-Detection dataset. Our open-source code is available in the supplementary material.
Spatial-Temporal Search for Spiking Neural Networks
Oct 24, 2024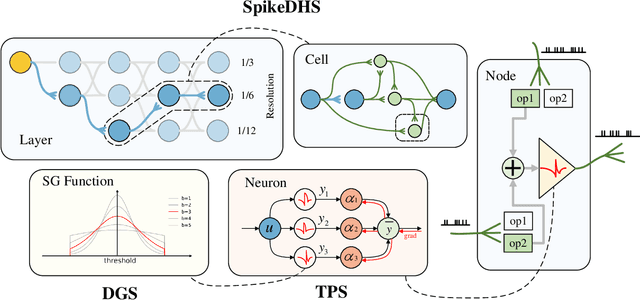

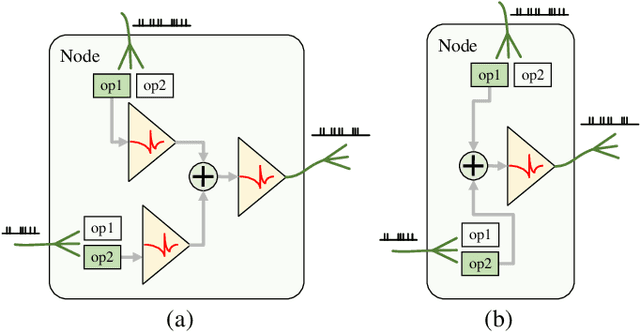
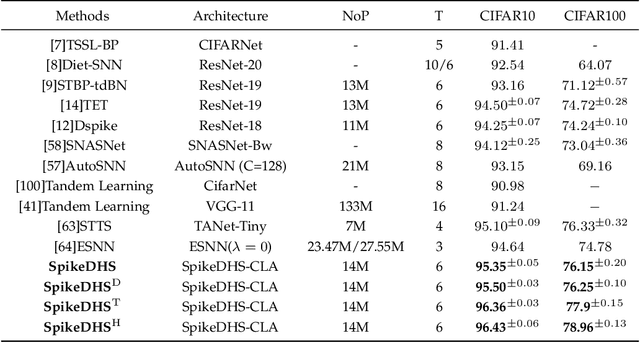
Spiking Neural Networks (SNNs) are considered as a potential candidate for the next generation of artificial intelligence with appealing characteristics such as sparse computation and inherent temporal dynamics. By adopting architectures of Artificial Neural Networks (ANNs), SNNs achieve competitive performances on benchmark tasks like image classification. However, successful architectures of ANNs are not optimal for SNNs. In this work, we apply Neural Architecture Search (NAS) to find suitable architectures for SNNs. Previous NAS methods for SNNs focus primarily on the spatial dimension, with a notable lack of consideration for the temporal dynamics that are of critical importance for SNNs. Drawing inspiration from the heterogeneity of biological neural networks, we propose a differentiable approach to optimize SNN on both spatial and temporal dimensions. At spatial level, we have developed a spike-based differentiable hierarchical search (SpikeDHS) framework, where spike-based operation is optimized on both the cell and the layer level under computational constraints. We further propose a differentiable surrogate gradient search (DGS) method to evolve local SG functions independently during training. At temporal level, we explore an optimal configuration of diverse temporal dynamics on different types of spiking neurons by evolving their time constants, based on which we further develop hybrid networks combining SNN and ANN, balancing both accuracy and efficiency. Our methods achieve comparable classification performance of CIFAR10/100 and ImageNet with accuracies of 96.43%, 78.96%, and 70.21%, respectively. On event-based deep stereo, our methods find optimal layer variation and surpass the accuracy of specially designed ANNs with 26$\times$ lower computational cost ($6.7\mathrm{mJ}$), demonstrating the potential of SNN in processing highly sparse and dynamic signals.
Direct Training High-Performance Deep Spiking Neural Networks: A Review of Theories and Methods
May 06, 2024



Spiking neural networks (SNNs) offer a promising energy-efficient alternative to artificial neural networks (ANNs), in virtue of their high biological plausibility, rich spatial-temporal dynamics, and event-driven computation. The direct training algorithms based on the surrogate gradient method provide sufficient flexibility to design novel SNN architectures and explore the spatial-temporal dynamics of SNNs. According to previous studies, the performance of models is highly dependent on their sizes. Recently, direct training deep SNNs have achieved great progress on both neuromorphic datasets and large-scale static datasets. Notably, transformer-based SNNs show comparable performance with their ANN counterparts. In this paper, we provide a new perspective to summarize the theories and methods for training deep SNNs with high performance in a systematic and comprehensive way, including theory fundamentals, spiking neuron models, advanced SNN models and residual architectures, software frameworks and neuromorphic hardware, applications, and future trends. The reviewed papers are collected at https://github.com/zhouchenlin2096/Awesome-Spiking-Neural-Networks
UNIAA: A Unified Multi-modal Image Aesthetic Assessment Baseline and Benchmark
Apr 15, 2024
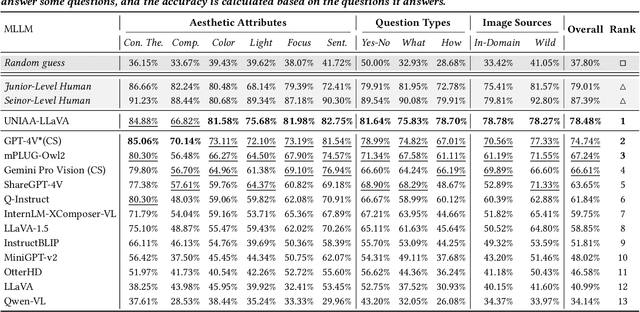
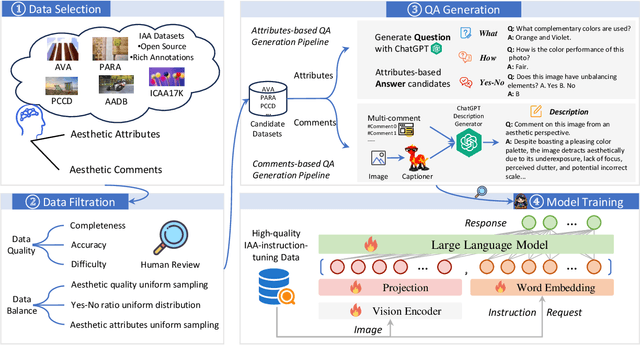
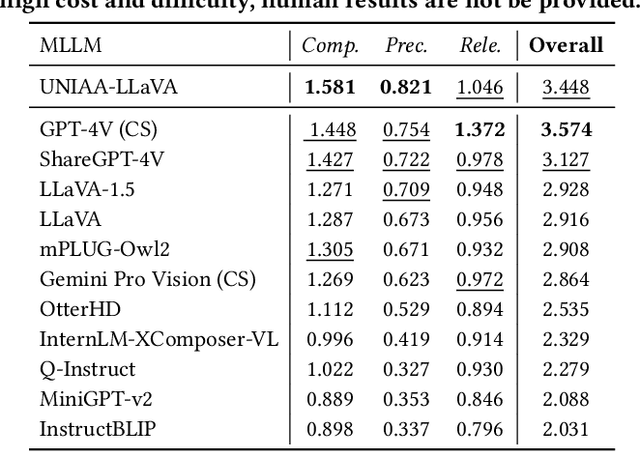
As an alternative to expensive expert evaluation, Image Aesthetic Assessment (IAA) stands out as a crucial task in computer vision. However, traditional IAA methods are typically constrained to a single data source or task, restricting the universality and broader application. In this work, to better align with human aesthetics, we propose a Unified Multi-modal Image Aesthetic Assessment (UNIAA) framework, including a Multi-modal Large Language Model (MLLM) named UNIAA-LLaVA and a comprehensive benchmark named UNIAA-Bench. We choose MLLMs with both visual perception and language ability for IAA and establish a low-cost paradigm for transforming the existing datasets into unified and high-quality visual instruction tuning data, from which the UNIAA-LLaVA is trained. To further evaluate the IAA capability of MLLMs, we construct the UNIAA-Bench, which consists of three aesthetic levels: Perception, Description, and Assessment. Extensive experiments validate the effectiveness and rationality of UNIAA. UNIAA-LLaVA achieves competitive performance on all levels of UNIAA-Bench, compared with existing MLLMs. Specifically, our model performs better than GPT-4V in aesthetic perception and even approaches the junior-level human. We find MLLMs have great potential in IAA, yet there remains plenty of room for further improvement. The UNIAA-LLaVA and UNIAA-Bench will be released.
QKFormer: Hierarchical Spiking Transformer using Q-K Attention
Mar 25, 2024



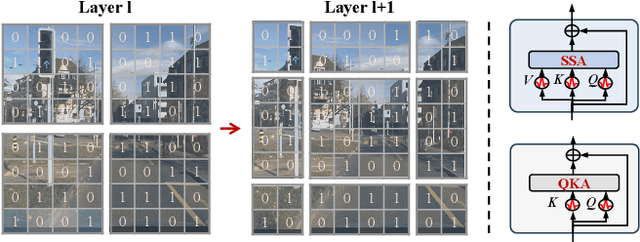
Spiking Transformers, which integrate Spiking Neural Networks (SNNs) with Transformer architectures, have attracted significant attention due to their potential for energy efficiency and high performance. However, existing models in this domain still suffer from suboptimal performance. We introduce several innovations to improve the performance: i) We propose a novel spike-form Q-K attention mechanism, tailored for SNNs, which efficiently models the importance of token or channel dimensions through binary vectors with linear complexity. ii) We incorporate the hierarchical structure, which significantly benefits the performance of both the brain and artificial neural networks, into spiking transformers to obtain multi-scale spiking representation. iii) We design a versatile and powerful patch embedding module with a deformed shortcut specifically for spiking transformers. Together, we develop QKFormer, a hierarchical spiking transformer based on Q-K attention with direct training. QKFormer shows significantly superior performance over existing state-of-the-art SNN models on various mainstream datasets. Notably, with comparable size to Spikformer (66.34 M, 74.81%), QKFormer (64.96 M) achieves a groundbreaking top-1 accuracy of 85.65% on ImageNet-1k, substantially outperforming Spikformer by 10.84%. To our best knowledge, this is the first time that directly training SNNs have exceeded 85% accuracy on ImageNet-1K. The code and models are publicly available at https://github.com/zhouchenlin2096/QKFormer
Spikformer V2: Join the High Accuracy Club on ImageNet with an SNN Ticket
Jan 04, 2024Spiking Neural Networks (SNNs), known for their biologically plausible architecture, face the challenge of limited performance. The self-attention mechanism, which is the cornerstone of the high-performance Transformer and also a biologically inspired structure, is absent in existing SNNs. To this end, we explore the potential of leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self-Attention (SSA) and Spiking Transformer (Spikformer). The SSA mechanism eliminates the need for softmax and captures the sparse visual feature employing spike-based Query, Key, and Value. This sparse computation without multiplication makes SSA efficient and energy-saving. Further, we develop a Spiking Convolutional Stem (SCS) with supplementary convolutional layers to enhance the architecture of Spikformer. The Spikformer enhanced with the SCS is referred to as Spikformer V2. To train larger and deeper Spikformer V2, we introduce a pioneering exploration of Self-Supervised Learning (SSL) within the SNN. Specifically, we pre-train Spikformer V2 with masking and reconstruction style inspired by the mainstream self-supervised Transformer, and then finetune the Spikformer V2 on the image classification on ImageNet. Extensive experiments show that Spikformer V2 outperforms other previous surrogate training and ANN2SNN methods. An 8-layer Spikformer V2 achieves an accuracy of 80.38% using 4 time steps, and after SSL, a 172M 16-layer Spikformer V2 reaches an accuracy of 81.10% with just 1 time step. To the best of our knowledge, this is the first time that the SNN achieves 80+% accuracy on ImageNet. The code will be available at Spikformer V2.
Dual Branch Network Towards Accurate Printed Mathematical Expression Recognition
Dec 14, 2023Over the past years, Printed Mathematical Expression Recognition (PMER) has progressed rapidly. However, due to the insufficient context information captured by Convolutional Neural Networks, some mathematical symbols might be incorrectly recognized or missed. To tackle this problem, in this paper, a Dual Branch transformer-based Network (DBN) is proposed to learn both local and global context information for accurate PMER. In our DBN, local and global features are extracted simultaneously, and a Context Coupling Module (CCM) is developed to complement the features between the global and local contexts. CCM adopts an interactive manner so that the coupled context clues are highly correlated to each expression symbol. Additionally, we design a Dynamic Soft Target (DST) strategy to utilize the similarities among symbol categories for reasonable label generation. Our experimental results have demonstrated that DBN can accurately recognize mathematical expressions and has achieved state-of-the-art performance.
Spike-driven Transformer
Jul 04, 2023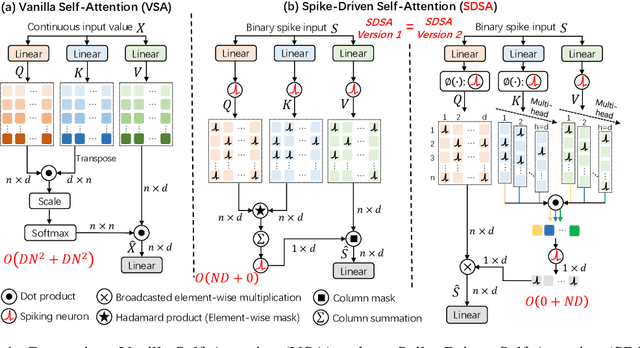
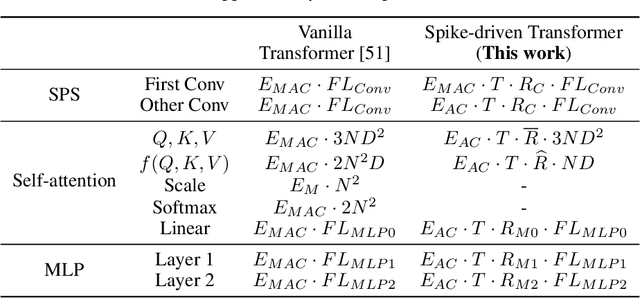
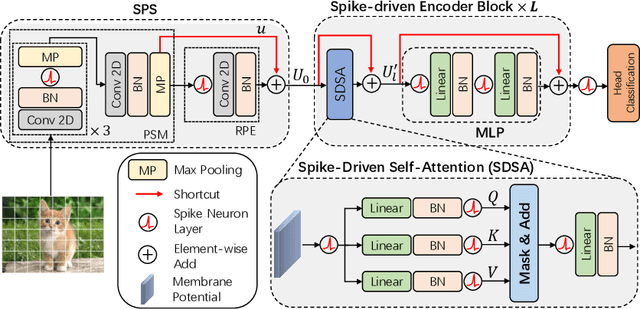

Spiking Neural Networks (SNNs) provide an energy-efficient deep learning option due to their unique spike-based event-driven (i.e., spike-driven) paradigm. In this paper, we incorporate the spike-driven paradigm into Transformer by the proposed Spike-driven Transformer with four unique properties: 1) Event-driven, no calculation is triggered when the input of Transformer is zero; 2) Binary spike communication, all matrix multiplications associated with the spike matrix can be transformed into sparse additions; 3) Self-attention with linear complexity at both token and channel dimensions; 4) The operations between spike-form Query, Key, and Value are mask and addition. Together, there are only sparse addition operations in the Spike-driven Transformer. To this end, we design a novel Spike-Driven Self-Attention (SDSA), which exploits only mask and addition operations without any multiplication, and thus having up to $87.2\times$ lower computation energy than vanilla self-attention. Especially in SDSA, the matrix multiplication between Query, Key, and Value is designed as the mask operation. In addition, we rearrange all residual connections in the vanilla Transformer before the activation functions to ensure that all neurons transmit binary spike signals. It is shown that the Spike-driven Transformer can achieve 77.1\% top-1 accuracy on ImageNet-1K, which is the state-of-the-art result in the SNN field. The source code is available at https://github.com/BICLab/Spike-Driven-Transformer.
Auto-Spikformer: Spikformer Architecture Search
Jun 01, 2023The integration of self-attention mechanisms into Spiking Neural Networks (SNNs) has garnered considerable interest in the realm of advanced deep learning, primarily due to their biological properties. Recent advancements in SNN architecture, such as Spikformer, have demonstrated promising outcomes by leveraging Spiking Self-Attention (SSA) and Spiking Patch Splitting (SPS) modules. However, we observe that Spikformer may exhibit excessive energy consumption, potentially attributable to redundant channels and blocks. To mitigate this issue, we propose Auto-Spikformer, a one-shot Transformer Architecture Search (TAS) method, which automates the quest for an optimized Spikformer architecture. To facilitate the search process, we propose methods Evolutionary SNN neurons (ESNN), which optimizes the SNN parameters, and apply the previous method of weight entanglement supernet training, which optimizes the Vision Transformer (ViT) parameters. Moreover, we propose an accuracy and energy balanced fitness function $\mathcal{F}_{AEB}$ that jointly considers both energy consumption and accuracy, and aims to find a Pareto optimal combination that balances these two objectives. Our experimental results demonstrate the effectiveness of Auto-Spikformer, which outperforms the state-of-the-art method including CNN or ViT models that are manually or automatically designed while significantly reducing energy consumption.