 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSP-Next: Efficient High-Quality Video Generation with Sparse Sequence Parallelism, HiF8 Quantization, and Reinforcement Learning
May 27, 2026Diffusion Transformers achieve strong video generation quality, but the quadratic cost of full attention limits efficiency. We introduce OSP-Next, an efficient text-to-video generation model that integrates sparse attention, parallelism, quantization, and reinforcement learning. OSP-Next uses a hybrid full-sparse attention architecture, where the sparse component is implemented with Skiparse-2D Attention. This fixed-pattern mechanism applies token-wise and group-wise sparse attention along spatial dimensions, leveraging locality while maintaining native compatibility with FlashAttention kernels. Based on the local equivalence of rearrangement in Skiparse-2D Attention, we further propose Sparse Sequence Parallelism (SSP), which partitions subsequences across ranks and switches sparse patterns through a single All-to-All communication. Compared with Ulysses Sequence Parallelism (SP), SSP provides a native parallel strategy for sparse attention and reduces communication volume by 75%. OSP-Next also incorporates HiF8 quantization to enable stable joint training with 8-bit quantization and sparse fine-tuning, and applies Mix-GRPO post-training to improve the performance of the sparse model. Experiments show that OSP-Next achieves a VBench total score of 83.73%, surpassing the Wan2.1 baseline. Under the 5-second 720P and 5-second 768P settings, OSP-Next achieves up to 1.64$\times$ single-GPU speedup and over 1.52$\times$ eight-GPU speedup on NVIDIA H200 GPUs. In addition, with only a 0.4% drop in VBench total score, OSP-Next-HiF8 achieves 1.69$\times$ and 2.27$\times$ speedups under the two settings on a single Ascend 950PR, demonstrating the efficiency and performance of OSP-Next across hardware platforms.
StepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
VecAttention: Vector-wise Sparse Attention for Accelerating Long Context Inference
Mar 31, 2026Long-context video understanding and generation pose a significant computational challenge for Transformer-based video models due to the quadratic complexity of self-attention. While existing sparse attention methods employ coarse-grained patterns to improve efficiency, they typically incur redundant computation and suboptimal performance. To address this issue, in this paper, we propose \textbf{VecAttention}, a novel framework of vector-wise sparse attention that achieves superior accuracy-efficiency trade-offs for video models. We observe that video attention maps exhibit a strong vertical-vector sparse pattern, and further demonstrate that this vertical-vector pattern offers consistently better accuracy-sparsity trade-offs compared with existing coarse-grained sparse patterns. Based on this observation, VecAttention dynamically selects and processes only informative vertical vectors through a lightweight important-vector selection that minimizes memory access overhead and an optimized kernel of vector sparse attention. Comprehensive evaluations on video understanding (VideoMME, LongVideoBench, and VCRBench) and generation (VBench) tasks show that VecAttention delivers a 2.65$\times$ speedup over full attention and a 1.83$\times$ speedup over state-of-the-art sparse attention methods, with comparable accuracy to full attention. Our code is available at https://github.com/anminliu/VecAttention.
Manifold-Aware Exploration for Reinforcement Learning in Video Generation
Mar 23, 2026Group Relative Policy Optimization (GRPO) methods for video generation like FlowGRPO remain far less reliable than their counterparts for language models and images. This gap arises because video generation has a complex solution space, and the ODE-to-SDE conversion used for exploration can inject excess noise, lowering rollout quality and making reward estimates less reliable, which destabilizes post-training alignment. To address this problem, we view the pre-trained model as defining a valid video data manifold and formulate the core problem as constraining exploration within the vicinity of this manifold, ensuring that rollout quality is preserved and reward estimates remain reliable. We propose SAGE-GRPO (Stable Alignment via Exploration), which applies constraints at both micro and macro levels. At the micro level, we derive a precise manifold-aware SDE with a logarithmic curvature correction and introduce a gradient norm equalizer to stabilize sampling and updates across timesteps. At the macro level, we use a dual trust region with a periodic moving anchor and stepwise constraints so that the trust region tracks checkpoints that are closer to the manifold and limits long-horizon drift. We evaluate SAGE-GRPO on HunyuanVideo1.5 using the original VideoAlign as the reward model and observe consistent gains over previous methods in VQ, MQ, TA, and visual metrics (CLIPScore, PickScore), demonstrating superior performance in both reward maximization and overall video quality. The code and visual gallery are available at https://dungeonmassster.github.io/SAGE-GRPO-Page/.
iFSQ: Improving FSQ for Image Generation with 1 Line of Code
Jan 27, 2026The field of image generation is currently bifurcated into autoregressive (AR) models operating on discrete tokens and diffusion models utilizing continuous latents. This divide, rooted in the distinction between VQ-VAEs and VAEs, hinders unified modeling and fair benchmarking. Finite Scalar Quantization (FSQ) offers a theoretical bridge, yet vanilla FSQ suffers from a critical flaw: its equal-interval quantization can cause activation collapse. This mismatch forces a trade-off between reconstruction fidelity and information efficiency. In this work, we resolve this dilemma by simply replacing the activation function in original FSQ with a distribution-matching mapping to enforce a uniform prior. Termed iFSQ, this simple strategy requires just one line of code yet mathematically guarantees both optimal bin utilization and reconstruction precision. Leveraging iFSQ as a controlled benchmark, we uncover two key insights: (1) The optimal equilibrium between discrete and continuous representations lies at approximately 4 bits per dimension. (2) Under identical reconstruction constraints, AR models exhibit rapid initial convergence, whereas diffusion models achieve a superior performance ceiling, suggesting that strict sequential ordering may limit the upper bounds of generation quality. Finally, we extend our analysis by adapting Representation Alignment (REPA) to AR models, yielding LlamaGen-REPA. Codes is available at https://github.com/Tencent-Hunyuan/iFSQ
Performance Analysis of End-to-End LEO Satellite-Aided Shore-to-Ship Communications: A Stochastic Geometry Approach
Oct 23, 2025Low Earth orbit (LEO) satellite networks have shown strategic superiority in maritime communications, assisting in establishing signal transmissions from shore to ship through space-based links. Traditional performance modeling based on multiple circular orbits is challenging to characterize large-scale LEO satellite constellations, thus requiring a tractable approach to accurately evaluate the network performance. In this paper, we propose a theoretical framework for an LEO satellite-aided shore-to-ship communication network (LEO-SSCN), where LEO satellites are distributed as a binomial point process (BPP) on a specific spherical surface. The framework aims to obtain the end-to-end transmission performance by considering signal transmissions through either a marine link or a space link subject to Rician or Shadowed Rician fading, respectively. Due to the indeterminate position of the serving satellite, accurately modeling the distance from the serving satellite to the destination ship becomes intractable. To address this issue, we propose a distance approximation approach. Then, by approximation and incorporating a threshold-based communication scheme, we leverage stochastic geometry to derive analytical expressions of end-to-end transmission success probability and average transmission rate capacity. Extensive numerical results verify the accuracy of the analysis and demonstrate the effect of key parameters on the performance of LEO-SSCN.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025



In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
May 28, 2025Subject-to-Video (S2V) generation aims to create videos that faithfully incorporate reference content, providing enhanced flexibility in the production of videos. To establish the infrastructure for S2V generation, we propose OpenS2V-Nexus, consisting of (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. In contrast to existing S2V benchmarks inherited from VBench that focus on global and coarse-grained assessment of generated videos, OpenS2V-Eval focuses on the model's ability to generate subject-consistent videos with natural subject appearance and identity fidelity. For these purposes, OpenS2V-Eval introduces 180 prompts from seven major categories of S2V, which incorporate both real and synthetic test data. Furthermore, to accurately align human preferences with S2V benchmarks, we propose three automatic metrics, NexusScore, NaturalScore and GmeScore, to separately quantify subject consistency, naturalness, and text relevance in generated videos. Building on this, we conduct a comprehensive evaluation of 16 representative S2V models, highlighting their strengths and weaknesses across different content. Moreover, we create the first open-source large-scale S2V generation dataset OpenS2V-5M, which consists of five million high-quality 720P subject-text-video triples. Specifically, we ensure subject-information diversity in our dataset by (1) segmenting subjects and building pairing information via cross-video associations and (2) prompting GPT-Image-1 on raw frames to synthesize multi-view representations. Through OpenS2V-Nexus, we deliver a robust infrastructure to accelerate future S2V generation research.
ImgEdit: A Unified Image Editing Dataset and Benchmark
May 26, 2025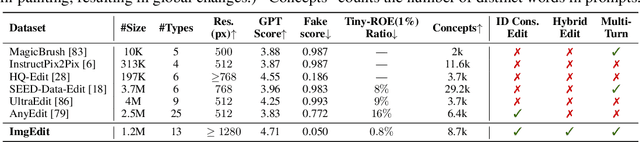
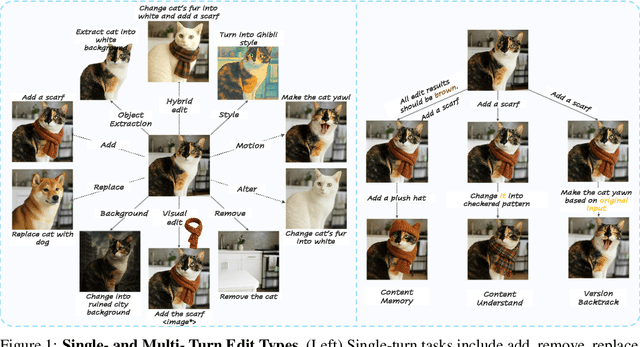
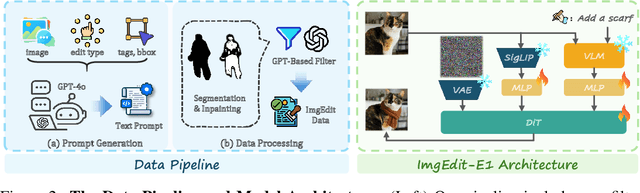

Recent advancements in generative models have enabled high-fidelity text-to-image generation. However, open-source image-editing models still lag behind their proprietary counterparts, primarily due to limited high-quality data and insufficient benchmarks. To overcome these limitations, we introduce ImgEdit, a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks. To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality. Using ImgEdit, we train ImgEdit-E1, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design. For comprehensive evaluation, we introduce ImgEdit-Bench, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation. It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite. We evaluate both open-source and proprietary models, as well as ImgEdit-E1, providing deep analysis and actionable insights into the current behavior of image-editing models. The source data are publicly available on https://github.com/PKU-YuanGroup/ImgEdit.
SwapAnyone: Consistent and Realistic Video Synthesis for Swapping Any Person into Any Video
Mar 12, 2025
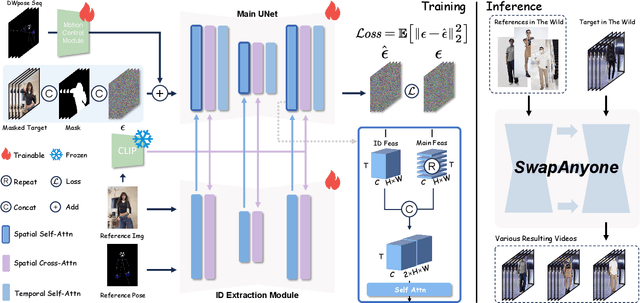
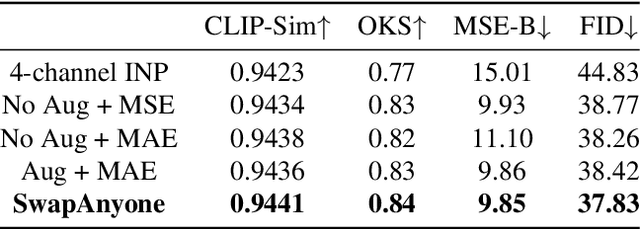

Video body-swapping aims to replace the body in an existing video with a new body from arbitrary sources, which has garnered more attention in recent years. Existing methods treat video body-swapping as a composite of multiple tasks instead of an independent task and typically rely on various models to achieve video body-swapping sequentially. However, these methods fail to achieve end-to-end optimization for the video body-swapping which causes issues such as variations in luminance among frames, disorganized occlusion relationships, and the noticeable separation between bodies and background. In this work, we define video body-swapping as an independent task and propose three critical consistencies: identity consistency, motion consistency, and environment consistency. We introduce an end-to-end model named SwapAnyone, treating video body-swapping as a video inpainting task with reference fidelity and motion control. To improve the ability to maintain environmental harmony, particularly luminance harmony in the resulting video, we introduce a novel EnvHarmony strategy for training our model progressively. Additionally, we provide a dataset named HumanAction-32K covering various videos about human actions. Extensive experiments demonstrate that our method achieves State-Of-The-Art (SOTA) performance among open-source methods while approaching or surpassing closed-source models across multiple dimensions. All code, model weights, and the HumanAction-32K dataset will be open-sourced at https://github.com/PKU-YuanGroup/SwapAnyone.