 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
Feb 02, 2026While text-to-image generation has achieved unprecedented fidelity, the vast majority of existing models function fundamentally as static text-to-pixel decoders. Consequently, they often fail to grasp implicit user intentions. Although emerging unified understanding-generation models have improved intent comprehension, they still struggle to accomplish tasks involving complex knowledge reasoning within a single model. Moreover, constrained by static internal priors, these models remain unable to adapt to the evolving dynamics of the real world. To bridge these gaps, we introduce Mind-Brush, a unified agentic framework that transforms generation into a dynamic, knowledge-driven workflow. Simulating a human-like 'think-research-create' paradigm, Mind-Brush actively retrieves multimodal evidence to ground out-of-distribution concepts and employs reasoning tools to resolve implicit visual constraints. To rigorously evaluate these capabilities, we propose Mind-Bench, a comprehensive benchmark comprising 500 distinct samples spanning real-time news, emerging concepts, and domains such as mathematical and Geo-Reasoning. Extensive experiments demonstrate that Mind-Brush significantly enhances the capabilities of unified models, realizing a zero-to-one capability leap for the Qwen-Image baseline on Mind-Bench, while achieving superior results on established benchmarks like WISE and RISE.
OmniAID: Decoupling Semantic and Artifacts for Universal AI-Generated Image Detection in the Wild
Nov 11, 2025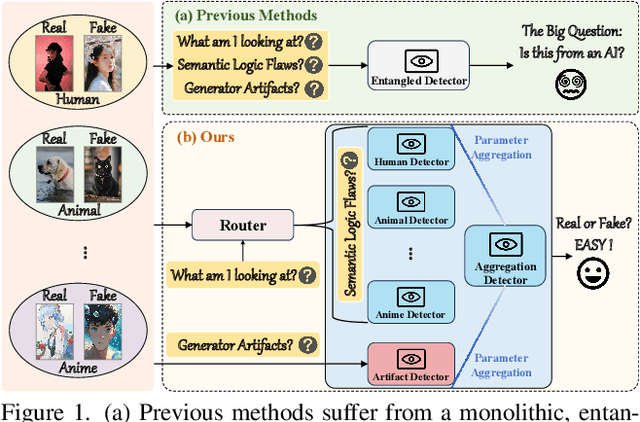
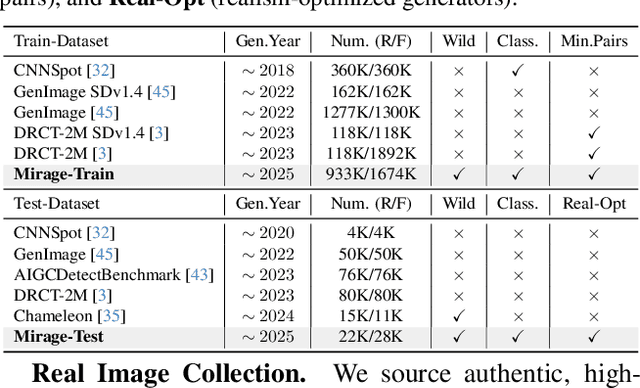
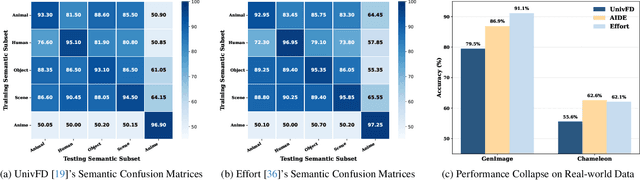
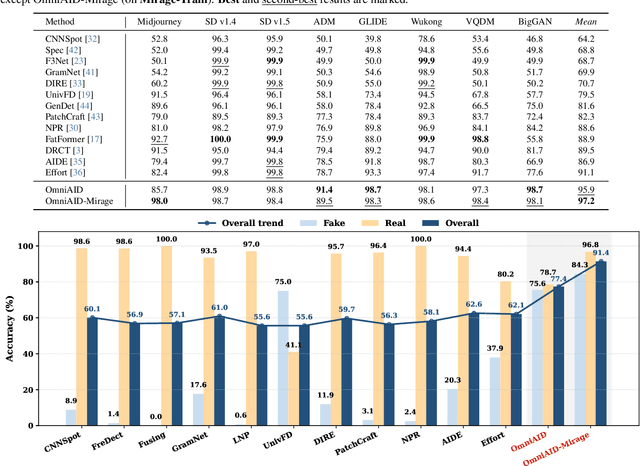
A truly universal AI-Generated Image (AIGI) detector must simultaneously generalize across diverse generative models and varied semantic content. Current state-of-the-art methods learn a single, entangled forgery representation--conflating content-dependent flaws with content-agnostic artifacts--and are further constrained by outdated benchmarks. To overcome these limitations, we propose OmniAID, a novel framework centered on a decoupled Mixture-of-Experts (MoE) architecture. The core of our method is a hybrid expert system engineered to decouple: (1) semantic flaws across distinct content domains, and (2) these content-dependent flaws from content-agnostic universal artifacts. This system employs a set of Routable Specialized Semantic Experts, each for a distinct domain (e.g., human, animal), complemented by a Fixed Universal Artifact Expert. This architecture is trained using a bespoke two-stage strategy: we first train the experts independently with domain-specific hard-sampling to ensure specialization, and subsequently train a lightweight gating network for effective input routing. By explicitly decoupling "what is generated" (content-specific flaws) from "how it is generated" (universal artifacts), OmniAID achieves robust generalization. To address outdated benchmarks and validate real-world applicability, we introduce Mirage, a new large-scale, contemporary dataset. Extensive experiments, using both traditional benchmarks and our Mirage dataset, demonstrate our model surpasses existing monolithic detectors, establishing a new, robust standard for AIGI authentication against modern, in-the-wild threats.
UrbanFeel: A Comprehensive Benchmark for Temporal and Perceptual Understanding of City Scenes through Human Perspective
Sep 26, 2025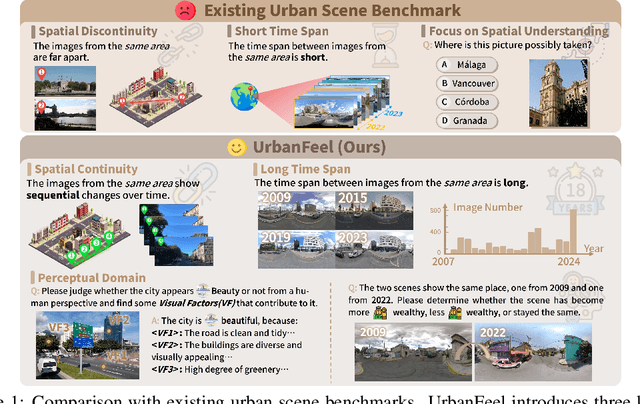
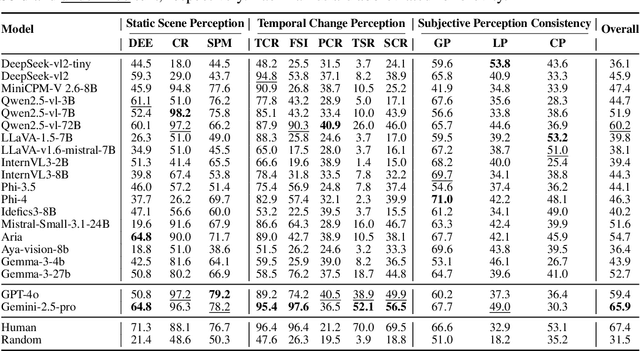

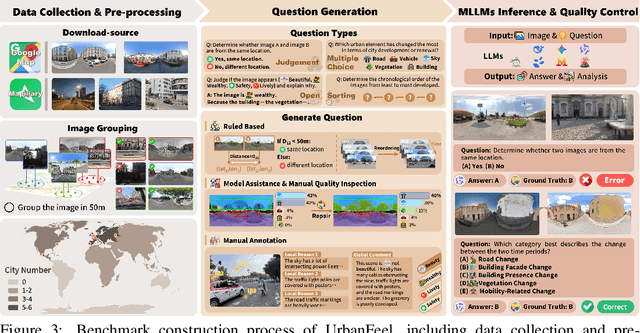
Urban development impacts over half of the global population, making human-centered understanding of its structural and perceptual changes essential for sustainable development. While Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various domains, existing benchmarks that explore their performance in urban environments remain limited, lacking systematic exploration of temporal evolution and subjective perception of urban environment that aligns with human perception. To address these limitations, we propose UrbanFeel, a comprehensive benchmark designed to evaluate the performance of MLLMs in urban development understanding and subjective environmental perception. UrbanFeel comprises 14.3K carefully constructed visual questions spanning three cognitively progressive dimensions: Static Scene Perception, Temporal Change Understanding, and Subjective Environmental Perception. We collect multi-temporal single-view and panoramic street-view images from 11 representative cities worldwide, and generate high-quality question-answer pairs through a hybrid pipeline of spatial clustering, rule-based generation, model-assisted prompting, and manual annotation. Through extensive evaluation of 20 state-of-the-art MLLMs, we observe that Gemini-2.5 Pro achieves the best overall performance, with its accuracy approaching human expert levels and narrowing the average gap to just 1.5\%. Most models perform well on tasks grounded in scene understanding. In particular, some models even surpass human annotators in pixel-level change detection. However, performance drops notably in tasks requiring temporal reasoning over urban development. Additionally, in the subjective perception dimension, several models reach human-level or even higher consistency in evaluating dimension such as beautiful and safety.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025



In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
Aug 13, 2025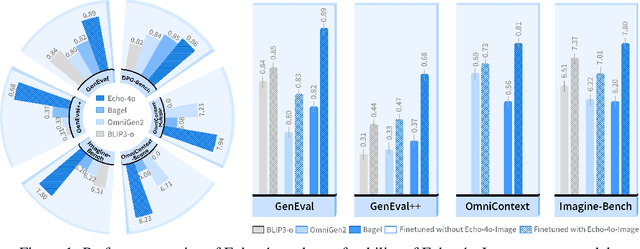
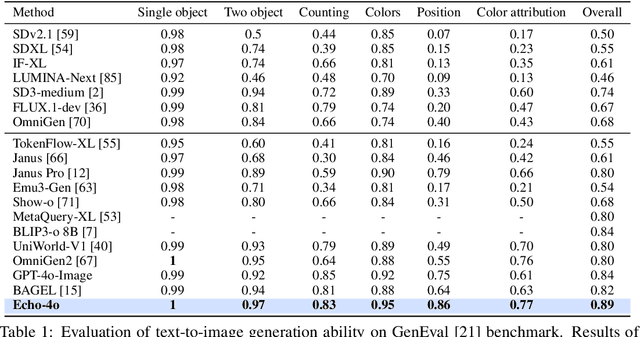
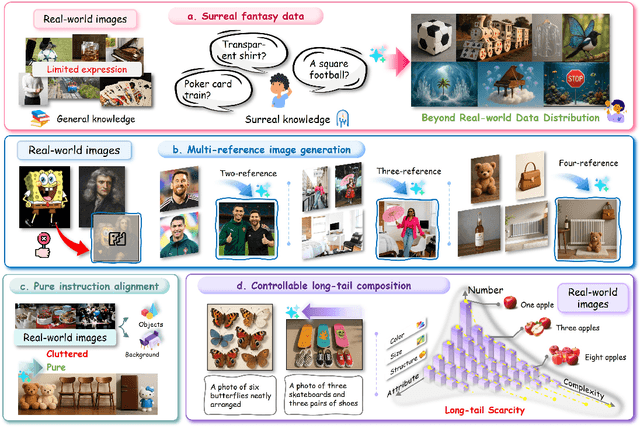
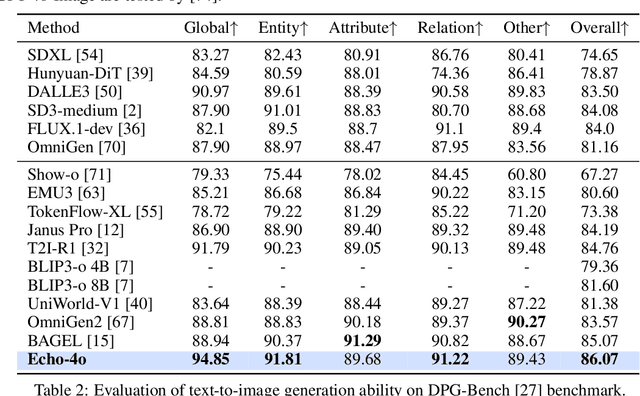
Recently, GPT-4o has garnered significant attention for its strong performance in image generation, yet open-source models still lag behind. Several studies have explored distilling image data from GPT-4o to enhance open-source models, achieving notable progress. However, a key question remains: given that real-world image datasets already constitute a natural source of high-quality data, why should we use GPT-4o-generated synthetic data? In this work, we identify two key advantages of synthetic images. First, they can complement rare scenarios in real-world datasets, such as surreal fantasy or multi-reference image generation, which frequently occur in user queries. Second, they provide clean and controllable supervision. Real-world data often contains complex background noise and inherent misalignment between text descriptions and image content, whereas synthetic images offer pure backgrounds and long-tailed supervision signals, facilitating more accurate text-to-image alignment. Building on these insights, we introduce Echo-4o-Image, a 180K-scale synthetic dataset generated by GPT-4o, harnessing the power of synthetic image data to address blind spots in real-world coverage. Using this dataset, we fine-tune the unified multimodal generation baseline Bagel to obtain Echo-4o. In addition, we propose two new evaluation benchmarks for a more accurate and challenging assessment of image generation capabilities: GenEval++, which increases instruction complexity to mitigate score saturation, and Imagine-Bench, which focuses on evaluating both the understanding and generation of imaginative content. Echo-4o demonstrates strong performance across standard benchmarks. Moreover, applying Echo-4o-Image to other foundation models (e.g., OmniGen2, BLIP3-o) yields consistent performance gains across multiple metrics, highlighting the datasets strong transferability.
GPT-ImgEval: A Comprehensive Benchmark for Diagnosing GPT4o in Image Generation
Apr 03, 2025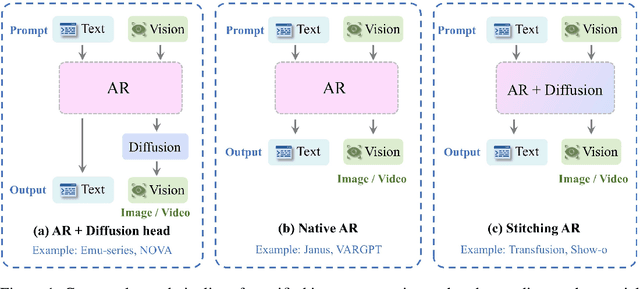
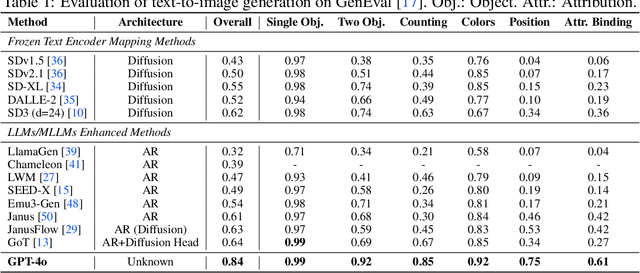
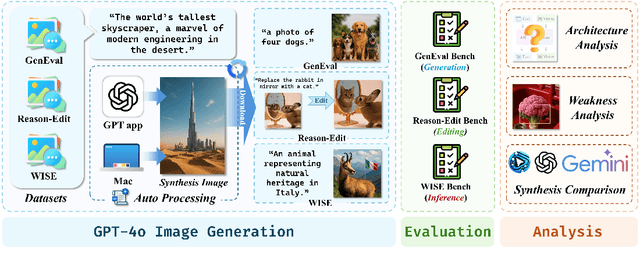
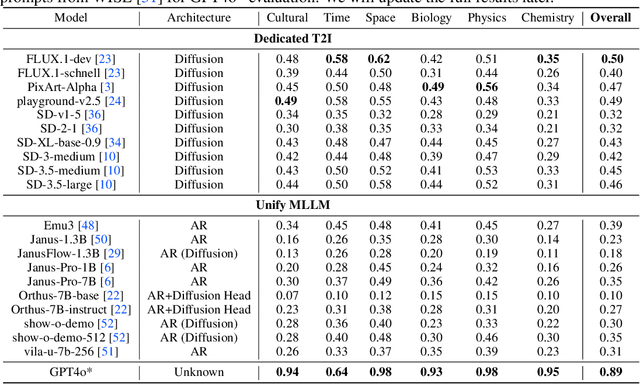
The recent breakthroughs in OpenAI's GPT4o model have demonstrated surprisingly good capabilities in image generation and editing, resulting in significant excitement in the community. This technical report presents the first-look evaluation benchmark (named GPT-ImgEval), quantitatively and qualitatively diagnosing GPT-4o's performance across three critical dimensions: (1) generation quality, (2) editing proficiency, and (3) world knowledge-informed semantic synthesis. Across all three tasks, GPT-4o demonstrates strong performance, significantly surpassing existing methods in both image generation control and output quality, while also showcasing exceptional knowledge reasoning capabilities. Furthermore, based on the GPT-4o's generated data, we propose a classification-model-based approach to investigate the underlying architecture of GPT-4o, where our empirical results suggest the model consists of an auto-regressive (AR) combined with a diffusion-based head for image decoding, rather than the VAR-like architectures. We also provide a complete speculation on GPT-4o's overall architecture. In addition, we conduct a series of analyses to identify and visualize GPT-4o's specific limitations and the synthetic artifacts commonly observed in its image generation. We also present a comparative study of multi-round image editing between GPT-4o and Gemini 2.0 Flash, and discuss the safety implications of GPT-4o's outputs, particularly their detectability by existing image forensic models. We hope that our work can offer valuable insight and provide a reliable benchmark to guide future research, foster reproducibility, and accelerate innovation in the field of image generation and beyond. The codes and datasets used for evaluating GPT-4o can be found at https://github.com/PicoTrex/GPT-ImgEval.
Scene4U: Hierarchical Layered 3D Scene Reconstruction from Single Panoramic Image for Your Immerse Exploration
Apr 01, 2025The reconstruction of immersive and realistic 3D scenes holds significant practical importance in various fields of computer vision and computer graphics. Typically, immersive and realistic scenes should be free from obstructions by dynamic objects, maintain global texture consistency, and allow for unrestricted exploration. The current mainstream methods for image-driven scene construction involves iteratively refining the initial image using a moving virtual camera to generate the scene. However, previous methods struggle with visual discontinuities due to global texture inconsistencies under varying camera poses, and they frequently exhibit scene voids caused by foreground-background occlusions. To this end, we propose a novel layered 3D scene reconstruction framework from panoramic image, named Scene4U. Specifically, Scene4U integrates an open-vocabulary segmentation model with a large language model to decompose a real panorama into multiple layers. Then, we employs a layered repair module based on diffusion model to restore occluded regions using visual cues and depth information, generating a hierarchical representation of the scene. The multi-layer panorama is then initialized as a 3D Gaussian Splatting representation, followed by layered optimization, which ultimately produces an immersive 3D scene with semantic and structural consistency that supports free exploration. Scene4U outperforms state-of-the-art method, improving by 24.24% in LPIPS and 24.40% in BRISQUE, while also achieving the fastest training speed. Additionally, to demonstrate the robustness of Scene4U and allow users to experience immersive scenes from various landmarks, we build WorldVista3D dataset for 3D scene reconstruction, which contains panoramic images of globally renowned sites. The implementation code and dataset will be released at https://github.com/LongHZ140516/Scene4U .
Spot the Fake: Large Multimodal Model-Based Synthetic Image Detection with Artifact Explanation
Mar 19, 2025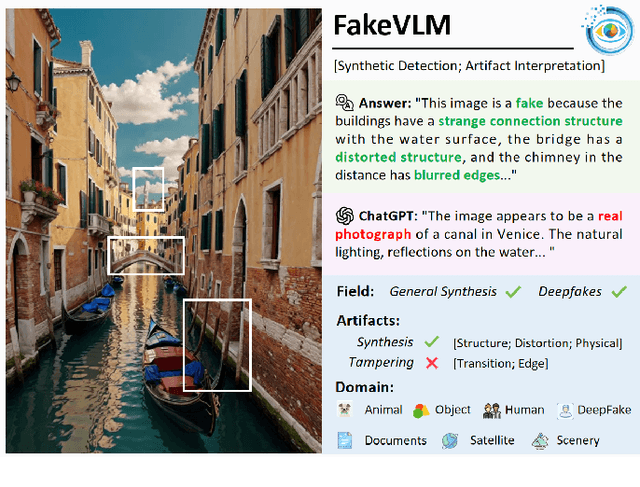
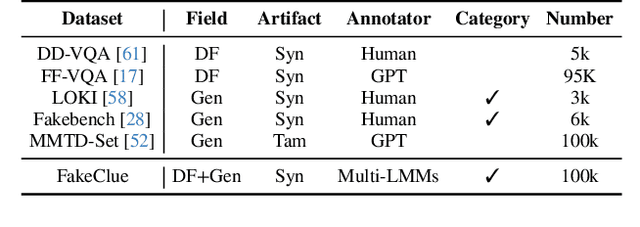

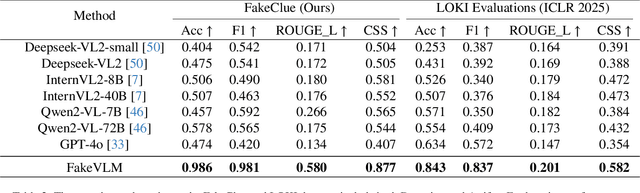
With the rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, synthetic images have become increasingly prevalent in everyday life, posing new challenges for authenticity assessment and detection. Despite the effectiveness of existing methods in evaluating image authenticity and locating forgeries, these approaches often lack human interpretability and do not fully address the growing complexity of synthetic data. To tackle these challenges, we introduce FakeVLM, a specialized large multimodal model designed for both general synthetic image and DeepFake detection tasks. FakeVLM not only excels in distinguishing real from fake images but also provides clear, natural language explanations for image artifacts, enhancing interpretability. Additionally, we present FakeClue, a comprehensive dataset containing over 100,000 images across seven categories, annotated with fine-grained artifact clues in natural language. FakeVLM demonstrates performance comparable to expert models while eliminating the need for additional classifiers, making it a robust solution for synthetic data detection. Extensive evaluations across multiple datasets confirm the superiority of FakeVLM in both authenticity classification and artifact explanation tasks, setting a new benchmark for synthetic image detection. The dataset and code will be released in: https://github.com/opendatalab/FakeVLM.
LEGION: Learning to Ground and Explain for Synthetic Image Detection
Mar 19, 2025The rapid advancements in generative technology have emerged as a double-edged sword. While offering powerful tools that enhance convenience, they also pose significant social concerns. As defenders, current synthetic image detection methods often lack artifact-level textual interpretability and are overly focused on image manipulation detection, and current datasets usually suffer from outdated generators and a lack of fine-grained annotations. In this paper, we introduce SynthScars, a high-quality and diverse dataset consisting of 12,236 fully synthetic images with human-expert annotations. It features 4 distinct image content types, 3 categories of artifacts, and fine-grained annotations covering pixel-level segmentation, detailed textual explanations, and artifact category labels. Furthermore, we propose LEGION (LEarning to Ground and explain for Synthetic Image detectiON), a multimodal large language model (MLLM)-based image forgery analysis framework that integrates artifact detection, segmentation, and explanation. Building upon this capability, we further explore LEGION as a controller, integrating it into image refinement pipelines to guide the generation of higher-quality and more realistic images. Extensive experiments show that LEGION outperforms existing methods across multiple benchmarks, particularly surpassing the second-best traditional expert on SynthScars by 3.31% in mIoU and 7.75% in F1 score. Moreover, the refined images generated under its guidance exhibit stronger alignment with human preferences. The code, model, and dataset will be released.
Where am I? Cross-View Geo-localization with Natural Language Descriptions
Dec 22, 2024Cross-view geo-localization identifies the locations of street-view images by matching them with geo-tagged satellite images or OSM. However, most studies focus on image-to-image retrieval, with fewer addressing text-guided retrieval, a task vital for applications like pedestrian navigation and emergency response. In this work, we introduce a novel task for cross-view geo-localization with natural language descriptions, which aims to retrieve corresponding satellite images or OSM database based on scene text. To support this task, we construct the CVG-Text dataset by collecting cross-view data from multiple cities and employing a scene text generation approach that leverages the annotation capabilities of Large Multimodal Models to produce high-quality scene text descriptions with localization details.Additionally, we propose a novel text-based retrieval localization method, CrossText2Loc, which improves recall by 10% and demonstrates excellent long-text retrieval capabilities. In terms of explainability, it not only provides similarity scores but also offers retrieval reasons. More information can be found at https://yejy53.github.io/CVG-Text/.