 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniAID: Decoupling Semantic and Artifacts for Universal AI-Generated Image Detection in the Wild
Nov 11, 2025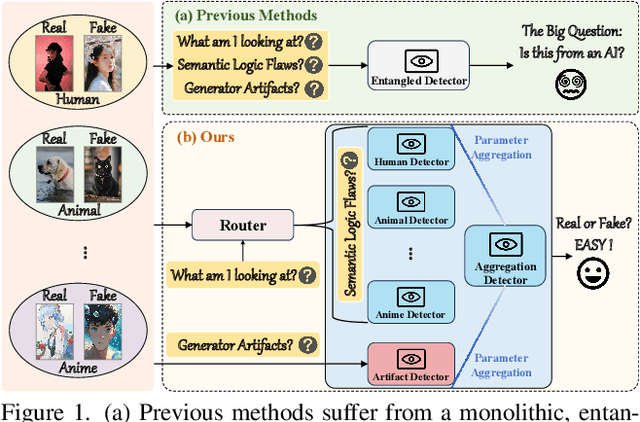
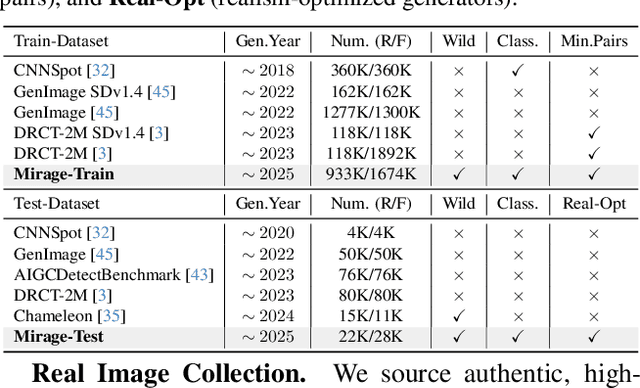
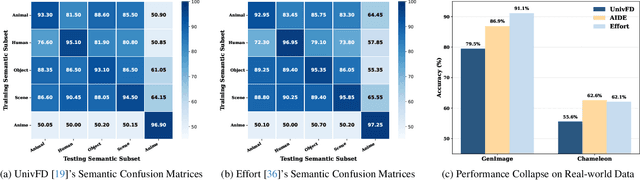
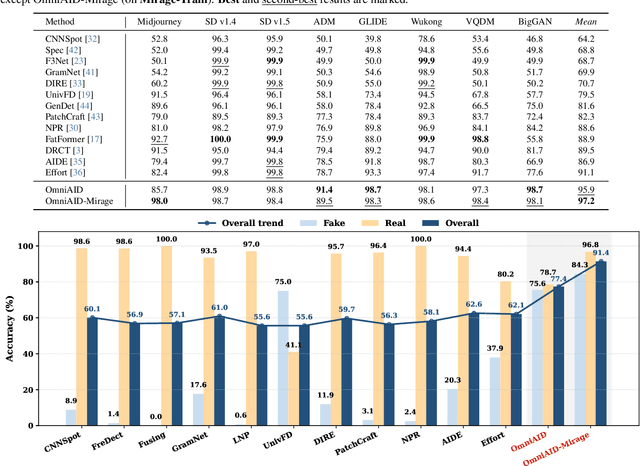
A truly universal AI-Generated Image (AIGI) detector must simultaneously generalize across diverse generative models and varied semantic content. Current state-of-the-art methods learn a single, entangled forgery representation--conflating content-dependent flaws with content-agnostic artifacts--and are further constrained by outdated benchmarks. To overcome these limitations, we propose OmniAID, a novel framework centered on a decoupled Mixture-of-Experts (MoE) architecture. The core of our method is a hybrid expert system engineered to decouple: (1) semantic flaws across distinct content domains, and (2) these content-dependent flaws from content-agnostic universal artifacts. This system employs a set of Routable Specialized Semantic Experts, each for a distinct domain (e.g., human, animal), complemented by a Fixed Universal Artifact Expert. This architecture is trained using a bespoke two-stage strategy: we first train the experts independently with domain-specific hard-sampling to ensure specialization, and subsequently train a lightweight gating network for effective input routing. By explicitly decoupling "what is generated" (content-specific flaws) from "how it is generated" (universal artifacts), OmniAID achieves robust generalization. To address outdated benchmarks and validate real-world applicability, we introduce Mirage, a new large-scale, contemporary dataset. Extensive experiments, using both traditional benchmarks and our Mirage dataset, demonstrate our model surpasses existing monolithic detectors, establishing a new, robust standard for AIGI authentication against modern, in-the-wild threats.
OmniLayout: Enabling Coarse-to-Fine Learning with LLMs for Universal Document Layout Generation
Oct 30, 2025Document AI has advanced rapidly and is attracting increasing attention. Yet, while most efforts have focused on document layout analysis (DLA), its generative counterpart, document layout generation, remains underexplored. A major obstacle lies in the scarcity of diverse layouts: academic papers with Manhattan-style structures dominate existing studies, while open-world genres such as newspapers and magazines remain severely underrepresented. To address this gap, we curate OmniLayout-1M, the first million-scale dataset of diverse document layouts, covering six common document types and comprising contemporary layouts collected from multiple sources. Moreover, since existing methods struggle in complex domains and often fail to arrange long sequences coherently, we introduce OmniLayout-LLM, a 0.5B model with designed two-stage Coarse-to-Fine learning paradigm: 1) learning universal layout principles from OmniLayout-1M with coarse category definitions, and 2) transferring the knowledge to a specific domain with fine-grained annotations. Extensive experiments demonstrate that our approach achieves strong performance on multiple domains in M$^{6}$Doc dataset, substantially surpassing both existing layout generation experts and several latest general-purpose LLMs. Our code, models, and dataset will be publicly released.
LEGION: Learning to Ground and Explain for Synthetic Image Detection
Mar 19, 2025The rapid advancements in generative technology have emerged as a double-edged sword. While offering powerful tools that enhance convenience, they also pose significant social concerns. As defenders, current synthetic image detection methods often lack artifact-level textual interpretability and are overly focused on image manipulation detection, and current datasets usually suffer from outdated generators and a lack of fine-grained annotations. In this paper, we introduce SynthScars, a high-quality and diverse dataset consisting of 12,236 fully synthetic images with human-expert annotations. It features 4 distinct image content types, 3 categories of artifacts, and fine-grained annotations covering pixel-level segmentation, detailed textual explanations, and artifact category labels. Furthermore, we propose LEGION (LEarning to Ground and explain for Synthetic Image detectiON), a multimodal large language model (MLLM)-based image forgery analysis framework that integrates artifact detection, segmentation, and explanation. Building upon this capability, we further explore LEGION as a controller, integrating it into image refinement pipelines to guide the generation of higher-quality and more realistic images. Extensive experiments show that LEGION outperforms existing methods across multiple benchmarks, particularly surpassing the second-best traditional expert on SynthScars by 3.31% in mIoU and 7.75% in F1 score. Moreover, the refined images generated under its guidance exhibit stronger alignment with human preferences. The code, model, and dataset will be released.
Spot the Fake: Large Multimodal Model-Based Synthetic Image Detection with Artifact Explanation
Mar 19, 2025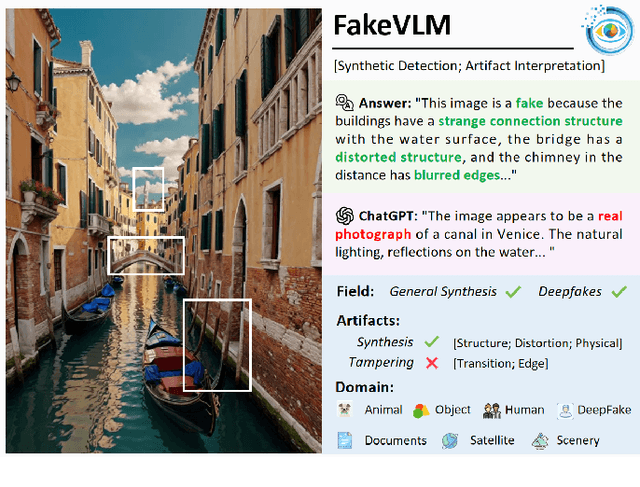
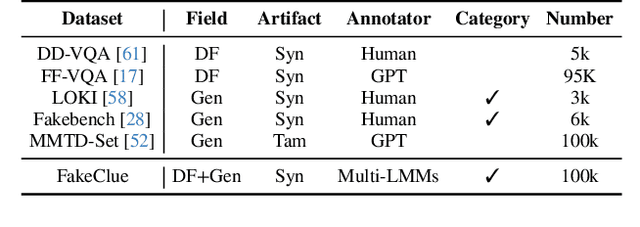

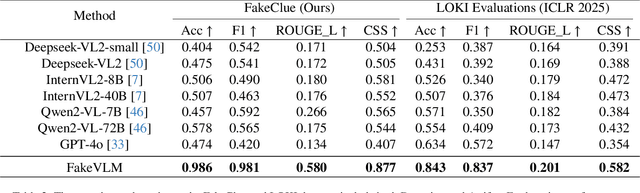
With the rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, synthetic images have become increasingly prevalent in everyday life, posing new challenges for authenticity assessment and detection. Despite the effectiveness of existing methods in evaluating image authenticity and locating forgeries, these approaches often lack human interpretability and do not fully address the growing complexity of synthetic data. To tackle these challenges, we introduce FakeVLM, a specialized large multimodal model designed for both general synthetic image and DeepFake detection tasks. FakeVLM not only excels in distinguishing real from fake images but also provides clear, natural language explanations for image artifacts, enhancing interpretability. Additionally, we present FakeClue, a comprehensive dataset containing over 100,000 images across seven categories, annotated with fine-grained artifact clues in natural language. FakeVLM demonstrates performance comparable to expert models while eliminating the need for additional classifiers, making it a robust solution for synthetic data detection. Extensive evaluations across multiple datasets confirm the superiority of FakeVLM in both authenticity classification and artifact explanation tasks, setting a new benchmark for synthetic image detection. The dataset and code will be released in: https://github.com/opendatalab/FakeVLM.
DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Global-to-Local Adaptive Perception
Oct 16, 2024



Document Layout Analysis is crucial for real-world document understanding systems, but it encounters a challenging trade-off between speed and accuracy: multimodal methods leveraging both text and visual features achieve higher accuracy but suffer from significant latency, whereas unimodal methods relying solely on visual features offer faster processing speeds at the expense of accuracy. To address this dilemma, we introduce DocLayout-YOLO, a novel approach that enhances accuracy while maintaining speed advantages through document-specific optimizations in both pre-training and model design. For robust document pre-training, we introduce the Mesh-candidate BestFit algorithm, which frames document synthesis as a two-dimensional bin packing problem, generating the large-scale, diverse DocSynth-300K dataset. Pre-training on the resulting DocSynth-300K dataset significantly improves fine-tuning performance across various document types. In terms of model optimization, we propose a Global-to-Local Controllable Receptive Module that is capable of better handling multi-scale variations of document elements. Furthermore, to validate performance across different document types, we introduce a complex and challenging benchmark named DocStructBench. Extensive experiments on downstream datasets demonstrate that DocLayout-YOLO excels in both speed and accuracy. Code, data, and models are available at https://github.com/opendatalab/DocLayout-YOLO.
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
Oct 13, 2024
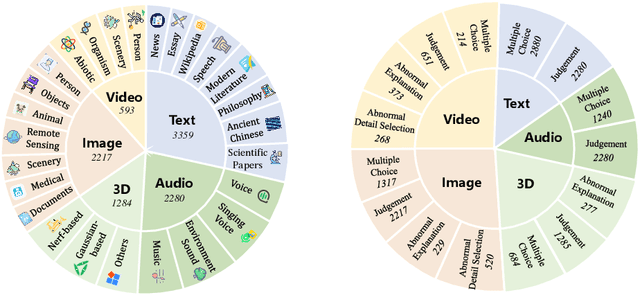

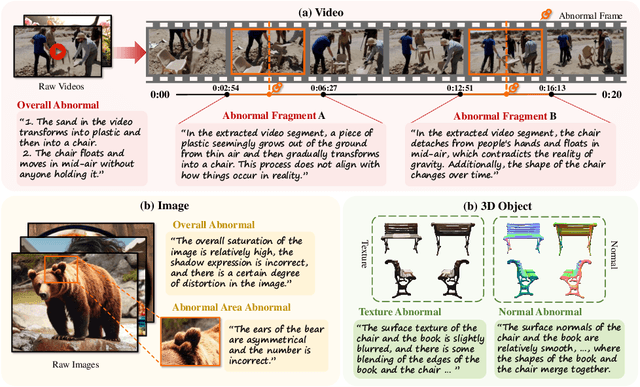
With the rapid development of AI-generated content, the future internet may be inundated with synthetic data, making the discrimination of authentic and credible multimodal data increasingly challenging. Synthetic data detection has thus garnered widespread attention, and the performance of large multimodal models (LMMs) in this task has attracted significant interest. LMMs can provide natural language explanations for their authenticity judgments, enhancing the explainability of synthetic content detection. Simultaneously, the task of distinguishing between real and synthetic data effectively tests the perception, knowledge, and reasoning capabilities of LMMs. In response, we introduce LOKI, a novel benchmark designed to evaluate the ability of LMMs to detect synthetic data across multiple modalities. LOKI encompasses video, image, 3D, text, and audio modalities, comprising 18K carefully curated questions across 26 subcategories with clear difficulty levels. The benchmark includes coarse-grained judgment and multiple-choice questions, as well as fine-grained anomaly selection and explanation tasks, allowing for a comprehensive analysis of LMMs. We evaluated 22 open-source LMMs and 6 closed-source models on LOKI, highlighting their potential as synthetic data detectors and also revealing some limitations in the development of LMM capabilities. More information about LOKI can be found at https://opendatalab.github.io/LOKI/