 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNet-Based Fusion and Exponential Moving Average Adaptation for Noise-Robust Speaker Recognition
Apr 28, 2026The joint training of speech enhancement and speaker embedding networks for speaker recognition is widely adopted under noisy acoustic environments. While effective, this paradigm often fails to leverage the generalization and robustness benefits inherent in large-scale speech enhancement pre-training. Moreover, maintaining the speaker information in the denoised speech is not an explicit objective of the speech enhancement process. To address these limitations, we proposed a scalable \textbf{U}Net-based \textbf{F}usion framework (UF-EMA) that considers the noisy and enhanced speech as a multi-channel input, thereby enabling the speaker encoder to exploit speaker information effectively. In addition, an \textbf{E}xponential \textbf{M}oving \textbf{A}verage strategy is applied to a speaker encoder pre-trained on clean speech to mitigate overfitting and facilitate a smooth transition from clean to noisy conditions. Experimental results on multiple noise-contaminated test sets showcase the superiority of the proposed approach.
Mixture-of-Depths Attention
Mar 16, 2026Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
Mar 12, 2026Autoregressive (AR) video generative models rely on video tokenizers that compress pixels into discrete token sequences. The length of these token sequences is crucial for balancing reconstruction quality against downstream generation computational cost. Traditional video tokenizers apply a uniform token assignment across temporal blocks of different videos, often wasting tokens on simple, static, or repetitive segments while underserving dynamic or complex ones. To address this inefficiency, we introduce $\textbf{EVATok}$, a framework to produce $\textbf{E}$fficient $\textbf{V}$ideo $\textbf{A}$daptive $\textbf{Tok}$enizers. Our framework estimates optimal token assignments for each video to achieve the best quality-cost trade-off, develops lightweight routers for fast prediction of these optimal assignments, and trains adaptive tokenizers that encode videos based on the assignments predicted by routers. We demonstrate that EVATok delivers substantial improvements in efficiency and overall quality for video reconstruction and downstream AR generation. Enhanced by our advanced training recipe that integrates video semantic encoders, EVATok achieves superior reconstruction and state-of-the-art class-to-video generation on UCF-101, with at least 24.4% savings in average token usage compared to the prior state-of-the-art LARP and our fixed-length baseline.
Mind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
Feb 02, 2026While text-to-image generation has achieved unprecedented fidelity, the vast majority of existing models function fundamentally as static text-to-pixel decoders. Consequently, they often fail to grasp implicit user intentions. Although emerging unified understanding-generation models have improved intent comprehension, they still struggle to accomplish tasks involving complex knowledge reasoning within a single model. Moreover, constrained by static internal priors, these models remain unable to adapt to the evolving dynamics of the real world. To bridge these gaps, we introduce Mind-Brush, a unified agentic framework that transforms generation into a dynamic, knowledge-driven workflow. Simulating a human-like 'think-research-create' paradigm, Mind-Brush actively retrieves multimodal evidence to ground out-of-distribution concepts and employs reasoning tools to resolve implicit visual constraints. To rigorously evaluate these capabilities, we propose Mind-Bench, a comprehensive benchmark comprising 500 distinct samples spanning real-time news, emerging concepts, and domains such as mathematical and Geo-Reasoning. Extensive experiments demonstrate that Mind-Brush significantly enhances the capabilities of unified models, realizing a zero-to-one capability leap for the Qwen-Image baseline on Mind-Bench, while achieving superior results on established benchmarks like WISE and RISE.
ThinkGen: Generalized Thinking for Visual Generation
Dec 29, 2025Recent progress in Multimodal Large Language Models (MLLMs) demonstrates that Chain-of-Thought (CoT) reasoning enables systematic solutions to complex understanding tasks. However, its extension to generation tasks remains nascent and limited by scenario-specific mechanisms that hinder generalization and adaptation. In this work, we present ThinkGen, the first think-driven visual generation framework that explicitly leverages MLLM's CoT reasoning in various generation scenarios. ThinkGen employs a decoupled architecture comprising a pretrained MLLM and a Diffusion Transformer (DiT), wherein the MLLM generates tailored instructions based on user intent, and DiT produces high-quality images guided by these instructions. We further propose a separable GRPO-based training paradigm (SepGRPO), alternating reinforcement learning between the MLLM and DiT modules. This flexible design enables joint training across diverse datasets, facilitating effective CoT reasoning for a wide range of generative scenarios. Extensive experiments demonstrate that ThinkGen achieves robust, state-of-the-art performance across multiple generation benchmarks. Code is available: https://github.com/jiaosiyuu/ThinkGen
CodeDance: A Dynamic Tool-integrated MLLM for Executable Visual Reasoning
Dec 19, 2025Recent releases such as o3 highlight human-like "thinking with images" reasoning that combines structured tool use with stepwise verification, yet most open-source approaches still rely on text-only chains, rigid visual schemas, or single-step pipelines, limiting flexibility, interpretability, and transferability on complex tasks. We introduce CodeDance, which explores executable code as a general solver for visual reasoning. Unlike fixed-schema calls (e.g., only predicting bounding-box coordinates), CodeDance defines, composes, and executes code to orchestrate multiple tools, compute intermediate results, and render visual artifacts (e.g., boxes, lines, plots) that support transparent, self-checkable reasoning. To guide this process, we introduce a reward for balanced and adaptive tool-call, which balances exploration with efficiency and mitigates tool overuse. Interestingly, beyond the expected capabilities taught by atomic supervision, we empirically observe novel emergent behaviors during RL training: CodeDance demonstrates novel tool invocations, unseen compositions, and cross-task transfer. These behaviors arise without task-specific fine-tuning, suggesting a general and scalable mechanism of executable visual reasoning. Extensive experiments across reasoning benchmarks (e.g., visual search, math, chart QA) show that CodeDance not only consistently outperforms schema-driven and text-only baselines, but also surpasses advanced closed models such as GPT-4o and larger open-source models.
SuperCLIP: CLIP with Simple Classification Supervision
Dec 16, 2025

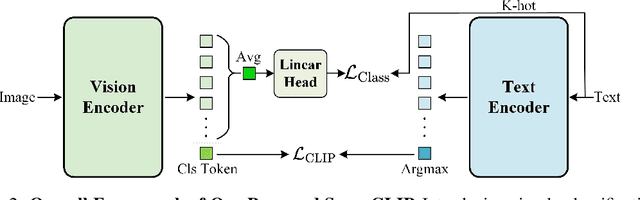
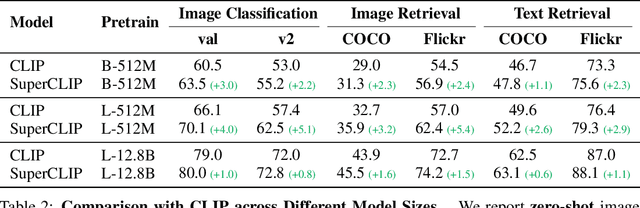
Contrastive Language-Image Pretraining (CLIP) achieves strong generalization in vision-language tasks by aligning images and texts in a shared embedding space. However, recent findings show that CLIP-like models still underutilize fine-grained semantic signals in text, and this issue becomes even more pronounced when dealing with long and detailed captions. This stems from CLIP's training objective, which optimizes only global image-text similarity and overlooks token-level supervision - limiting its ability to achieve fine-grained visual-text alignment. To address this, we propose SuperCLIP, a simple yet effective framework that augments contrastive learning with classification-based supervision. By adding only a lightweight linear layer to the vision encoder, SuperCLIP leverages token-level cues to enhance visual-textual alignment - with just a 0.077% increase in total FLOPs, and no need for additional annotated data. Experiments show that SuperCLIP consistently improves zero-shot classification, image-text retrieval, and purely visual tasks. These gains hold regardless of whether the model is trained on original web data or rich re-captioned data, demonstrating SuperCLIP's ability to recover textual supervision in both cases. Furthermore, SuperCLIP alleviates CLIP's small-batch performance drop through classification-based supervision that avoids reliance on large batch sizes. Code and models will be made open source.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
UrbanFeel: A Comprehensive Benchmark for Temporal and Perceptual Understanding of City Scenes through Human Perspective
Sep 26, 2025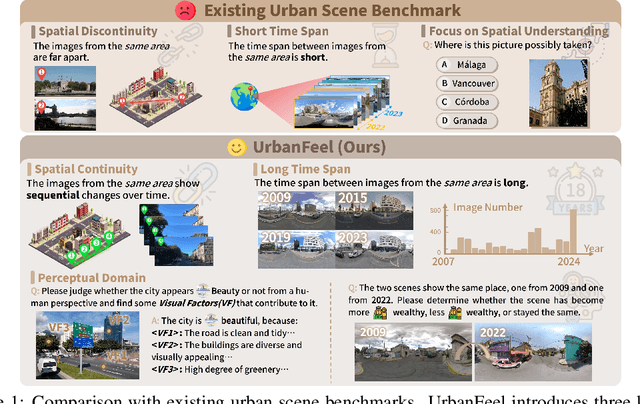
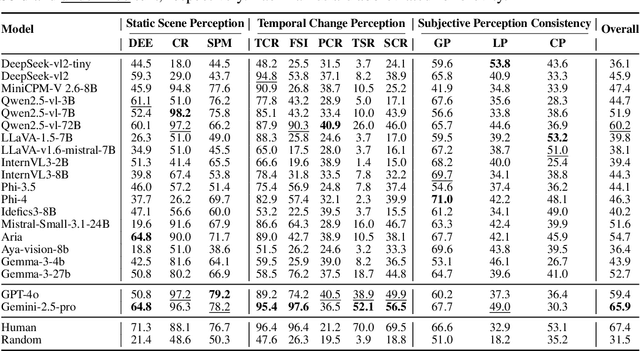

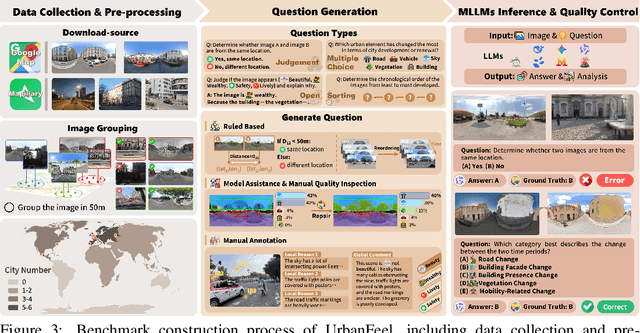
Urban development impacts over half of the global population, making human-centered understanding of its structural and perceptual changes essential for sustainable development. While Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various domains, existing benchmarks that explore their performance in urban environments remain limited, lacking systematic exploration of temporal evolution and subjective perception of urban environment that aligns with human perception. To address these limitations, we propose UrbanFeel, a comprehensive benchmark designed to evaluate the performance of MLLMs in urban development understanding and subjective environmental perception. UrbanFeel comprises 14.3K carefully constructed visual questions spanning three cognitively progressive dimensions: Static Scene Perception, Temporal Change Understanding, and Subjective Environmental Perception. We collect multi-temporal single-view and panoramic street-view images from 11 representative cities worldwide, and generate high-quality question-answer pairs through a hybrid pipeline of spatial clustering, rule-based generation, model-assisted prompting, and manual annotation. Through extensive evaluation of 20 state-of-the-art MLLMs, we observe that Gemini-2.5 Pro achieves the best overall performance, with its accuracy approaching human expert levels and narrowing the average gap to just 1.5\%. Most models perform well on tasks grounded in scene understanding. In particular, some models even surpass human annotators in pixel-level change detection. However, performance drops notably in tasks requiring temporal reasoning over urban development. Additionally, in the subjective perception dimension, several models reach human-level or even higher consistency in evaluating dimension such as beautiful and safety.
Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
Aug 13, 2025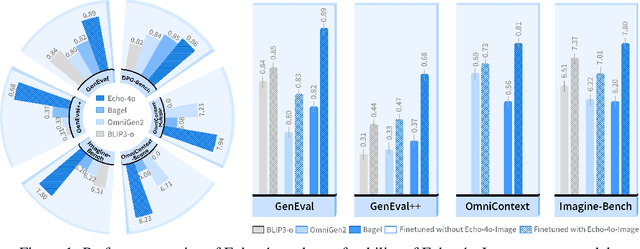
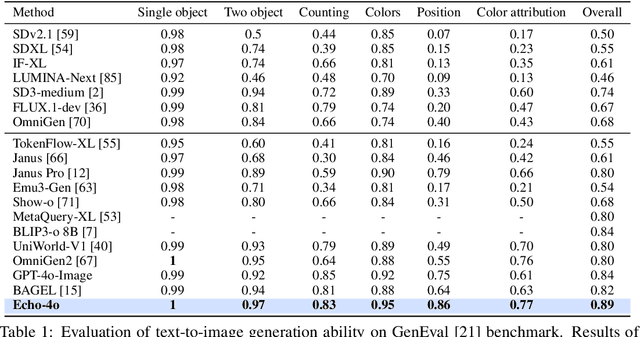
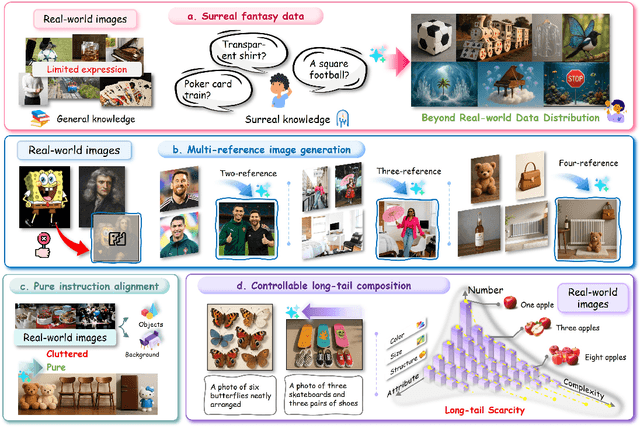
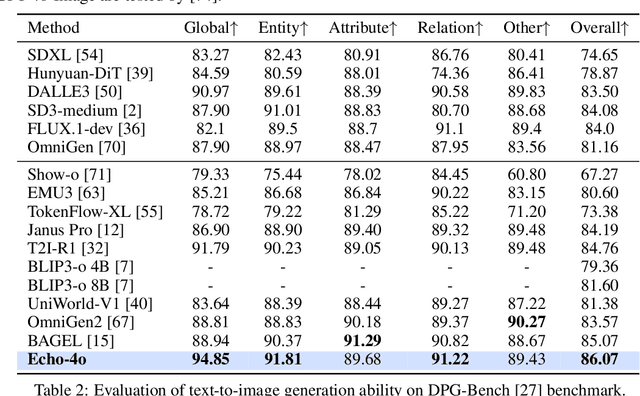
Recently, GPT-4o has garnered significant attention for its strong performance in image generation, yet open-source models still lag behind. Several studies have explored distilling image data from GPT-4o to enhance open-source models, achieving notable progress. However, a key question remains: given that real-world image datasets already constitute a natural source of high-quality data, why should we use GPT-4o-generated synthetic data? In this work, we identify two key advantages of synthetic images. First, they can complement rare scenarios in real-world datasets, such as surreal fantasy or multi-reference image generation, which frequently occur in user queries. Second, they provide clean and controllable supervision. Real-world data often contains complex background noise and inherent misalignment between text descriptions and image content, whereas synthetic images offer pure backgrounds and long-tailed supervision signals, facilitating more accurate text-to-image alignment. Building on these insights, we introduce Echo-4o-Image, a 180K-scale synthetic dataset generated by GPT-4o, harnessing the power of synthetic image data to address blind spots in real-world coverage. Using this dataset, we fine-tune the unified multimodal generation baseline Bagel to obtain Echo-4o. In addition, we propose two new evaluation benchmarks for a more accurate and challenging assessment of image generation capabilities: GenEval++, which increases instruction complexity to mitigate score saturation, and Imagine-Bench, which focuses on evaluating both the understanding and generation of imaginative content. Echo-4o demonstrates strong performance across standard benchmarks. Moreover, applying Echo-4o-Image to other foundation models (e.g., OmniGen2, BLIP3-o) yields consistent performance gains across multiple metrics, highlighting the datasets strong transferability.