 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially-Weighted CLIP for Street-View Geo-localization
Apr 06, 2026This paper proposes Spatially-Weighted CLIP (SW-CLIP), a novel framework for street-view geo-localization that explicitly incorporates spatial autocorrelation into vision-language contrastive learning. Unlike conventional CLIP-based methods that treat all non-matching samples as equally negative, SW-CLIP leverages Tobler's First Law of Geography to model geographic relationships through distance-aware soft supervision. Specifically, we introduce a location-as-text representation to encode geographic positions and replace one-hot InfoNCE targets with spatially weighted soft labels derived from geodesic distance. Additionally, a neighborhood-consistency regularization is employed to preserve local spatial structure in the embedding space. Experiments on a multi-city dataset demonstrate that SW-CLIP significantly improves geo-localization accuracy, reduces long-tail errors, and enhances spatial coherence compared to standard CLIP. The results highlight the importance of shifting from semantic alignment to geographic alignment for robust geo-localization and provide a general paradigm for integrating spatial principles into multimodal representation learning.
A Large-Scale Remote Sensing Dataset and VLM-based Algorithm for Fine-Grained Road Hierarchy Classification
Mar 22, 2026In this work, we present SYSU-HiRoads, a large-scale hierarchical road dataset, and RoadReasoner, a vision-language-geometry framework for automatic multi-grade road mapping from remote sensing imagery. SYSU-HiRoads is built from GF-2 imagery covering 3631 km2 in Henan Province, China, and contains 1079 image tiles at 0.8 m spatial resolution. Each tile is annotated with dense road masks, vectorized centerlines, and three-level hierarchy labels, enabling the joint training and evaluation of segmentation, topology reconstruction, and hierarchy classification. Building on this dataset, RoadReasoner is designed to generate robust road surface masks, topology-preserving road networks, and semantically coherent hierarchy assignments. We strengthen road feature representation and network connectivity by explicitly enhancing frequency-sensitive cues and multi-scale context. Moreover, we perform hierarchy inference at the skeleton-segment level with geometric descriptors and geometry-aware textual prompts, queried by vision-language models to obtain linguistically interpretable grade decisions. Experiments on SYSU-HiRoads and the CHN6-CUG dataset show that RoadReasoner surpasses state-of-the-art road extraction baselines and produces accurate and semantically consistent road hierarchy maps with 72.6% OA, 64.2% F1 score, and 60.6% SegAcc. The dataset and code will be publicly released to support automated transport infrastructure mapping, road inventory updating, and broader infrastructure management applications.
Time2General: Learning Spatiotemporal Invariant Representations for Domain-Generalization Video Semantic Segmentation
Feb 10, 2026Domain Generalized Video Semantic Segmentation (DGVSS) is trained on a single labeled driving domain and is directly deployed on unseen domains without target labels and test-time adaptation while maintaining temporally consistent predictions over video streams. In practice, both domain shift and temporal-sampling shift break correspondence-based propagation and fixed-stride temporal aggregation, causing severe frame-to-frame flicker even in label-stable regions. We propose Time2General, a DGVSS framework built on Stability Queries. Time2General introduces a Spatio-Temporal Memory Decoder that aggregates multi-frame context into a clip-level spatio-temporal memory and decodes temporally consistent per-frame masks without explicit correspondence propagation. To further suppress flicker and improve robustness to varying sampling rates, the Masked Temporal Consistency Loss is proposed to regularize temporal prediction discrepancies across different strides, and randomize training strides to expose the model to diverse temporal gaps. Extensive experiments on multiple driving benchmarks show that Time2General achieves a substantial improvement in cross-domain accuracy and temporal stability over prior DGSS and VSS baselines while running at up to 18 FPS. Code will be released after the review process.
PreResQ-R1: Towards Fine-Grained Rank-and-Score Reinforcement Learning for Visual Quality Assessment via Preference-Response Disentangled Policy Optimization
Nov 07, 2025Visual Quality Assessment (QA) seeks to predict human perceptual judgments of visual fidelity. While recent multimodal large language models (MLLMs) show promise in reasoning about image and video quality, existing approaches mainly rely on supervised fine-tuning or rank-only objectives, resulting in shallow reasoning, poor score calibration, and limited cross-domain generalization. We propose PreResQ-R1, a Preference-Response Disentangled Reinforcement Learning framework that unifies absolute score regression and relative ranking consistency within a single reasoning-driven optimization scheme. Unlike prior QA methods, PreResQ-R1 introduces a dual-branch reward formulation that separately models intra-sample response coherence and inter-sample preference alignment, optimized via Group Relative Policy Optimization (GRPO). This design encourages fine-grained, stable, and interpretable chain-of-thought reasoning about perceptual quality. To extend beyond static imagery, we further design a global-temporal and local-spatial data flow strategy for Video Quality Assessment. Remarkably, with reinforcement fine-tuning on only 6K images and 28K videos, PreResQ-R1 achieves state-of-the-art results across 10 IQA and 5 VQA benchmarks under both SRCC and PLCC metrics, surpassing by margins of 5.30% and textbf2.15% in IQA task, respectively. Beyond quantitative gains, it produces human-aligned reasoning traces that reveal the perceptual cues underlying quality judgments. Code and model are available.
Unveiling Deep Semantic Uncertainty Perception for Language-Anchored Multi-modal Vision-Brain Alignment
Nov 06, 2025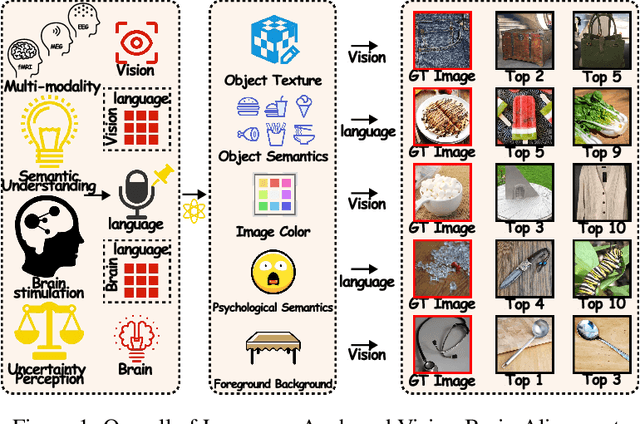



Unveiling visual semantics from neural signals such as EEG, MEG, and fMRI remains a fundamental challenge due to subject variability and the entangled nature of visual features. Existing approaches primarily align neural activity directly with visual embeddings, but visual-only representations often fail to capture latent semantic dimensions, limiting interpretability and deep robustness. To address these limitations, we propose Bratrix, the first end-to-end framework to achieve multimodal Language-Anchored Vision-Brain alignment. Bratrix decouples visual stimuli into hierarchical visual and linguistic semantic components, and projects both visual and brain representations into a shared latent space, enabling the formation of aligned visual-language and brain-language embeddings. To emulate human-like perceptual reliability and handle noisy neural signals, Bratrix incorporates a novel uncertainty perception module that applies uncertainty-aware weighting during alignment. By leveraging learnable language-anchored semantic matrices to enhance cross-modal correlations and employing a two-stage training strategy of single-modality pretraining followed by multimodal fine-tuning, Bratrix-M improves alignment precision. Extensive experiments on EEG, MEG, and fMRI benchmarks demonstrate that Bratrix improves retrieval, reconstruction, and captioning performance compared to state-of-the-art methods, specifically surpassing 14.3% in 200-way EEG retrieval task. Code and model are available.
SGS-3D: High-Fidelity 3D Instance Segmentation via Reliable Semantic Mask Splitting and Growing
Sep 05, 2025Accurate 3D instance segmentation is crucial for high-quality scene understanding in the 3D vision domain. However, 3D instance segmentation based on 2D-to-3D lifting approaches struggle to produce precise instance-level segmentation, due to accumulated errors introduced during the lifting process from ambiguous semantic guidance and insufficient depth constraints. To tackle these challenges, we propose splitting and growing reliable semantic mask for high-fidelity 3D instance segmentation (SGS-3D), a novel "split-then-grow" framework that first purifies and splits ambiguous lifted masks using geometric primitives, and then grows them into complete instances within the scene. Unlike existing approaches that directly rely on raw lifted masks and sacrifice segmentation accuracy, SGS-3D serves as a training-free refinement method that jointly fuses semantic and geometric information, enabling effective cooperation between the two levels of representation. Specifically, for semantic guidance, we introduce a mask filtering strategy that leverages the co-occurrence of 3D geometry primitives to identify and remove ambiguous masks, thereby ensuring more reliable semantic consistency with the 3D object instances. For the geometric refinement, we construct fine-grained object instances by exploiting both spatial continuity and high-level features, particularly in the case of semantic ambiguity between distinct objects. Experimental results on ScanNet200, ScanNet++, and KITTI-360 demonstrate that SGS-3D substantially improves segmentation accuracy and robustness against inaccurate masks from pre-trained models, yielding high-fidelity object instances while maintaining strong generalization across diverse indoor and outdoor environments. Code is available in the supplementary materials.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
Leveraging Depth and Language for Open-Vocabulary Domain-Generalized Semantic Segmentation
Jun 11, 2025Open-Vocabulary semantic segmentation (OVSS) and domain generalization in semantic segmentation (DGSS) highlight a subtle complementarity that motivates Open-Vocabulary Domain-Generalized Semantic Segmentation (OV-DGSS). OV-DGSS aims to generate pixel-level masks for unseen categories while maintaining robustness across unseen domains, a critical capability for real-world scenarios such as autonomous driving in adverse conditions. We introduce Vireo, a novel single-stage framework for OV-DGSS that unifies the strengths of OVSS and DGSS for the first time. Vireo builds upon the frozen Visual Foundation Models (VFMs) and incorporates scene geometry via Depth VFMs to extract domain-invariant structural features. To bridge the gap between visual and textual modalities under domain shift, we propose three key components: (1) GeoText Prompts, which align geometric features with language cues and progressively refine VFM encoder representations; (2) Coarse Mask Prior Embedding (CMPE) for enhancing gradient flow for faster convergence and stronger textual influence; and (3) the Domain-Open-Vocabulary Vector Embedding Head (DOV-VEH), which fuses refined structural and semantic features for robust prediction. Comprehensive evaluation on these components demonstrates the effectiveness of our designs. Our proposed Vireo achieves the state-of-the-art performance and surpasses existing methods by a large margin in both domain generalization and open-vocabulary recognition, offering a unified and scalable solution for robust visual understanding in diverse and dynamic environments. Code is available at https://github.com/anonymouse-9c53tp182bvz/Vireo.
Stronger, Steadier & Superior: Geometric Consistency in Depth VFM Forges Domain Generalized Semantic Segmentation
Apr 17, 2025



Vision Foundation Models (VFMs) have delivered remarkable performance in Domain Generalized Semantic Segmentation (DGSS). However, recent methods often overlook the fact that visual cues are susceptible, whereas the underlying geometry remains stable, rendering depth information more robust. In this paper, we investigate the potential of integrating depth information with features from VFMs, to improve the geometric consistency within an image and boost the generalization performance of VFMs. We propose a novel fine-tuning DGSS framework, named DepthForge, which integrates the visual cues from frozen DINOv2 or EVA02 and depth cues from frozen Depth Anything V2. In each layer of the VFMs, we incorporate depth-aware learnable tokens to continuously decouple domain-invariant visual and spatial information, thereby enhancing depth awareness and attention of the VFMs. Finally, we develop a depth refinement decoder and integrate it into the model architecture to adaptively refine multi-layer VFM features and depth-aware learnable tokens. Extensive experiments are conducted based on various DGSS settings and five different datsets as unseen target domains. The qualitative and quantitative results demonstrate that our method significantly outperforms alternative approaches with stronger performance, steadier visual-spatial attention, and superior generalization ability. In particular, DepthForge exhibits outstanding performance under extreme conditions (e.g., night and snow). Code is available at https://github.com/anonymouse-xzrptkvyqc/DepthForge.
Scene4U: Hierarchical Layered 3D Scene Reconstruction from Single Panoramic Image for Your Immerse Exploration
Apr 01, 2025The reconstruction of immersive and realistic 3D scenes holds significant practical importance in various fields of computer vision and computer graphics. Typically, immersive and realistic scenes should be free from obstructions by dynamic objects, maintain global texture consistency, and allow for unrestricted exploration. The current mainstream methods for image-driven scene construction involves iteratively refining the initial image using a moving virtual camera to generate the scene. However, previous methods struggle with visual discontinuities due to global texture inconsistencies under varying camera poses, and they frequently exhibit scene voids caused by foreground-background occlusions. To this end, we propose a novel layered 3D scene reconstruction framework from panoramic image, named Scene4U. Specifically, Scene4U integrates an open-vocabulary segmentation model with a large language model to decompose a real panorama into multiple layers. Then, we employs a layered repair module based on diffusion model to restore occluded regions using visual cues and depth information, generating a hierarchical representation of the scene. The multi-layer panorama is then initialized as a 3D Gaussian Splatting representation, followed by layered optimization, which ultimately produces an immersive 3D scene with semantic and structural consistency that supports free exploration. Scene4U outperforms state-of-the-art method, improving by 24.24% in LPIPS and 24.40% in BRISQUE, while also achieving the fastest training speed. Additionally, to demonstrate the robustness of Scene4U and allow users to experience immersive scenes from various landmarks, we build WorldVista3D dataset for 3D scene reconstruction, which contains panoramic images of globally renowned sites. The implementation code and dataset will be released at https://github.com/LongHZ140516/Scene4U .