 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTriGen: Unified Triplet Generation of Aligned Visible-Infrared-Label for Few-Shot RGB-T Semantic Segmentation
May 14, 2026RGB-T semantic segmentation requires strictly aligned VIS-IR-Label triplets; however, such aligned triplet data are often scarce in real-world scenarios. Existing generative augmentation methods usually adopt cascaded generation paradigms, decomposing joint triplet generation into local conditional processes. As a result, consistency among VIS, IR, and Label in spatial structure, semantic content, and cross-modal details cannot be reliably maintained. To address this issue, we propose UniTriGen, a unified triplet generation framework that directly generates spatially aligned, semantically consistent, and modality complementary VIS-IR-Label triplets under the guidance of text prompts. UniTriGen first introduces a unified triplet generation mechanism, where VIS, IR, and Label are jointly encoded into a shared latent space and modeled with a diffusion process to enforce global cross-modal consistency. Lightweight modality-specific residual adapters are further integrated into this mechanism to accommodate modality-specific imaging characteristics and output formats. To mitigate generation bias caused by imbalanced scene and class distributions in limited paired triplets, UniTriGen also employs a scene-balanced and class-aware few-shot sampling strategy, which induces a more balanced sampling distribution and enhances the scene and class diversity of generated triplets. Experiments show that UniTriGen generates high-quality aligned triplets from limited real paired data, thereby achieving consistent performance improvements across various RGB-T semantic segmentation models.
AutoLALA: Automatic Loop Algebraic Locality Analysis for AI and HPC Kernels
Apr 06, 2026Data movement is the primary bottleneck in modern computing systems. For loop-based programs common in high-performance computing (HPC) and AI workloads, including matrix multiplication, tensor contraction, stencil computation, and einsum operations, the cost of moving data through the memory hierarchy often exceeds the cost of arithmetic. This paper presents AutoLALA, an open-source tool that analyzes data locality in affine loop programs. The tool accepts programs written in a small domain-specific language (DSL), lowers them to polyhedral sets and maps, and produces closed-form symbolic formulas for reuse distance and data movement complexity. AutoLALA implements the fully symbolic locality analysis of Zhu et al. together with the data movement distance (DMD) framework of Smith et al. In particular, it computes reuse distance as the image of the access space under the access map, avoiding both stack simulation and Denning's recursive working-set formulation. We describe the DSL syntax and its formal semantics, the polyhedral lowering pipeline that constructs timestamp spaces and access maps via affine transformations, and the sequence of Barvinok counting operations used to derive symbolic reuse-interval and reuse-distance distributions. The system is implemented in Rust as a modular library spanning three crates, with safe bindings to the Barvinok library. We provide both a command-line interface and an interactive web playground with LaTeX rendering of the output formulas. The tool handles arbitrary affine loop nests, covering workloads such as tensor contractions, einsum expressions, stencil computations, and general polyhedral programs.
Sawtooth Wavefront Reordering: Enhanced CuTile FlashAttention on NVIDIA GB10
Jan 26, 2026High-performance attention kernels are essential for Large Language Models. This paper presents analysis of CuTile-based Flash Attention memory behavior and a technique to improve its cache performance. In particular, our analysis on the NVIDIA GB10 (Grace Blackwell) identifies the main cause of L2 cache miss. Leveraging this insight, we introduce a new programming technique called Sawtooth Wavefront Reordering that reduces L2 misses. We validate it in both CUDA and CuTile, observing 50\% or greater reduction in L2 misses and up to 60\% increase in throughput on GB10.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
JoDiffusion: Jointly Diffusing Image with Pixel-Level Annotations for Semantic Segmentation Promotion
Dec 15, 2025Given the inherently costly and time-intensive nature of pixel-level annotation, the generation of synthetic datasets comprising sufficiently diverse synthetic images paired with ground-truth pixel-level annotations has garnered increasing attention recently for training high-performance semantic segmentation models. However, existing methods necessitate to either predict pseudo annotations after image generation or generate images conditioned on manual annotation masks, which incurs image-annotation semantic inconsistency or scalability problem. To migrate both problems with one stone, we present a novel dataset generative diffusion framework for semantic segmentation, termed JoDiffusion. Firstly, given a standard latent diffusion model, JoDiffusion incorporates an independent annotation variational auto-encoder (VAE) network to map annotation masks into the latent space shared by images. Then, the diffusion model is tailored to capture the joint distribution of each image and its annotation mask conditioned on a text prompt. By doing these, JoDiffusion enables simultaneously generating paired images and semantically consistent annotation masks solely conditioned on text prompts, thereby demonstrating superior scalability. Additionally, a mask optimization strategy is developed to mitigate the annotation noise produced during generation. Experiments on Pascal VOC, COCO, and ADE20K datasets show that the annotated dataset generated by JoDiffusion yields substantial performance improvements in semantic segmentation compared to existing methods.
Prompt-Free Conditional Diffusion for Multi-object Image Augmentation
Jul 08, 2025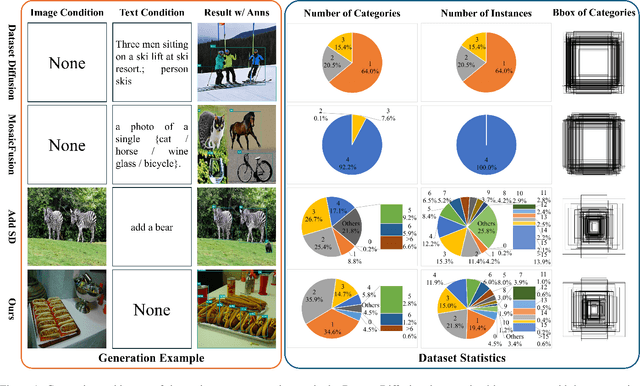
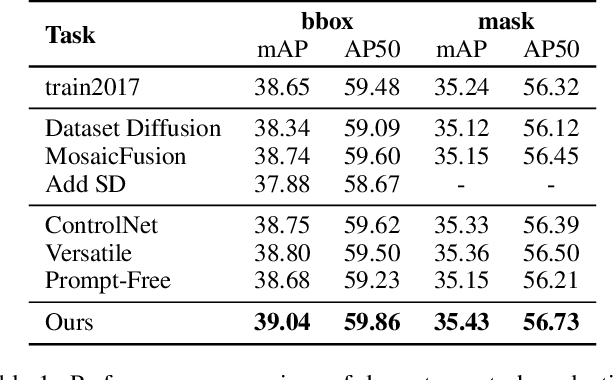
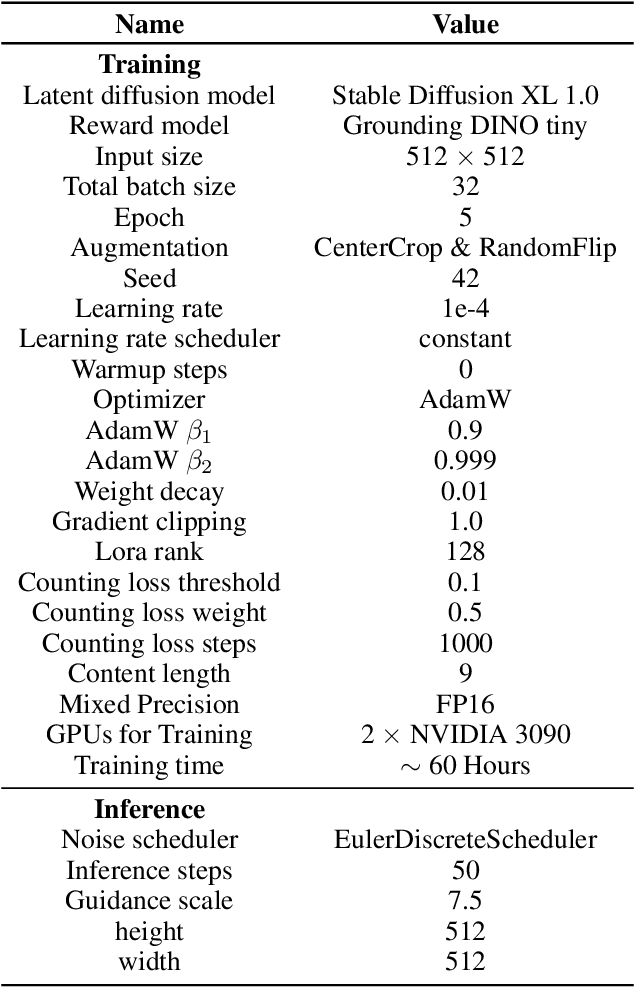

Diffusion models has underpinned much recent advances of dataset augmentation in various computer vision tasks. However, when involving generating multi-object images as real scenarios, most existing methods either rely entirely on text condition, resulting in a deviation between the generated objects and the original data, or rely too much on the original images, resulting in a lack of diversity in the generated images, which is of limited help to downstream tasks. To mitigate both problems with one stone, we propose a prompt-free conditional diffusion framework for multi-object image augmentation. Specifically, we introduce a local-global semantic fusion strategy to extract semantics from images to replace text, and inject knowledge into the diffusion model through LoRA to alleviate the category deviation between the original model and the target dataset. In addition, we design a reward model based counting loss to assist the traditional reconstruction loss for model training. By constraining the object counts of each category instead of pixel-by-pixel constraints, bridging the quantity deviation between the generated data and the original data while improving the diversity of the generated data. Experimental results demonstrate the superiority of the proposed method over several representative state-of-the-art baselines and showcase strong downstream task gain and out-of-domain generalization capabilities. Code is available at \href{https://github.com/00why00/PFCD}{here}.
Fake News Detection: Comparative Evaluation of BERT-like Models and Large Language Models with Generative AI-Annotated Data
Dec 18, 2024



Fake news poses a significant threat to public opinion and social stability in modern society. This study presents a comparative evaluation of BERT-like encoder-only models and autoregressive decoder-only large language models (LLMs) for fake news detection. We introduce a dataset of news articles labeled with GPT-4 assistance (an AI-labeling method) and verified by human experts to ensure reliability. Both BERT-like encoder-only models and LLMs were fine-tuned on this dataset. Additionally, we developed an instruction-tuned LLM approach with majority voting during inference for label generation. Our analysis reveals that BERT-like models generally outperform LLMs in classification tasks, while LLMs demonstrate superior robustness against text perturbations. Compared to weak labels (distant supervision) data, the results show that AI labels with human supervision achieve better classification results. This study highlights the effectiveness of combining AI-based annotation with human oversight and demonstrates the performance of different families of machine learning models for fake news detection
AI-Powered Algorithm-Centric Quantum Processor Topology Design
Dec 18, 2024Quantum computing promises to revolutionize various fields, yet the execution of quantum programs necessitates an effective compilation process. This involves strategically mapping quantum circuits onto the physical qubits of a quantum processor. The qubits' arrangement, or topology, is pivotal to the circuit's performance, a factor that often defies traditional heuristic or manual optimization methods due to its complexity. In this study, we introduce a novel approach leveraging reinforcement learning to dynamically tailor qubit topologies to the unique specifications of individual quantum circuits, guiding algorithm-driven quantum processor topology design for reducing the depth of mapped circuit, which is particularly critical for the output accuracy on noisy quantum processors. Our method marks a significant departure from previous methods that have been constrained to mapping circuits onto a fixed processor topology. Experiments demonstrate that we have achieved notable enhancements in circuit performance, with a minimum of 20\% reduction in circuit depth in 60\% of the cases examined, and a maximum enhancement of up to 46\%. Furthermore, the pronounced benefits of our approach in reducing circuit depth become increasingly evident as the scale of the quantum circuits increases, exhibiting the scalability of our method in terms of problem size. This work advances the co-design of quantum processor architecture and algorithm mapping, offering a promising avenue for future research and development in the field.
Meta-Exploiting Frequency Prior for Cross-Domain Few-Shot Learning
Nov 03, 2024



Meta-learning offers a promising avenue for few-shot learning (FSL), enabling models to glean a generalizable feature embedding through episodic training on synthetic FSL tasks in a source domain. Yet, in practical scenarios where the target task diverges from that in the source domain, meta-learning based method is susceptible to over-fitting. To overcome this, we introduce a novel framework, Meta-Exploiting Frequency Prior for Cross-Domain Few-Shot Learning, which is crafted to comprehensively exploit the cross-domain transferable image prior that each image can be decomposed into complementary low-frequency content details and high-frequency robust structural characteristics. Motivated by this insight, we propose to decompose each query image into its high-frequency and low-frequency components, and parallel incorporate them into the feature embedding network to enhance the final category prediction. More importantly, we introduce a feature reconstruction prior and a prediction consistency prior to separately encourage the consistency of the intermediate feature as well as the final category prediction between the original query image and its decomposed frequency components. This allows for collectively guiding the network's meta-learning process with the aim of learning generalizable image feature embeddings, while not introducing any extra computational cost in the inference phase. Our framework establishes new state-of-the-art results on multiple cross-domain few-shot learning benchmarks.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.