 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSONIC-O1: A Real-World Benchmark for Evaluating Multimodal Large Language Models on Audio-Video Understanding
Jan 29, 2026Multimodal Large Language Models (MLLMs) are a major focus of recent AI research. However, most prior work focuses on static image understanding, while their ability to process sequential audio-video data remains underexplored. This gap highlights the need for a high-quality benchmark to systematically evaluate MLLM performance in a real-world setting. We introduce SONIC-O1, a comprehensive, fully human-verified benchmark spanning 13 real-world conversational domains with 4,958 annotations and demographic metadata. SONIC-O1 evaluates MLLMs on key tasks, including open-ended summarization, multiple-choice question (MCQ) answering, and temporal localization with supporting rationales (reasoning). Experiments on closed- and open-source models reveal limitations. While the performance gap in MCQ accuracy between two model families is relatively small, we observe a substantial 22.6% performance difference in temporal localization between the best performing closed-source and open-source models. Performance further degrades across demographic groups, indicating persistent disparities in model behavior. Overall, SONIC-O1 provides an open evaluation suite for temporally grounded and socially robust multimodal understanding. We release SONIC-O1 for reproducibility and research: Project page: https://vectorinstitute.github.io/sonic-o1/ Dataset: https://huggingface.co/datasets/vector-institute/sonic-o1 Github: https://github.com/vectorinstitute/sonic-o1 Leaderboard: https://huggingface.co/spaces/vector-institute/sonic-o1-leaderboard
Reducing Hallucinations in LLMs via Factuality-Aware Preference Learning
Jan 06, 2026Preference alignment methods such as RLHF and Direct Preference Optimization (DPO) improve instruction following, but they can also reinforce hallucinations when preference judgments reward fluency and confidence over factual correctness. We introduce F-DPO (Factuality-aware Direct Preference Optimization), a simple extension of DPO that uses only binary factuality labels. F-DPO (i) applies a label-flipping transformation that corrects misordered preference pairs so the chosen response is never less factual than the rejected one, and (ii) adds a factuality-aware margin that emphasizes pairs with clear correctness differences, while reducing to standard DPO when both responses share the same factuality. We construct factuality-aware preference data by augmenting DPO pairs with binary factuality indicators and synthetic hallucinated variants. Across seven open-weight LLMs (1B-14B), F-DPO consistently improves factuality and reduces hallucination rates relative to both base models and standard DPO. On Qwen3-8B, F-DPO reduces hallucination rates by five times (from 0.424 to 0.084) while improving factuality scores by 50 percent (from 5.26 to 7.90). F-DPO also generalizes to out-of-distribution benchmarks: on TruthfulQA, Qwen2.5-14B achieves plus 17 percent MC1 accuracy (0.500 to 0.585) and plus 49 percent MC2 accuracy (0.357 to 0.531). F-DPO requires no auxiliary reward model, token-level annotations, or multi-stage training.
LinguaMark: Do Multimodal Models Speak Fairly? A Benchmark-Based Evaluation
Jul 09, 2025Large Multimodal Models (LMMs) are typically trained on vast corpora of image-text data but are often limited in linguistic coverage, leading to biased and unfair outputs across languages. While prior work has explored multimodal evaluation, less emphasis has been placed on assessing multilingual capabilities. In this work, we introduce LinguaMark, a benchmark designed to evaluate state-of-the-art LMMs on a multilingual Visual Question Answering (VQA) task. Our dataset comprises 6,875 image-text pairs spanning 11 languages and five social attributes. We evaluate models using three key metrics: Bias, Answer Relevancy, and Faithfulness. Our findings reveal that closed-source models generally achieve the highest overall performance. Both closed-source (GPT-4o and Gemini2.5) and open-source models (Gemma3, Qwen2.5) perform competitively across social attributes, and Qwen2.5 demonstrates strong generalization across multiple languages. We release our benchmark and evaluation code to encourage reproducibility and further research.
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025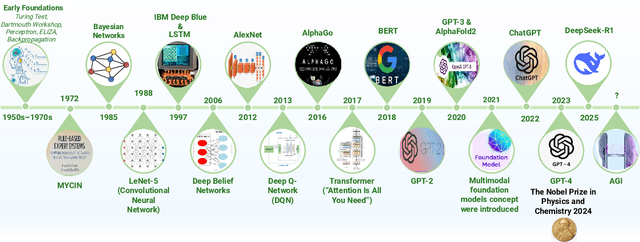
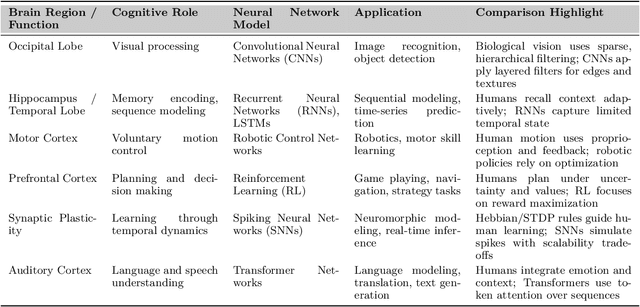
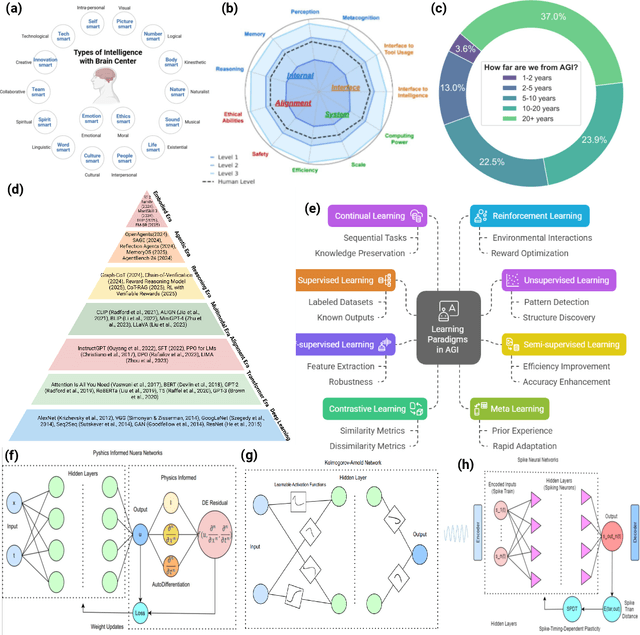
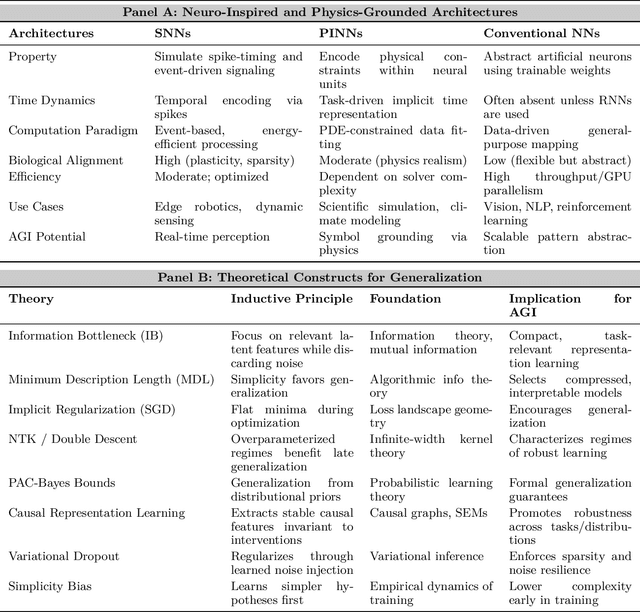
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
TRiSM for Agentic AI: A Review of Trust, Risk, and Security Management in LLM-based Agentic Multi-Agent Systems
Jun 04, 2025Agentic AI systems, built on large language models (LLMs) and deployed in multi-agent configurations, are redefining intelligent autonomy, collaboration and decision-making across enterprise and societal domains. This review presents a structured analysis of Trust, Risk, and Security Management (TRiSM) in the context of LLM-based agentic multi-agent systems (AMAS). We begin by examining the conceptual foundations of agentic AI, its architectural differences from traditional AI agents, and the emerging system designs that enable scalable, tool-using autonomy. The TRiSM in the agentic AI framework is then detailed through four pillars governance, explainability, ModelOps, and privacy/security each contextualized for agentic LLMs. We identify unique threat vectors and introduce a comprehensive risk taxonomy for the agentic AI applications, supported by case studies illustrating real-world vulnerabilities. Furthermore, the paper also surveys trust-building mechanisms, transparency and oversight techniques, and state-of-the-art explainability strategies in distributed LLM agent systems. Additionally, metrics for evaluating trust, interpretability, and human-centered performance are reviewed alongside open benchmarking challenges. Security and privacy are addressed through encryption, adversarial defense, and compliance with evolving AI regulations. The paper concludes with a roadmap for responsible agentic AI, proposing research directions to align emerging multi-agent systems with robust TRiSM principles for safe, accountable, and transparent deployment.
Just as Humans Need Vaccines, So Do Models: Model Immunization to Combat Falsehoods
May 23, 2025Generative AI models often learn and reproduce false information present in their training corpora. This position paper argues that, analogous to biological immunization, where controlled exposure to a weakened pathogen builds immunity, AI models should be fine tuned on small, quarantined sets of explicitly labeled falsehoods as a "vaccine" against misinformation. These curated false examples are periodically injected during finetuning, strengthening the model ability to recognize and reject misleading claims while preserving accuracy on truthful inputs. An illustrative case study shows that immunized models generate substantially less misinformation than baselines. To our knowledge, this is the first training framework that treats fact checked falsehoods themselves as a supervised vaccine, rather than relying on input perturbations or generic human feedback signals, to harden models against future misinformation. We also outline ethical safeguards and governance controls to ensure the safe use of false data. Model immunization offers a proactive paradigm for aligning AI systems with factuality.
HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
May 16, 2025



Large multimodal models (LMMs) now excel on many vision language benchmarks, however, they still struggle with human centered criteria such as fairness, ethics, empathy, and inclusivity, key to aligning with human values. We introduce HumaniBench, a holistic benchmark of 32K real-world image question pairs, annotated via a scalable GPT4o assisted pipeline and exhaustively verified by domain experts. HumaniBench evaluates seven Human Centered AI (HCAI) principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, across seven diverse tasks, including open and closed ended visual question answering (VQA), multilingual QA, visual grounding, empathetic captioning, and robustness tests. Benchmarking 15 state of the art LMMs (open and closed source) reveals that proprietary models generally lead, though robustness and visual grounding remain weak points. Some open-source models also struggle to balance accuracy with adherence to human-aligned principles. HumaniBench is the first benchmark purpose built around HCAI principles. It provides a rigorous testbed for diagnosing alignment gaps and guiding LMMs toward behavior that is both accurate and socially responsible. Dataset, annotation prompts, and evaluation code are available at: https://vectorinstitute.github.io/HumaniBench
The Rise of Small Language Models in Healthcare: A Comprehensive Survey
Apr 23, 2025Despite substantial progress in healthcare applications driven by large language models (LLMs), growing concerns around data privacy, and limited resources; the small language models (SLMs) offer a scalable and clinically viable solution for efficient performance in resource-constrained environments for next-generation healthcare informatics. Our comprehensive survey presents a taxonomic framework to identify and categorize them for healthcare professionals and informaticians. The timeline of healthcare SLM contributions establishes a foundational framework for analyzing models across three dimensions: NLP tasks, stakeholder roles, and the continuum of care. We present a taxonomic framework to identify the architectural foundations for building models from scratch; adapting SLMs to clinical precision through prompting, instruction fine-tuning, and reasoning; and accessibility and sustainability through compression techniques. Our primary objective is to offer a comprehensive survey for healthcare professionals, introducing recent innovations in model optimization and equipping them with curated resources to support future research and development in the field. Aiming to showcase the groundbreaking advancements in SLMs for healthcare, we present a comprehensive compilation of experimental results across widely studied NLP tasks in healthcare to highlight the transformative potential of SLMs in healthcare. The updated repository is available at Github
Optimizing Large Language Models: Metrics, Energy Efficiency, and Case Study Insights
Apr 07, 2025The rapid adoption of large language models (LLMs) has led to significant energy consumption and carbon emissions, posing a critical challenge to the sustainability of generative AI technologies. This paper explores the integration of energy-efficient optimization techniques in the deployment of LLMs to address these environmental concerns. We present a case study and framework that demonstrate how strategic quantization and local inference techniques can substantially lower the carbon footprints of LLMs without compromising their operational effectiveness. Experimental results reveal that these methods can reduce energy consumption and carbon emissions by up to 45\% post quantization, making them particularly suitable for resource-constrained environments. The findings provide actionable insights for achieving sustainability in AI while maintaining high levels of accuracy and responsiveness.
FairSense-AI: Responsible AI Meets Sustainability
Mar 05, 2025

In this paper, we introduce FairSense-AI: a multimodal framework designed to detect and mitigate bias in both text and images. By leveraging Large Language Models (LLMs) and Vision-Language Models (VLMs), FairSense-AI uncovers subtle forms of prejudice or stereotyping that can appear in content, providing users with bias scores, explanatory highlights, and automated recommendations for fairness enhancements. In addition, FairSense-AI integrates an AI risk assessment component that aligns with frameworks like the MIT AI Risk Repository and NIST AI Risk Management Framework, enabling structured identification of ethical and safety concerns. The platform is optimized for energy efficiency via techniques such as model pruning and mixed-precision computation, thereby reducing its environmental footprint. Through a series of case studies and applications, we demonstrate how FairSense-AI promotes responsible AI use by addressing both the social dimension of fairness and the pressing need for sustainability in large-scale AI deployments. https://vectorinstitute.github.io/FairSense-AI, https://pypi.org/project/fair-sense-ai/ (Sustainability , Responsible AI , Large Language Models , Vision Language Models , Ethical AI , Green AI)