 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does RL Help Medical VLMs? Disentangling Vision, SFT, and RL Gains
Mar 01, 2026Reinforcement learning (RL) is increasingly used to post-train medical Vision-Language Models (VLMs), yet it remains unclear whether RL improves medical visual reasoning or mainly sharpens behaviors already induced by supervised fine-tuning (SFT). We present a controlled study that disentangles these effects along three axes: vision, SFT, and RL. Using MedMNIST as a multi-modality testbed, we probe visual perception by benchmarking VLM vision towers against vision-only baselines, quantify reasoning support and sampling efficiency via Accuracy@1 versus Pass@K, and evaluate when RL closes the support gap and how gains transfer across modalities. We find that RL is most effective when the model already has non-trivial support (high Pass@K): it primarily sharpens the output distribution, improving Acc@1 and sampling efficiency, while SFT expands support and makes RL effective. Based on these findings, we propose a boundary-aware recipe and instantiate it by RL post-training an OctoMed-initialized model on a small, balanced subset of PMC multiple-choice VQA, achieving strong average performance across six medical VQA benchmarks.
Assessing the Quality of Mental Health Support in LLM Responses through Multi-Attribute Human Evaluation
Jan 26, 2026The escalating global mental health crisis, marked by persistent treatment gaps, availability, and a shortage of qualified therapists, positions Large Language Models (LLMs) as a promising avenue for scalable support. While LLMs offer potential for accessible emotional assistance, their reliability, therapeutic relevance, and alignment with human standards remain challenging to address. This paper introduces a human-grounded evaluation methodology designed to assess LLM generated responses in therapeutic dialogue. Our approach involved curating a dataset of 500 mental health conversations from datasets with real-world scenario questions and evaluating the responses generated by nine diverse LLMs, including closed source and open source models. More specifically, these responses were evaluated by two psychiatric trained experts, who independently rated each on a 5 point Likert scale across a comprehensive 6 attribute rubric. This rubric captures Cognitive Support and Affective Resonance, providing a multidimensional perspective on therapeutic quality. Our analysis reveals that LLMs provide strong cognitive reliability by producing safe, coherent, and clinically appropriate information, but they demonstrate unstable affective alignment. Although closed source models (e.g., GPT-4o) offer balanced therapeutic responses, open source models show greater variability and emotional flatness. We reveal a persistent cognitive-affective gap and highlight the need for failure aware, clinically grounded evaluation frameworks that prioritize relational sensitivity alongside informational accuracy in mental health oriented LLMs. We advocate for balanced evaluation protocols with human in the loop that center on therapeutic sensitivity and provide a framework to guide the responsible design and clinical oversight of mental health oriented conversational AI.
When Can We Trust LLMs in Mental Health? Large-Scale Benchmarks for Reliable LLM Evaluation
Oct 21, 2025Evaluating Large Language Models (LLMs) for mental health support is challenging due to the emotionally and cognitively complex nature of therapeutic dialogue. Existing benchmarks are limited in scale, reliability, often relying on synthetic or social media data, and lack frameworks to assess when automated judges can be trusted. To address the need for large-scale dialogue datasets and judge reliability assessment, we introduce two benchmarks that provide a framework for generation and evaluation. MentalBench-100k consolidates 10,000 one-turn conversations from three real scenarios datasets, each paired with nine LLM-generated responses, yielding 100,000 response pairs. MentalAlign-70k}reframes evaluation by comparing four high-performing LLM judges with human experts across 70,000 ratings on seven attributes, grouped into Cognitive Support Score (CSS) and Affective Resonance Score (ARS). We then employ the Affective Cognitive Agreement Framework, a statistical methodology using intraclass correlation coefficients (ICC) with confidence intervals to quantify agreement, consistency, and bias between LLM judges and human experts. Our analysis reveals systematic inflation by LLM judges, strong reliability for cognitive attributes such as guidance and informativeness, reduced precision for empathy, and some unreliability in safety and relevance. Our contributions establish new methodological and empirical foundations for reliable, large-scale evaluation of LLMs in mental health. We release the benchmarks and codes at: https://github.com/abeerbadawi/MentalBench/
A Flexible Fairness Framework with Surrogate Loss Reweighting for Addressing Sociodemographic Disparities
Mar 21, 2025This paper presents a new algorithmic fairness framework called $\boldsymbol{\alpha}$-$\boldsymbol{\beta}$ Fair Machine Learning ($\boldsymbol{\alpha}$-$\boldsymbol{\beta}$ FML), designed to optimize fairness levels across sociodemographic attributes. Our framework employs a new family of surrogate loss functions, paired with loss reweighting techniques, allowing precise control over fairness-accuracy trade-offs through tunable hyperparameters $\boldsymbol{\alpha}$ and $\boldsymbol{\beta}$. To efficiently solve the learning objective, we propose Parallel Stochastic Gradient Descent with Surrogate Loss (P-SGD-S) and establish convergence guarantees for both convex and nonconvex loss functions. Experimental results demonstrate that our framework improves overall accuracy while reducing fairness violations, offering a smooth trade-off between standard empirical risk minimization and strict minimax fairness. Results across multiple datasets confirm its adaptability, ensuring fairness improvements without excessive performance degradation.
Advancing Medical Representation Learning Through High-Quality Data
Mar 18, 2025Despite the growing scale of medical Vision-Language datasets, the impact of dataset quality on model performance remains under-explored. We introduce Open-PMC, a high-quality medical dataset from PubMed Central, containing 2.2 million image-text pairs, enriched with image modality annotations, subfigures, and summarized in-text references. Notably, the in-text references provide richer medical context, extending beyond the abstract information typically found in captions. Through extensive experiments, we benchmark Open-PMC against larger datasets across retrieval and zero-shot classification tasks. Our results show that dataset quality-not just size-drives significant performance gains. We complement our benchmark with an in-depth analysis of feature representation. Our findings highlight the crucial role of data curation quality in advancing multimodal medical AI. We release Open-PMC, along with the trained models and our codebase.
Similarity-Aware Token Pruning: Your VLM but Faster
Mar 14, 2025The computational demands of Vision Transformers (ViTs) and Vision-Language Models (VLMs) remain a significant challenge due to the quadratic complexity of self-attention. While token pruning offers a promising solution, existing methods often introduce training overhead or fail to adapt dynamically across layers. We present SAINT, a training-free token pruning framework that leverages token similarity and a graph-based formulation to dynamically optimize pruning rates and redundancy thresholds. Through systematic analysis, we identify a universal three-stage token evolution process (aligner-explorer-aggregator) in transformers, enabling aggressive pruning in early stages without sacrificing critical information. For ViTs, SAINT doubles the throughput of ViT-H/14 at 224px with only 0.6% accuracy loss on ImageNet-1K, surpassing the closest competitor by 0.8%. For VLMs, we apply SAINT in three modes: ViT-only, LLM-only, and hybrid. SAINT reduces LLaVA-13B's tokens by 75%, achieving latency comparable to LLaVA-7B with less than 1% performance loss across benchmarks. Our work establishes a unified, practical framework for efficient inference in ViTs and VLMs.
A Shared Encoder Approach to Multimodal Representation Learning
Mar 03, 2025Multimodal representation learning has demonstrated remarkable potential in enabling models to process and integrate diverse data modalities, such as text and images, for improved understanding and performance. While the medical domain can benefit significantly from this paradigm, the scarcity of paired multimodal data and reliance on proprietary or pretrained encoders pose significant challenges. In this work, we present a shared encoder framework for multimodal representation learning tailored to the medical domain. Our approach employs a single set of encoder parameters shared across modalities, augmented with learnable modality features. Empirical results demonstrate that our shared encoder idea achieves superior performance compared to separate modality-specific encoders, demonstrating improved generalization in data-constrained settings. Notably, the performance gains are more pronounced with fewer training examples, underscoring the efficiency of our shared encoder framework for real-world medical applications with limited data. Our code and experiment setup are available at https://github.com/VectorInstitute/shared_encoder.
VLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.
Exploring Bias and Prediction Metrics to Characterise the Fairness of Machine Learning for Equity-Centered Public Health Decision-Making: A Narrative Review
Aug 23, 2024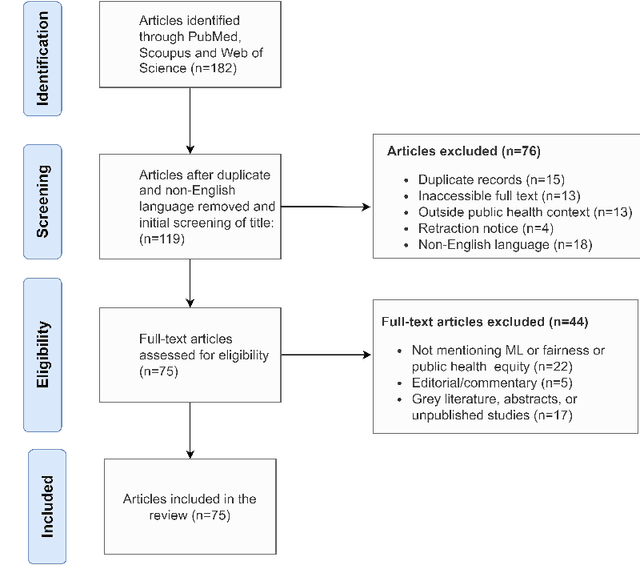


Background: The rapid advancement of Machine Learning (ML) represents novel opportunities to enhance public health research, surveillance, and decision-making. However, there is a lack of comprehensive understanding of algorithmic bias -- systematic errors in predicted population health outcomes -- resulting from the public health application of ML. The objective of this narrative review is to explore the types of bias generated by ML and quantitative metrics to assess these biases. Methods: We performed search on PubMed, MEDLINE, IEEE (Institute of Electrical and Electronics Engineers), ACM (Association for Computing Machinery) Digital Library, Science Direct, and Springer Nature. We used keywords to identify studies describing types of bias and metrics to measure these in the domain of ML and public and population health published in English between 2008 and 2023, inclusive. Results: A total of 72 articles met the inclusion criteria. Our review identified the commonly described types of bias and quantitative metrics to assess these biases from an equity perspective. Conclusion: The review will help formalize the evaluation framework for ML on public health from an equity perspective.
Practical Guide for Causal Pathways and Sub-group Disparity Analysis
Jul 02, 2024



In this study, we introduce the application of causal disparity analysis to unveil intricate relationships and causal pathways between sensitive attributes and the targeted outcomes within real-world observational data. Our methodology involves employing causal decomposition analysis to quantify and examine the causal interplay between sensitive attributes and outcomes. We also emphasize the significance of integrating heterogeneity assessment in causal disparity analysis to gain deeper insights into the impact of sensitive attributes within specific sub-groups on outcomes. Our two-step investigation focuses on datasets where race serves as the sensitive attribute. The results on two datasets indicate the benefit of leveraging causal analysis and heterogeneity assessment not only for quantifying biases in the data but also for disentangling their influences on outcomes. We demonstrate that the sub-groups identified by our approach to be affected the most by disparities are the ones with the largest ML classification errors. We also show that grouping the data only based on a sensitive attribute is not enough, and through these analyses, we can find sub-groups that are directly affected by disparities. We hope that our findings will encourage the adoption of such methodologies in future ethical AI practices and bias audits, fostering a more equitable and fair technological landscape.