 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM For Loop Invariant Generation and Fixing: How Far Are We?
Nov 09, 2025

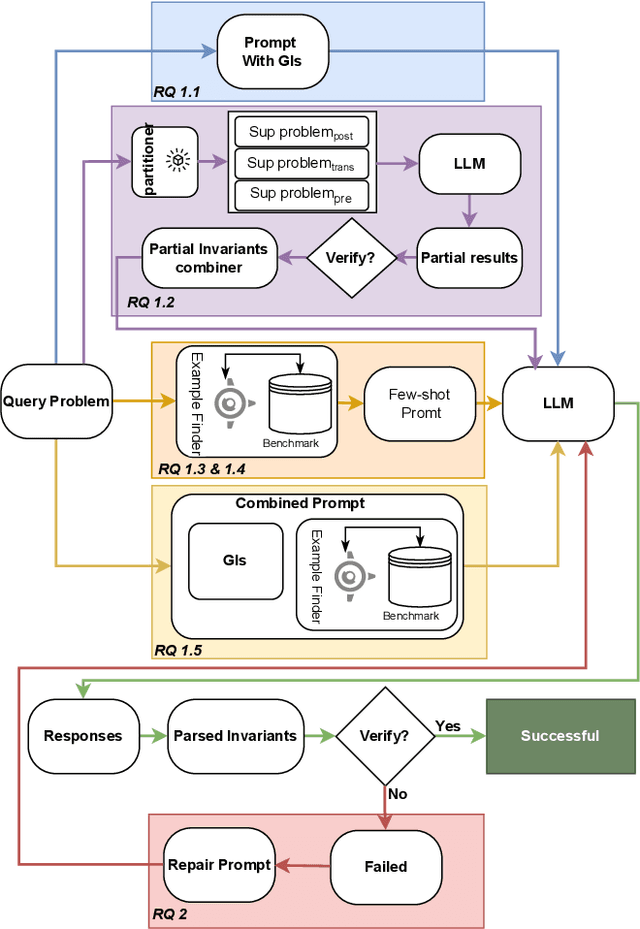

A loop invariant is a property of a loop that remains true before and after each execution of the loop. The identification of loop invariants is a critical step to support automated program safety assessment. Recent advancements in Large Language Models (LLMs) have demonstrated potential in diverse software engineering (SE) and formal verification tasks. However, we are not aware of the performance of LLMs to infer loop invariants. We report an empirical study of both open-source and closed-source LLMs of varying sizes to assess their proficiency in inferring inductive loop invariants for programs and in fixing incorrect invariants. Our findings reveal that while LLMs exhibit some utility in inferring and repairing loop invariants, their performance is substantially enhanced when supplemented with auxiliary information such as domain knowledge and illustrative examples. LLMs achieve a maximum success rate of 78\% in generating, but are limited to 16\% in repairing the invariant.
An Empirical Study of Reasoning Steps in Thinking Code LLMs
Nov 08, 2025Thinking Large Language Models (LLMs) generate explicit intermediate reasoning traces before final answers, potentially improving transparency, interpretability, and solution accuracy for code generation. However, the quality of these reasoning chains remains underexplored. We present a comprehensive empirical study examining the reasoning process and quality of thinking LLMs for code generation. We evaluate six state-of-the-art reasoning LLMs (DeepSeek-R1, OpenAI-o3-mini, Claude-3.7-Sonnet-Thinking, Gemini-2.0-Flash-Thinking, Gemini-2.5-Flash, and Qwen-QwQ) across 100 code generation tasks of varying difficulty from BigCodeBench. We quantify reasoning-chain structure through step counts and verbosity, conduct controlled step-budget adjustments, and perform a 21-participant human evaluation across three dimensions: efficiency, logical correctness, and completeness. Our step-count interventions reveal that targeted step increases can improve resolution rates for certain models/tasks, while modest reductions often preserve success on standard tasks, rarely on hard ones. Through systematic analysis, we develop a reasoning-problematic taxonomy, identifying completeness as the dominant failure mode. Task complexity significantly impacts reasoning quality; hard problems are substantially more prone to incompleteness than standard tasks. Our stability analysis demonstrates that thinking LLMs maintain consistent logical structures across computational effort levels and can self-correct previous errors. This study provides new insights into the strengths and limitations of current thinking LLMs in software engineering.
Stack Trace-Based Crash Deduplication with Transformer Adaptation
Aug 26, 2025Automated crash reporting systems generate large volumes of duplicate reports, overwhelming issue-tracking systems and increasing developer workload. Traditional stack trace-based deduplication methods, relying on string similarity, rule-based heuristics, or deep learning (DL) models, often fail to capture the contextual and structural relationships within stack traces. We propose dedupT, a transformer-based approach that models stack traces holistically rather than as isolated frames. dedupT first adapts a pretrained language model (PLM) to stack traces, then uses its embeddings to train a fully-connected network (FCN) to rank duplicate crashes effectively. Extensive experiments on real-world datasets show that dedupT outperforms existing DL and traditional methods (e.g., sequence alignment and information retrieval techniques) in both duplicate ranking and unique crash detection, significantly reducing manual triage effort. On four public datasets, dedupT improves Mean Reciprocal Rank (MRR) often by over 15% compared to the best DL baseline and up to 9% over traditional methods while achieving higher Receiver Operating Characteristic Area Under the Curve (ROC-AUC) in detecting unique crash reports. Our work advances the integration of modern natural language processing (NLP) techniques into software engineering, providing an effective solution for stack trace-based crash deduplication.
TriagerX: Dual Transformers for Bug Triaging Tasks with Content and Interaction Based Rankings
Aug 23, 2025Pretrained Language Models or PLMs are transformer-based architectures that can be used in bug triaging tasks. PLMs can better capture token semantics than traditional Machine Learning (ML) models that rely on statistical features (e.g., TF-IDF, bag of words). However, PLMs may still attend to less relevant tokens in a bug report, which can impact their effectiveness. In addition, the model can be sub-optimal with its recommendations when the interaction history of developers around similar bugs is not taken into account. We designed TriagerX to address these limitations. First, to assess token semantics more reliably, we leverage a dual-transformer architecture. Unlike current state-of-the-art (SOTA) baselines that employ a single transformer architecture, TriagerX collects recommendations from two transformers with each offering recommendations via its last three layers. This setup generates a robust content-based ranking of candidate developers. TriagerX then refines this ranking by employing a novel interaction-based ranking methodology, which considers developers' historical interactions with similar fixed bugs. Across five datasets, TriagerX surpasses all nine transformer-based methods, including SOTA baselines, often improving Top-1 and Top-3 developer recommendation accuracy by over 10%. We worked with our large industry partner to successfully deploy TriagerX in their development environment. The partner required both developer and component recommendations, with components acting as proxies for team assignments-particularly useful in cases of developer turnover or team changes. We trained TriagerX on the partner's dataset for both tasks, and it outperformed SOTA baselines by up to 10% for component recommendations and 54% for developer recommendations.
Hallucination Detection in Large Language Models with Metamorphic Relations
Feb 20, 2025
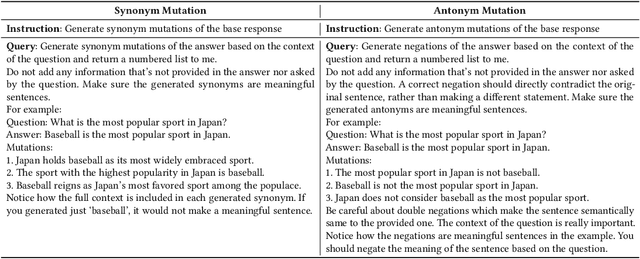
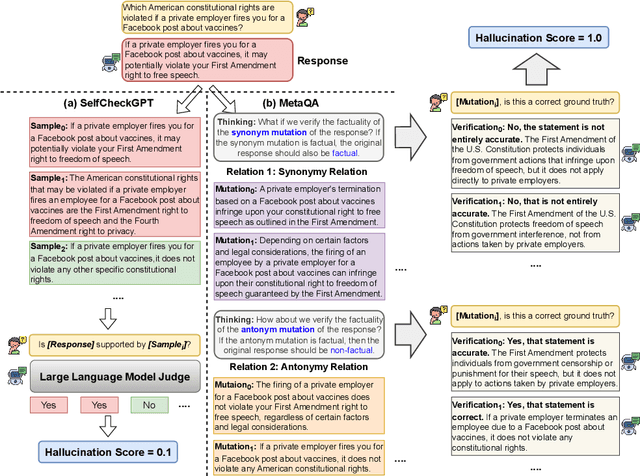
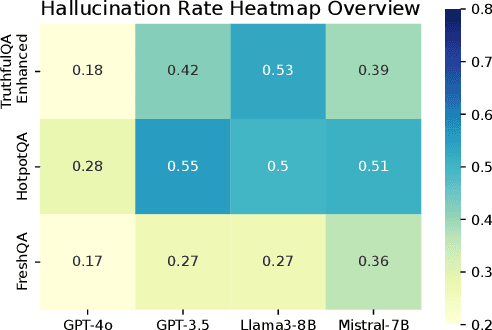
Large Language Models (LLMs) are prone to hallucinations, e.g., factually incorrect information, in their responses. These hallucinations present challenges for LLM-based applications that demand high factual accuracy. Existing hallucination detection methods primarily depend on external resources, which can suffer from issues such as low availability, incomplete coverage, privacy concerns, high latency, low reliability, and poor scalability. There are also methods depending on output probabilities, which are often inaccessible for closed-source LLMs like GPT models. This paper presents MetaQA, a self-contained hallucination detection approach that leverages metamorphic relation and prompt mutation. Unlike existing methods, MetaQA operates without any external resources and is compatible with both open-source and closed-source LLMs. MetaQA is based on the hypothesis that if an LLM's response is a hallucination, the designed metamorphic relations will be violated. We compare MetaQA with the state-of-the-art zero-resource hallucination detection method, SelfCheckGPT, across multiple datasets, and on two open-source and two closed-source LLMs. Our results reveal that MetaQA outperforms SelfCheckGPT in terms of precision, recall, and f1 score. For the four LLMs we study, MetaQA outperforms SelfCheckGPT with a superiority margin ranging from 0.041 - 0.113 (for precision), 0.143 - 0.430 (for recall), and 0.154 - 0.368 (for F1-score). For instance, with Mistral-7B, MetaQA achieves an average F1-score of 0.435, compared to SelfCheckGPT's F1-score of 0.205, representing an improvement rate of 112.2%. MetaQA also demonstrates superiority across all different categories of questions.
VLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.
Perceived Confidence Scoring for Data Annotation with Zero-Shot LLMs
Feb 11, 2025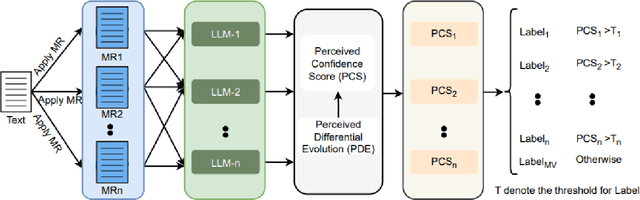
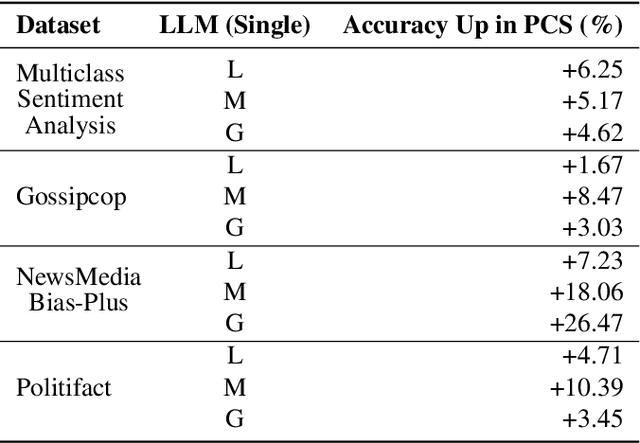
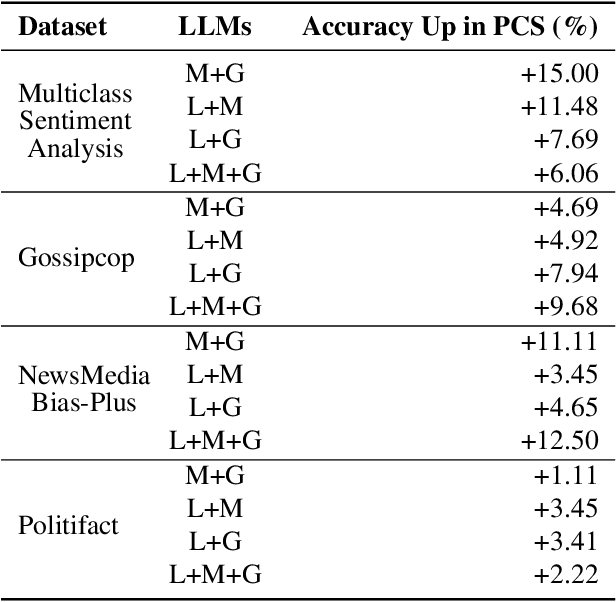
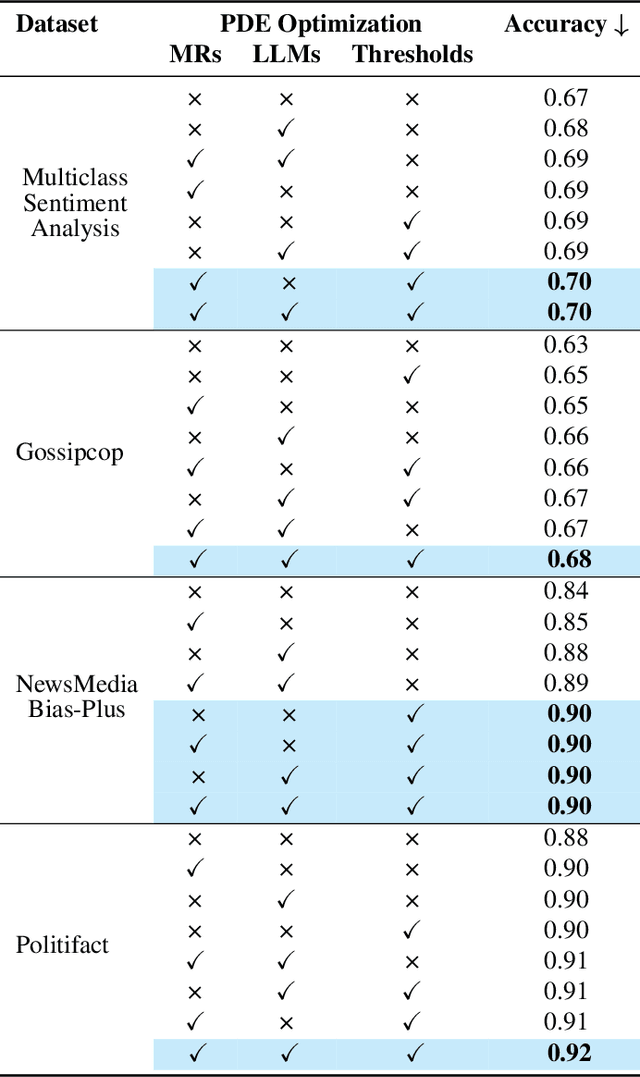
Zero-shot LLMs are now also used for textual classification tasks, e.g., sentiment/emotion detection of a given input as a sentence/article. However, their performance can be suboptimal in such data annotation tasks. We introduce a novel technique Perceived Confidence Scoring (PCS) that evaluates LLM's confidence for its classification of an input by leveraging Metamorphic Relations (MRs). The MRs generate semantically equivalent yet textually mutated versions of the input. Following the principles of Metamorphic Testing (MT), the mutated versions are expected to have annotation labels similar to the input. By analyzing the consistency of LLM responses across these variations, PCS computes a confidence score based on the frequency of predicted labels. PCS can be used both for single LLM and multiple LLM settings (e.g., majority voting). We introduce an algorithm Perceived Differential Evolution (PDE) that determines the optimal weights assigned to the MRs and the LLMs for a classification task. Empirical evaluation shows PCS significantly improves zero-shot accuracy for Llama-3-8B-Instruct (4.96%) and Mistral-7B-Instruct-v0.3 (10.52%), with Gemma-2-9b-it showing a 9.39% gain. When combining all three models, PCS significantly outperforms majority voting by 7.75%.
ChatGPT Incorrectness Detection in Software Reviews
Mar 25, 2024We conducted a survey of 135 software engineering (SE) practitioners to understand how they use Generative AI-based chatbots like ChatGPT for SE tasks. We find that they want to use ChatGPT for SE tasks like software library selection but often worry about the truthfulness of ChatGPT responses. We developed a suite of techniques and a tool called CID (ChatGPT Incorrectness Detector) to automatically test and detect the incorrectness in ChatGPT responses. CID is based on the iterative prompting to ChatGPT by asking it contextually similar but textually divergent questions (using an approach that utilizes metamorphic relationships in texts). The underlying principle in CID is that for a given question, a response that is different from other responses (across multiple incarnations of the question) is likely an incorrect response. In a benchmark study of library selection, we show that CID can detect incorrect responses from ChatGPT with an F1-score of 0.74 - 0.75.
Contrastive Learning for API Aspect Analysis
Aug 14, 2023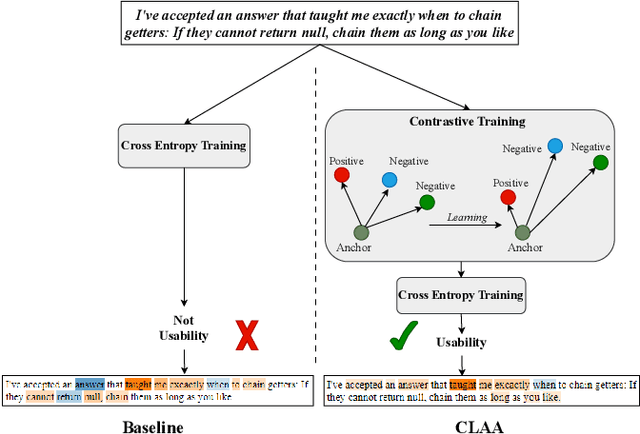



We present a novel approach - CLAA - for API aspect detection in API reviews that utilizes transformer models trained with a supervised contrastive loss objective function. We evaluate CLAA using performance and impact analysis. For performance analysis, we utilized a benchmark dataset on developer discussions collected from Stack Overflow and compare the results to those obtained using state-of-the-art transformer models. Our experiments show that contrastive learning can significantly improve the performance of transformer models in detecting aspects such as Performance, Security, Usability, and Documentation. For impact analysis, we performed empirical and developer study. On a randomly selected and manually labeled 200 online reviews, CLAA achieved 92% accuracy while the SOTA baseline achieved 81.5%. According to our developer study involving 10 participants, the use of 'Stack Overflow + CLAA' resulted in increased accuracy and confidence during API selection. Replication package: https://github.com/disa-lab/Contrastive-Learning-API-Aspect-ASE2023
An Empirical Study of IoT Security Aspects at Sentence-Level in Developer Textual Discussions
Jun 07, 2022
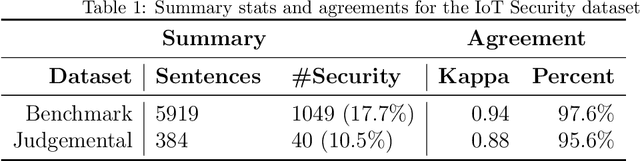
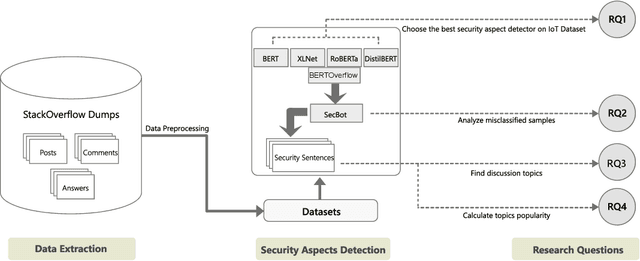
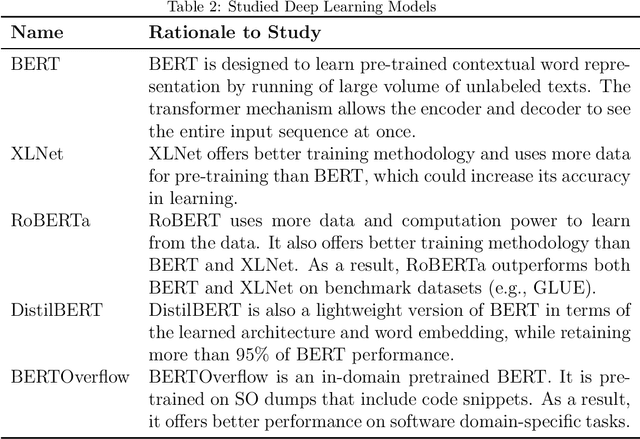
IoT is a rapidly emerging paradigm that now encompasses almost every aspect of our modern life. As such, ensuring the security of IoT devices is crucial. IoT devices can differ from traditional computing, thereby the design and implementation of proper security measures can be challenging in IoT devices. We observed that IoT developers discuss their security-related challenges in developer forums like Stack Overflow(SO). However, we find that IoT security discussions can also be buried inside non-security discussions in SO. In this paper, we aim to understand the challenges IoT developers face while applying security practices and techniques to IoT devices. We have two goals: (1) Develop a model that can automatically find security-related IoT discussions in SO, and (2) Study the model output to learn about IoT developer security-related challenges. First, we download 53K posts from SO that contain discussions about IoT. Second, we manually labeled 5,919 sentences from 53K posts as 1 or 0. Third, we use this benchmark to investigate a suite of deep learning transformer models. The best performing model is called SecBot. Fourth, we apply SecBot on the entire posts and find around 30K security related sentences. Fifth, we apply topic modeling to the security-related sentences. Then we label and categorize the topics. Sixth, we analyze the evolution of the topics in SO. We found that (1) SecBot is based on the retraining of the deep learning model RoBERTa. SecBot offers the best F1-Score of 0.935, (2) there are six error categories in misclassified samples by SecBot. SecBot was mostly wrong when the keywords/contexts were ambiguous (e.g., gateway can be a security gateway or a simple gateway), (3) there are 9 security topics grouped into three categories: Software, Hardware, and Network, and (4) the highest number of topics belongs to software security, followed by network security.