 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.
Progress in Privacy Protection: A Review of Privacy Preserving Techniques in Recommender Systems, Edge Computing, and Cloud Computing
Jan 20, 2024



As digital technology evolves, the increasing use of connected devices brings both challenges and opportunities in the areas of mobile crowdsourcing, edge computing, and recommender systems. This survey focuses on these dynamic fields, emphasizing the critical need for privacy protection in our increasingly data-oriented world. It explores the latest trends in these interconnected areas, with a special emphasis on privacy and data security. Our method involves an in-depth analysis of various academic works, which helps us to gain a comprehensive understanding of these sectors and their shifting focus towards privacy concerns. We present new insights and marks a significant advancement in addressing privacy issues within these technologies. The survey is a valuable resource for researchers, industry practitioners, and policy makers, offering an extensive overview of these fields and their related privacy challenges, catering to a wide audience in the modern digital era.
NBIAS: A Natural Language Processing Framework for Bias Identification in Text
Aug 08, 2023



Bias in textual data can lead to skewed interpretations and outcomes when the data is used. These biases could perpetuate stereotypes, discrimination, or other forms of unfair treatment. An algorithm trained on biased data ends up making decisions that disproportionately impact a certain group of people. Therefore, it is crucial to detect and remove these biases to ensure the fair and ethical use of data. To this end, we develop a comprehensive and robust framework \textsc{Nbias} that consists of a data layer, corpus contruction, model development layer and an evaluation layer. The dataset is constructed by collecting diverse data from various fields, including social media, healthcare, and job hiring portals. As such, we applied a transformer-based token classification model that is able to identify bias words/ phrases through a unique named entity. In the assessment procedure, we incorporate a blend of quantitative and qualitative evaluations to gauge the effectiveness of our models. We achieve accuracy improvements ranging from 1% to 8% compared to baselines. We are also able to generate a robust understanding of the model functioning, capturing not only numerical data but also the quality and intricacies of its performance. The proposed approach is applicable to a variety of biases and contributes to the fair and ethical use of textual data.
Fairness in Machine Learning meets with Equity in Healthcare
May 11, 2023
With the growing utilization of machine learning in healthcare, there is increasing potential to enhance healthcare outcomes and efficiency. However, this also brings the risk of perpetuating biases in data and model design that can harm certain protected groups based on factors such as age, gender, and race. This study proposes an artificial intelligence framework, grounded in software engineering principles, for identifying and mitigating biases in data and models while ensuring fairness in healthcare settings. A case study is presented to demonstrate how systematic biases in data can lead to amplified biases in model predictions, and machine learning methods are suggested to prevent such biases. Future research aims to test and validate the proposed ML framework in real-world clinical settings to evaluate its impact on promoting health equity.
Leveraging Foundation Models for Clinical Text Analysis
Mar 20, 2023



Infectious diseases are a significant public health concern globally, and extracting relevant information from scientific literature can facilitate the development of effective prevention and treatment strategies. However, the large amount of clinical data available presents a challenge for information extraction. To address this challenge, this study proposes a natural language processing (NLP) framework that uses a pre-trained transformer model fine-tuned on task-specific data to extract key information related to infectious diseases from free-text clinical data. The proposed framework includes three components: a data layer for preparing datasets from clinical texts, a foundation model layer for entity extraction, and an assessment layer for performance analysis. The results of the evaluation indicate that the proposed method outperforms standard methods, and leveraging prior knowledge through the pre-trained transformer model makes it useful for investigating other infectious diseases in the future.
Addressing Biases in the Texts using an End-to-End Pipeline Approach
Mar 13, 2023


The concept of fairness is gaining popularity in academia and industry. Social media is especially vulnerable to media biases and toxic language and comments. We propose a fair ML pipeline that takes a text as input and determines whether it contains biases and toxic content. Then, based on pre-trained word embeddings, it suggests a set of new words by substituting the bi-ased words, the idea is to lessen the effects of those biases by replacing them with alternative words. We compare our approach to existing fairness models to determine its effectiveness. The results show that our proposed pipeline can de-tect, identify, and mitigate biases in social media data
BERT4Loc: BERT for Location -- POI Recommender System
Aug 02, 2022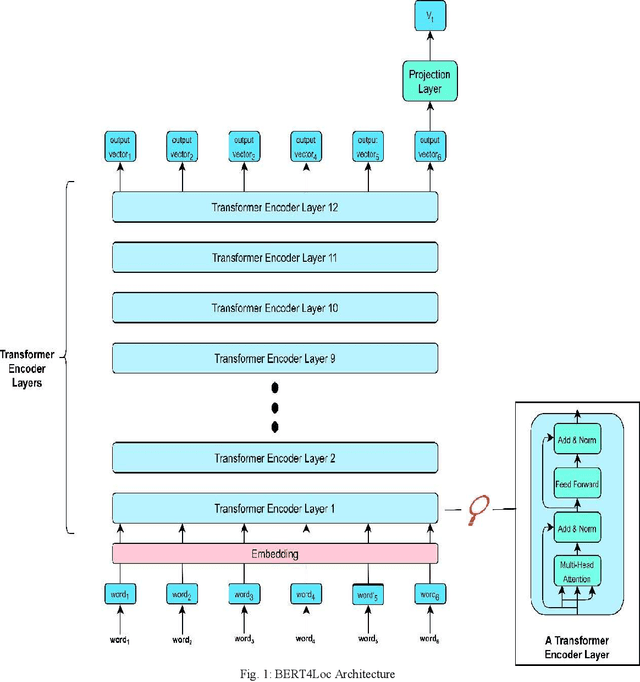
Recommending points of interest is a difficult problem that requires precise location information to be extracted from a location-based social media platform. Another challenging and critical problem for such a location-aware recommendation system is modelling users' preferences based on their historical behaviors. We propose a location-aware recommender system based on Bidirectional Encoder Representations from Transformers for the purpose of providing users with location-based recommendations. The proposed model incorporates location data and user preferences. When compared to predicting the next item of interest (location) at each position in a sequence, our model can provide the user with more relevant results. Extensive experiments on a benchmark dataset demonstrate that our model consistently outperforms a variety of state-of-the-art sequential models.
An Approach to Ensure Fairness in News Articles
Jul 08, 2022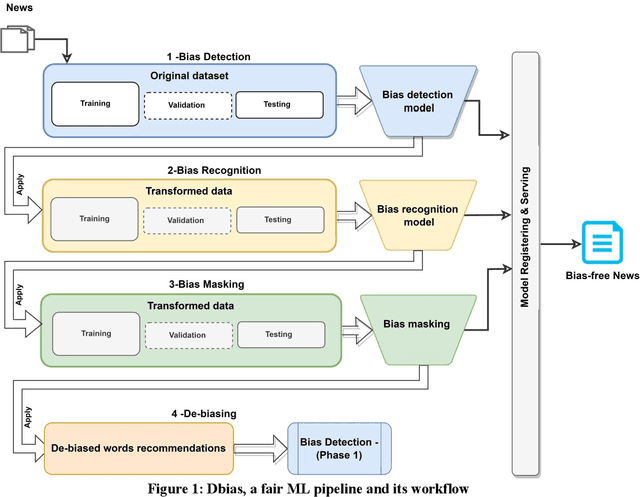
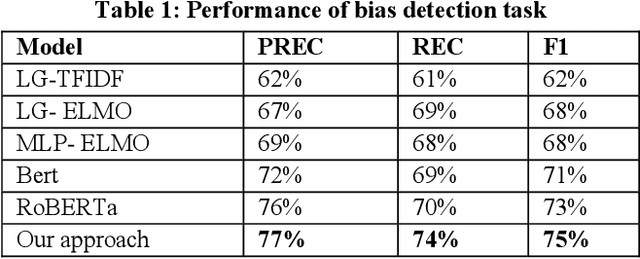
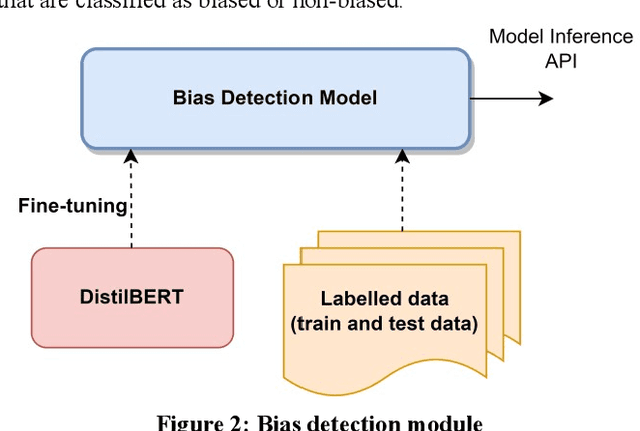
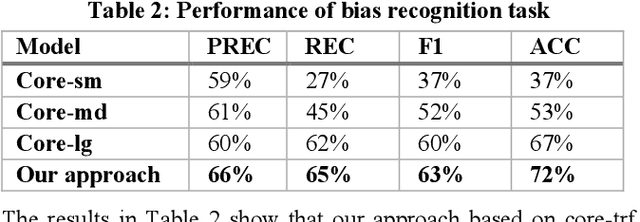
Recommender systems, information retrieval, and other information access systems present unique challenges for examining and applying concepts of fairness and bias mitigation in unstructured text. This paper introduces Dbias, which is a Python package to ensure fairness in news articles. Dbias is a trained Machine Learning (ML) pipeline that can take a text (e.g., a paragraph or news story) and detects if the text is biased or not. Then, it detects the biased words in the text, masks them, and recommends a set of sentences with new words that are bias-free or at least less biased. We incorporate the elements of data science best practices to ensure that this pipeline is reproducible and usable. We show in experiments that this pipeline can be effective for mitigating biases and outperforms the common neural network architectures in ensuring fairness in the news articles.
Improving Rating and Relevance with Point-of-Interest Recommender System
Feb 17, 2022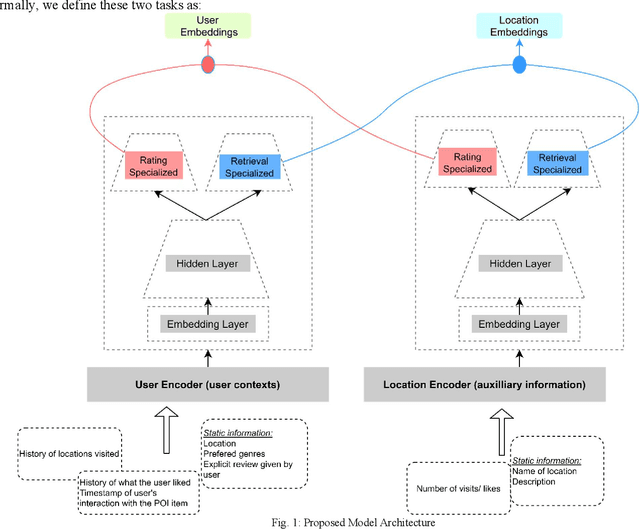
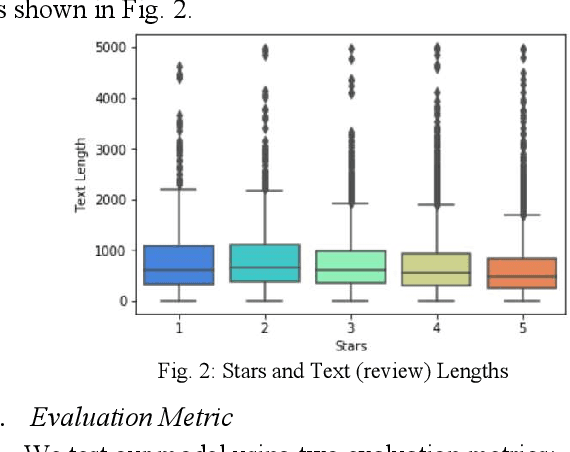
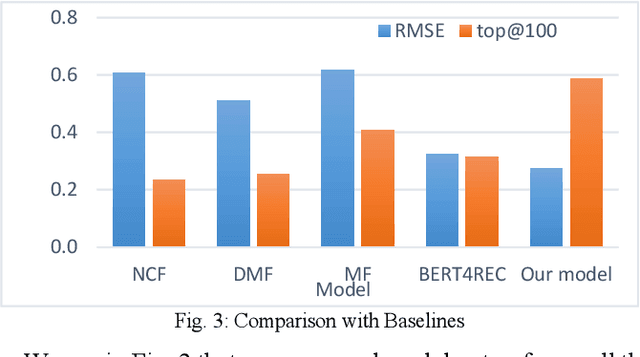
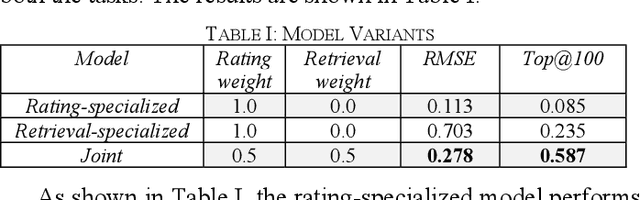
The recommendation of points of interest (POIs) is essential in location-based social networks. It makes it easier for users and locations to share information. Recently, researchers tend to recommend POIs by treating them as large-scale retrieval systems that require a large amount of training data representing query-item relevance. However, gathering user feedback in retrieval systems is an expensive task. Existing POI recommender systems make recommendations based on user and item (location) interactions solely. However, there are numerous sources of feedback to consider. For example, when the user visits a POI, what is the POI is about and such. Integrating all these different types of feedback is essential when developing a POI recommender. In this paper, we propose using user and item information and auxiliary information to improve the recommendation modelling in a retrieval system. We develop a deep neural network architecture to model query-item relevance in the presence of both collaborative and content information. We also improve the quality of the learned representations of queries and items by including the contextual information from the user feedback data. The application of these learned representations to a large-scale dataset resulted in significant improvements.
Detecting Fake Points of Interest from Location Data
Nov 11, 2021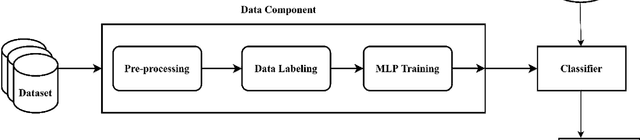
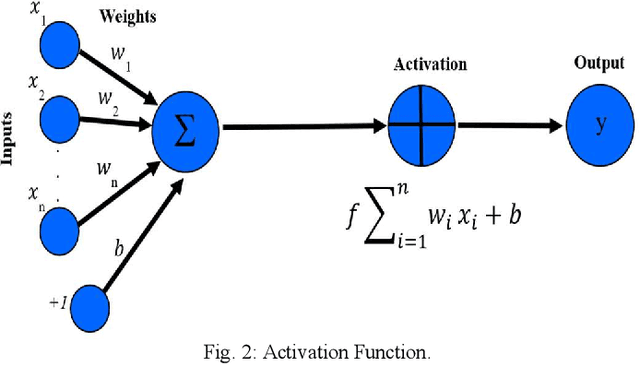
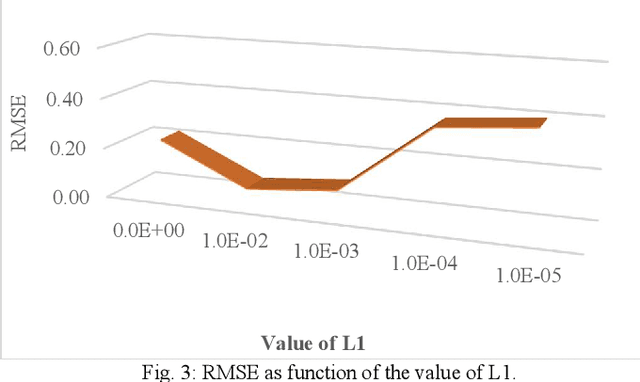
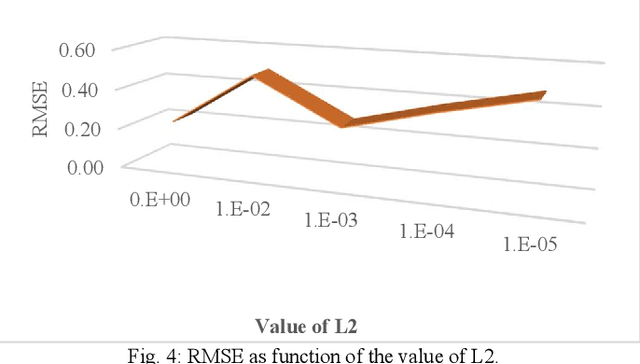
The pervasiveness of GPS-enabled mobile devices and the widespread use of location-based services have resulted in the generation of massive amounts of geo-tagged data. In recent times, the data analysis now has access to more sources, including reviews, news, and images, which also raises questions about the reliability of Point-of-Interest (POI) data sources. While previous research attempted to detect fake POI data through various security mechanisms, the current work attempts to capture the fake POI data in a much simpler way. The proposed work is focused on supervised learning methods and their capability to find hidden patterns in location-based data. The ground truth labels are obtained through real-world data, and the fake data is generated using an API, so we get a dataset with both the real and fake labels on the location data. The objective is to predict the truth about a POI using the Multi-Layer Perceptron (MLP) method. In the proposed work, MLP based on data classification technique is used to classify location data accurately. The proposed method is compared with traditional classification and robust and recent deep neural methods. The results show that the proposed method is better than the baseline methods.