 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Share: Selective Memory for Efficient Parallel Agentic Systems
Feb 05, 2026Agentic systems solve complex tasks by coordinating multiple agents that iteratively reason, invoke tools, and exchange intermediate results. To improve robustness and solution quality, recent approaches deploy multiple agent teams running in parallel to explore diverse reasoning trajectories. However, parallel execution comes at a significant computational cost: when different teams independently reason about similar sub-problems or execute analogous steps, they repeatedly perform substantial overlapping computation. To address these limitations, in this paper, we propose Learning to Share (LTS), a learned shared-memory mechanism for parallel agentic frameworks that enables selective cross-team information reuse while controlling context growth. LTS introduces a global memory bank accessible to all teams and a lightweight controller that decides whether intermediate agent steps should be added to memory or not. The controller is trained using stepwise reinforcement learning with usage-aware credit assignment, allowing it to identify information that is globally useful across parallel executions. Experiments on the AssistantBench and GAIA benchmarks show that LTS significantly reduces overall runtime while matching or improving task performance compared to memory-free parallel baselines, demonstrating that learned memory admission is an effective strategy for improving the efficiency of parallel agentic systems. Project page: https://joefioresi718.github.io/LTS_webpage/
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025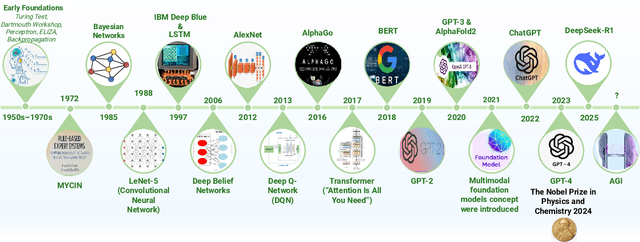
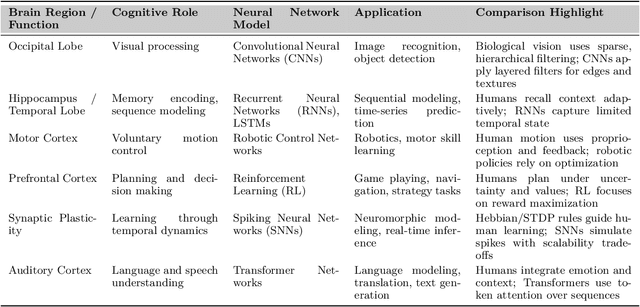
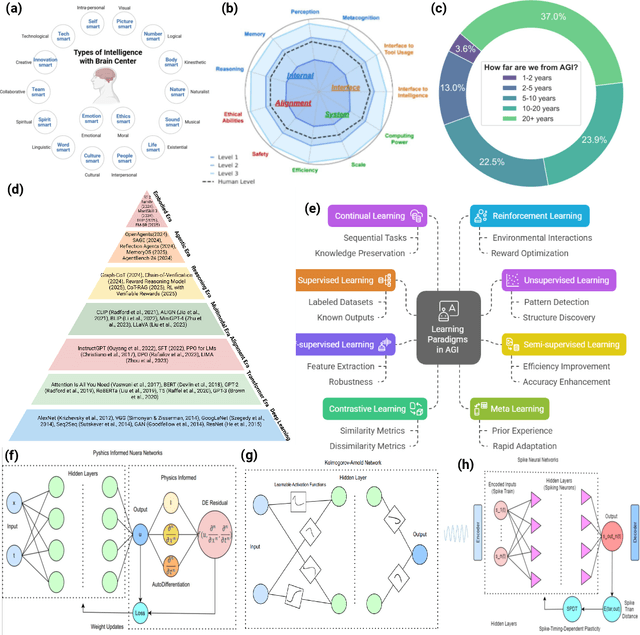
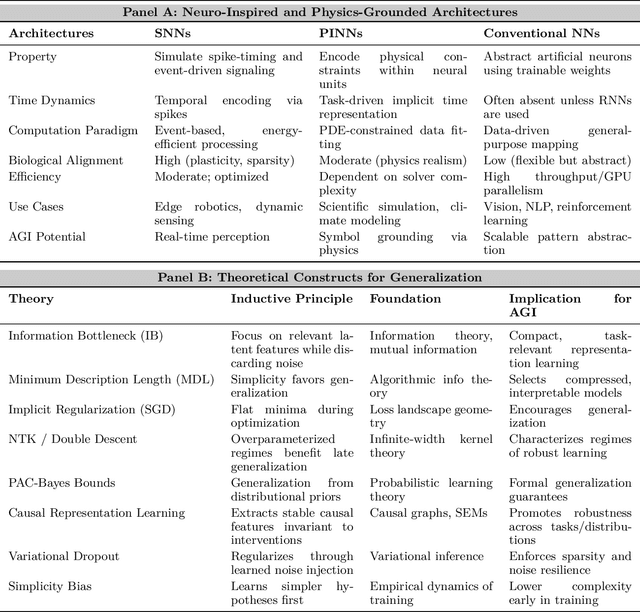
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
May 16, 2025



Large multimodal models (LMMs) now excel on many vision language benchmarks, however, they still struggle with human centered criteria such as fairness, ethics, empathy, and inclusivity, key to aligning with human values. We introduce HumaniBench, a holistic benchmark of 32K real-world image question pairs, annotated via a scalable GPT4o assisted pipeline and exhaustively verified by domain experts. HumaniBench evaluates seven Human Centered AI (HCAI) principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, across seven diverse tasks, including open and closed ended visual question answering (VQA), multilingual QA, visual grounding, empathetic captioning, and robustness tests. Benchmarking 15 state of the art LMMs (open and closed source) reveals that proprietary models generally lead, though robustness and visual grounding remain weak points. Some open-source models also struggle to balance accuracy with adherence to human-aligned principles. HumaniBench is the first benchmark purpose built around HCAI principles. It provides a rigorous testbed for diagnosing alignment gaps and guiding LMMs toward behavior that is both accurate and socially responsible. Dataset, annotation prompts, and evaluation code are available at: https://vectorinstitute.github.io/HumaniBench
GAEA: A Geolocation Aware Conversational Model
Mar 20, 2025



Image geolocalization, in which, traditionally, an AI model predicts the precise GPS coordinates of an image is a challenging task with many downstream applications. However, the user cannot utilize the model to further their knowledge other than the GPS coordinate; the model lacks an understanding of the location and the conversational ability to communicate with the user. In recent days, with tremendous progress of large multimodal models (LMMs) proprietary and open-source researchers have attempted to geolocalize images via LMMs. However, the issues remain unaddressed; beyond general tasks, for more specialized downstream tasks, one of which is geolocalization, LMMs struggle. In this work, we propose to solve this problem by introducing a conversational model GAEA that can provide information regarding the location of an image, as required by a user. No large-scale dataset enabling the training of such a model exists. Thus we propose a comprehensive dataset GAEA with 800K images and around 1.6M question answer pairs constructed by leveraging OpenStreetMap (OSM) attributes and geographical context clues. For quantitative evaluation, we propose a diverse benchmark comprising 4K image-text pairs to evaluate conversational capabilities equipped with diverse question types. We consider 11 state-of-the-art open-source and proprietary LMMs and demonstrate that GAEA significantly outperforms the best open-source model, LLaVA-OneVision by 25.69% and the best proprietary model, GPT-4o by 8.28%. Our dataset, model and codes are available
VLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.
SB-Bench: Stereotype Bias Benchmark for Large Multimodal Models
Feb 12, 2025



Stereotype biases in Large Multimodal Models (LMMs) perpetuate harmful societal prejudices, undermining the fairness and equity of AI applications. As LMMs grow increasingly influential, addressing and mitigating inherent biases related to stereotypes, harmful generations, and ambiguous assumptions in real-world scenarios has become essential. However, existing datasets evaluating stereotype biases in LMMs often lack diversity and rely on synthetic images, leaving a gap in bias evaluation for real-world visual contexts. To address this, we introduce the Stereotype Bias Benchmark (SB-bench), the most comprehensive framework to date for assessing stereotype biases across nine diverse categories with non-synthetic images. SB-bench rigorously evaluates LMMs through carefully curated, visually grounded scenarios, challenging them to reason accurately about visual stereotypes. It offers a robust evaluation framework featuring real-world visual samples, image variations, and multiple-choice question formats. By introducing visually grounded queries that isolate visual biases from textual ones, SB-bench enables a precise and nuanced assessment of a model's reasoning capabilities across varying levels of difficulty. Through rigorous testing of state-of-the-art open-source and closed-source LMMs, SB-bench provides a systematic approach to assessing stereotype biases in LMMs across key social dimensions. This benchmark represents a significant step toward fostering fairness in AI systems and reducing harmful biases, laying the groundwork for more equitable and socially responsible LMMs. Our code and dataset are publicly available.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
VURF: A General-purpose Reasoning and Self-refinement Framework for Video Understanding
Mar 25, 2024Recent studies have demonstrated the effectiveness of Large Language Models (LLMs) as reasoning modules that can deconstruct complex tasks into more manageable sub-tasks, particularly when applied to visual reasoning tasks for images. In contrast, this paper introduces a Video Understanding and Reasoning Framework (VURF) based on the reasoning power of LLMs. Ours is a novel approach to extend the utility of LLMs in the context of video tasks, leveraging their capacity to generalize from minimal input and output demonstrations within a contextual framework. By presenting LLMs with pairs of instructions and their corresponding high-level programs, we harness their contextual learning capabilities to generate executable visual programs for video understanding. To enhance program's accuracy and robustness, we implement two important strategies. Firstly, we employ a feedback-generation approach, powered by GPT-3.5, to rectify errors in programs utilizing unsupported functions. Secondly, taking motivation from recent works on self refinement of LLM outputs, we introduce an iterative procedure for improving the quality of the in-context examples by aligning the initial outputs to the outputs that would have been generated had the LLM not been bound by the structure of the in-context examples. Our results on several video-specific tasks, including visual QA, video anticipation, pose estimation and multi-video QA illustrate the efficacy of these enhancements in improving the performance of visual programming approaches for video tasks.
MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT
Feb 26, 2024



"Bigger the better" has been the predominant trend in recent Large Language Models (LLMs) development. However, LLMs do not suit well for scenarios that require on-device processing, energy efficiency, low memory footprint, and response efficiency. These requisites are crucial for privacy, security, and sustainable deployment. This paper explores the "less is more" paradigm by addressing the challenge of designing accurate yet efficient Small Language Models (SLMs) for resource constrained devices. Our primary contribution is the introduction of an accurate and fully transparent open-source 0.5 billion (0.5B) parameter SLM, named MobiLlama, catering to the specific needs of resource-constrained computing with an emphasis on enhanced performance with reduced resource demands. MobiLlama is a SLM design that initiates from a larger model and applies a careful parameter sharing scheme to reduce both the pre-training and the deployment cost. Our work strives to not only bridge the gap in open-source SLMs but also ensures full transparency, where complete training data pipeline, training code, model weights, and over 300 checkpoints along with evaluation codes is available at : https://github.com/mbzuai-oryx/MobiLlama.