 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Speech-Text Gap with Limited Audio for Effective Domain Adaptation in LLM-Based ASR
Apr 07, 2026Conventional end-to-end automatic speech recognition (ASR) systems rely on paired speech-text data for domain adaptation. Recent LLM-based ASR architectures connect a speech encoder to a large language model via a projection module, enabling adaptation with text-only data. However, this introduces a modality gap, as the LLM is not exposed to the noisy representations produced by the speech projector. We investigate whether small amounts of speech can mitigate this mismatch. We compare three strategies: text-only adaptation, paired speech-text adaptation, and mixed batching (MB), which combines both. Experiments in in-domain and out-of-domain settings show that even limited speech consistently improves performance. Notably, MB using only 10% of the target-domain (less than 4 hours) speech achieves word error rates comparable to, or better than, conventional ASR fine-tuning with the full dataset, indicating that small amounts of speech provide a strong modality-alignment signal.
Distilling Conversations: Abstract Compression of Conversational Audio Context for LLM-based ASR
Mar 27, 2026Standard LLM-based speech recognition systems typically process utterances in isolation, limiting their ability to leverage conversational context. In this work, we study whether multimodal context from prior turns improves LLM-based ASR and how to represent that context efficiently. We find that, after supervised multi-turn training, conversational context mainly helps with the recognition of contextual entities. However, conditioning on raw context is expensive because the prior-turn audio token sequence grows rapidly with conversation length. To address this, we propose Abstract Compression, which replaces the audio portion of prior turns with a fixed number of learned latent tokens while retaining corresponding transcripts explicitly. On both in-domain and out-of-domain test sets, the compressed model recovers part of the gains of raw-context conditioning with a smaller prior-turn audio footprint. We also provide targeted analyses of the compression setup and its trade-offs.
When Consistency Becomes Bias: Interviewer Effects in Semi-Structured Clinical Interviews
Mar 25, 2026Automatic depression detection from doctor-patient conversations has gained momentum thanks to the availability of public corpora and advances in language modeling. However, interpretability remains limited: strong performance is often reported without revealing what drives predictions. We analyze three datasets: ANDROIDS, DAIC-WOZ, E-DAIC and identify a systematic bias from interviewer prompts in semi-structured interviews. Models trained on interviewer turns exploit fixed prompts and positions to distinguish depressed from control subjects, often achieving high classification scores without using participant language. Restricting models to participant utterances distributes decision evidence more broadly and reflects genuine linguistic cues. While semi-structured protocols ensure consistency, including interviewer prompts inflates performance by leveraging script artifacts. Our results highlight a cross-dataset, architecture-agnostic bias and emphasize the need for analyses that localize decision evidence by time and speaker to ensure models learn from participants' language.
Uncertainty Awareness Enables Efficient Labeling for Cancer Subtyping in Digital Pathology
Jun 13, 2025



Machine-learning-assisted cancer subtyping is a promising avenue in digital pathology. Cancer subtyping models, however, require careful training using expert annotations so that they can be inferred with a degree of known certainty (or uncertainty). To this end, we introduce the concept of uncertainty awareness into a self-supervised contrastive learning model. This is achieved by computing an evidence vector at every epoch, which assesses the model's confidence in its predictions. The derived uncertainty score is then utilized as a metric to selectively label the most crucial images that require further annotation, thus iteratively refining the training process. With just 1-10% of strategically selected annotations, we attain state-of-the-art performance in cancer subtyping on benchmark datasets. Our method not only strategically guides the annotation process to minimize the need for extensive labeled datasets, but also improves the precision and efficiency of classifications. This development is particularly beneficial in settings where the availability of labeled data is limited, offering a promising direction for future research and application in digital pathology.
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
Hierarchical Text-to-Vision Self Supervised Alignment for Improved Histopathology Representation Learning
Mar 21, 2024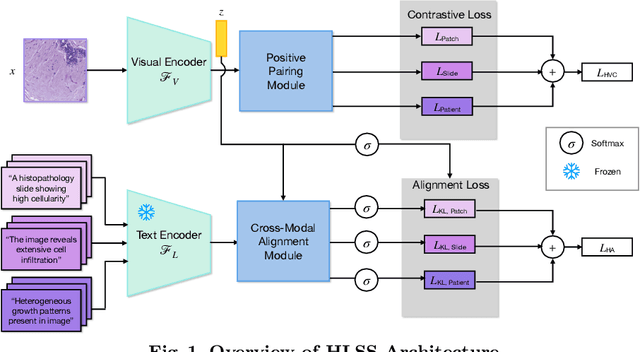
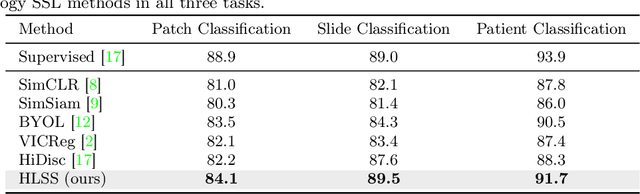
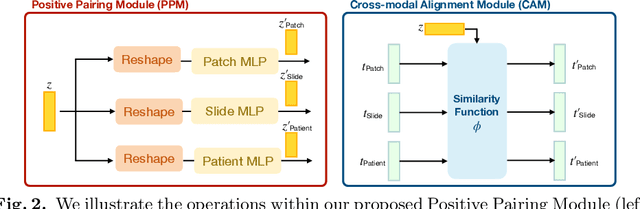
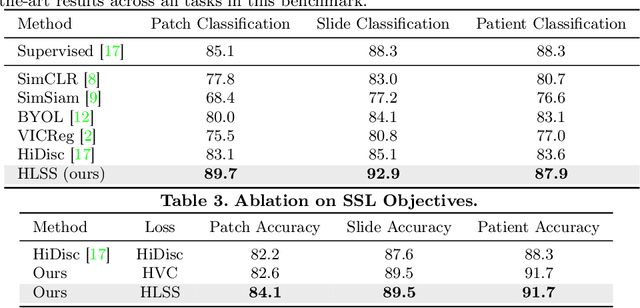
Self-supervised representation learning has been highly promising for histopathology image analysis with numerous approaches leveraging their patient-slide-patch hierarchy to learn better representations. In this paper, we explore how the combination of domain specific natural language information with such hierarchical visual representations can benefit rich representation learning for medical image tasks. Building on automated language description generation for features visible in histopathology images, we present a novel language-tied self-supervised learning framework, Hierarchical Language-tied Self-Supervision (HLSS) for histopathology images. We explore contrastive objectives and granular language description based text alignment at multiple hierarchies to inject language modality information into the visual representations. Our resulting model achieves state-of-the-art performance on two medical imaging benchmarks, OpenSRH and TCGA datasets. Our framework also provides better interpretability with our language aligned representation space. Code is available at https://github.com/Hasindri/HLSS.
Contrastive Deep Encoding Enables Uncertainty-aware Machine-learning-assisted Histopathology
Sep 13, 2023



Deep neural network models can learn clinically relevant features from millions of histopathology images. However generating high-quality annotations to train such models for each hospital, each cancer type, and each diagnostic task is prohibitively laborious. On the other hand, terabytes of training data -- while lacking reliable annotations -- are readily available in the public domain in some cases. In this work, we explore how these large datasets can be consciously utilized to pre-train deep networks to encode informative representations. We then fine-tune our pre-trained models on a fraction of annotated training data to perform specific downstream tasks. We show that our approach can reach the state-of-the-art (SOTA) for patch-level classification with only 1-10% randomly selected annotations compared to other SOTA approaches. Moreover, we propose an uncertainty-aware loss function, to quantify the model confidence during inference. Quantified uncertainty helps experts select the best instances to label for further training. Our uncertainty-aware labeling reaches the SOTA with significantly fewer annotations compared to random labeling. Last, we demonstrate how our pre-trained encoders can surpass current SOTA for whole-slide image classification with weak supervision. Our work lays the foundation for data and task-agnostic pre-trained deep networks with quantified uncertainty.