 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Jun 05, 2025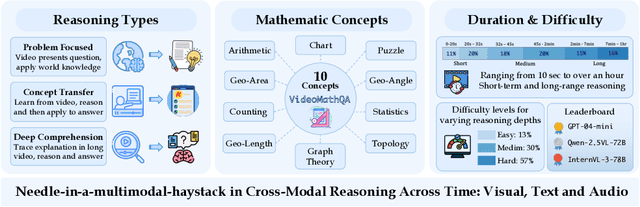
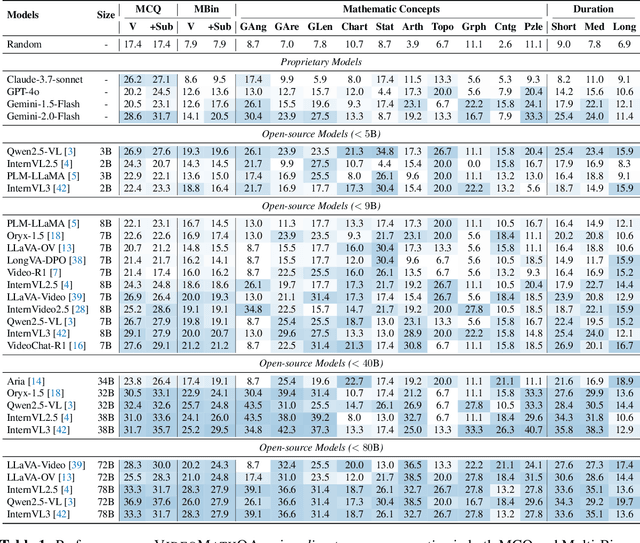

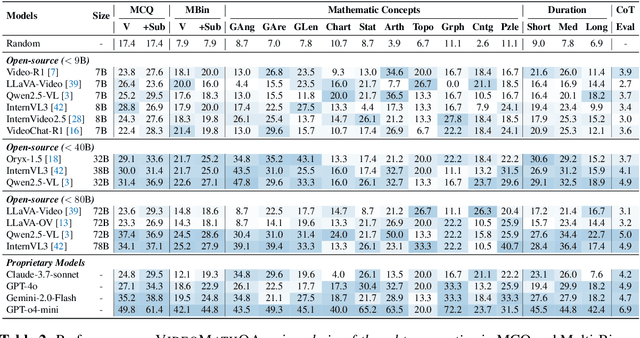
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
Mobile-VideoGPT: Fast and Accurate Video Understanding Language Model
Mar 27, 2025Video understanding models often struggle with high computational requirements, extensive parameter counts, and slow inference speed, making them inefficient for practical use. To tackle these challenges, we propose Mobile-VideoGPT, an efficient multimodal framework designed to operate with fewer than a billion parameters. Unlike traditional video large multimodal models (LMMs), Mobile-VideoGPT consists of lightweight dual visual encoders, efficient projectors, and a small language model (SLM), enabling real-time throughput. To further improve efficiency, we present an Attention-Based Frame Scoring mechanism to select the key-frames, along with an efficient token projector that prunes redundant visual tokens and preserves essential contextual cues. We evaluate our model across well-established six video understanding benchmarks (e.g., MVBench, EgoSchema, NextQA, and PercepTest). Our results show that Mobile-VideoGPT-0.5B can generate up to 46 tokens per second while outperforming existing state-of-the-art 0.5B-parameter models by 6 points on average with 40% fewer parameters and more than 2x higher throughput. Our code and models are publicly available at: https://github.com/Amshaker/Mobile-VideoGPT.
Formal Verification of Markov Processes with Learned Parameters
Jan 27, 2025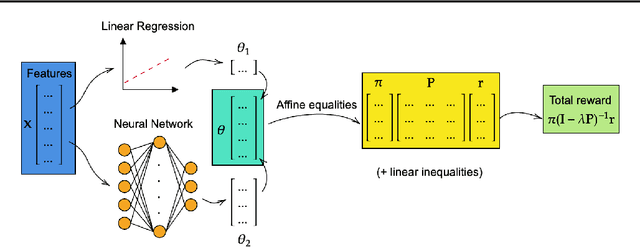
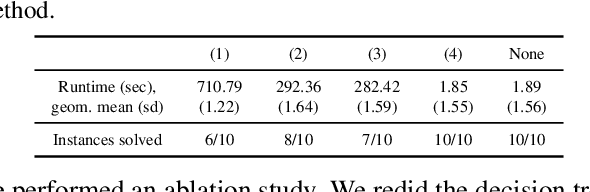
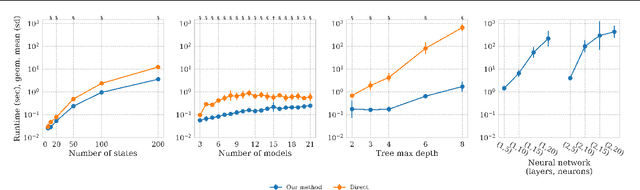
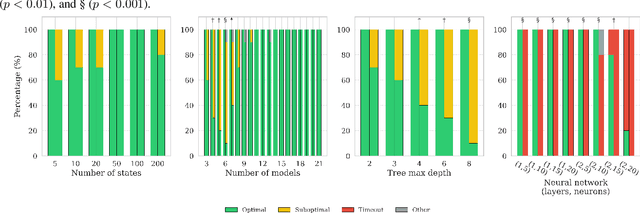
We introduce the problem of formally verifying properties of Markov processes where the parameters are the output of machine learning models. Our formulation is general and solves a wide range of problems, including verifying properties of probabilistic programs that use machine learning, and subgroup analysis in healthcare modeling. We show that for a broad class of machine learning models, including linear models, tree-based models, and neural networks, verifying properties of Markov chains like reachability, hitting time, and total reward can be formulated as a bilinear program. We develop a decomposition and bound propagation scheme for solving the bilinear program and show through computational experiments that our method solves the problem to global optimality up to 100x faster than state-of-the-art solvers. We also release $\texttt{markovml}$, an open-source tool for building Markov processes, integrating pretrained machine learning models, and verifying their properties, available at https://github.com/mmaaz-git/markovml.
VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Jun 13, 2024



Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
PALO: A Polyglot Large Multimodal Model for 5B People
Mar 05, 2024



In pursuit of more inclusive Vision-Language Models (VLMs), this study introduces a Large Multilingual Multimodal Model called PALO. PALO offers visual reasoning capabilities in 10 major languages, including English, Chinese, Hindi, Spanish, French, Arabic, Bengali, Russian, Urdu, and Japanese, that span a total of ~5B people (65% of the world population). Our approach involves a semi-automated translation approach to adapt the multimodal instruction dataset from English to the target languages using a fine-tuned Large Language Model, thereby ensuring high linguistic fidelity while allowing scalability due to minimal manual effort. The incorporation of diverse instruction sets helps us boost overall performance across multiple languages especially those that are underrepresented like Hindi, Arabic, Bengali, and Urdu. The resulting models are trained across three scales (1.7B, 7B and 13B parameters) to show the generalization and scalability where we observe substantial improvements compared to strong baselines. We also propose the first multilingual multimodal benchmark for the forthcoming approaches to evaluate their vision-language reasoning capabilities across languages. Code: https://github.com/mbzuai-oryx/PALO.
PG-Video-LLaVA: Pixel Grounding Large Video-Language Models
Nov 22, 2023Extending image-based Large Multimodal Models (LMM) to videos is challenging due to the inherent complexity of video data. The recent approaches extending image-based LMM to videos either lack the grounding capabilities (e.g., VideoChat, Video-ChatGPT, Video-LLaMA) or do not utilize the audio-signals for better video understanding (e.g., Video-ChatGPT). Addressing these gaps, we propose Video-LLaVA, the first LMM with pixel-level grounding capability, integrating audio cues by transcribing them into text to enrich video-context understanding. Our framework uses an off-the-shelf tracker and a novel grounding module, enabling it to spatially and temporally localize objects in videos following user instructions. We evaluate Video-LLaVA using video-based generative and question-answering benchmarks and introduce new benchmarks specifically designed to measure prompt-based object grounding performance in videos. Further, we propose the use of Vicuna over GPT-3.5, as utilized in Video-ChatGPT, for video-based conversation benchmarking, ensuring reproducibility of results which is a concern with the proprietary nature of GPT-3.5. Our framework builds on SoTA image-based LLaVA model and extends its advantages to the video domain, delivering promising gains on video-based conversation and grounding tasks. Project Page: https://github.com/mbzuai-oryx/Video-LLaVA
GLaMM: Pixel Grounding Large Multimodal Model
Nov 06, 2023



Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial efforts towards LMMs used holistic images and text prompts to generate ungrounded textual responses. Very recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring a single object category at a time, require users to specify the regions in inputs, or cannot offer dense pixel-wise object grounding. In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input. This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of generating visually grounded detailed conversations, we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed Grounded Conversation Generation (GCG) task requires densely grounded concepts in natural scenes at a large-scale. To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks e.g., referring expression segmentation, image and region-level captioning and vision-language conversations. Project Page: https://mbzuai-oryx.github.io/groundingLMM.
On Orderings of Probability Vectors and Unsupervised Performance Estimation
Jun 16, 2023



Unsupervised performance estimation, or evaluating how well models perform on unlabeled data is a difficult task. Recently, a method was proposed by Garg et al. [2022] which performs much better than previous methods. Their method relies on having a score function, satisfying certain properties, to map probability vectors outputted by the classifier to the reals, but it is an open problem which score function is best. We explore this problem by first showing that their method fundamentally relies on the ordering induced by this score function. Thus, under monotone transformations of score functions, their method yields the same estimate. Next, we show that in the binary classification setting, nearly all common score functions - the $L^\infty$ norm; the $L^2$ norm; negative entropy; and the $L^2$, $L^1$, and Jensen-Shannon distances to the uniform vector - all induce the same ordering over probability vectors. However, this does not hold for higher dimensional settings. We conduct numerous experiments on well-known NLP data sets and rigorously explore the performance of different score functions. We conclude that the $L^\infty$ norm is the most appropriate.