 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Problem Generation via Symbolic Representations
Feb 22, 2026We present a method for generating training data for reinforcement learning with verifiable rewards to improve small open-weights language models on mathematical tasks. Existing data generation approaches rely on open-loop pipelines and fixed modifications that do not adapt to the model's capabilities. Furthermore, they typically operate directly on word problems, limiting control over problem structure. To address this, we perform modifications in a symbolic problem space, representing each problem as a set of symbolic variables and constraints (e.g., via algebraic frameworks such as SymPy or SMT formulations). This representation enables precise control over problem structure, automatic generation of ground-truth solutions, and decouples mathematical reasoning from linguistic realization. We also show that this results in more diverse generations. To adapt the problem difficulty to the model, we introduce a closed-loop framework that learns modification strategies through prompt optimization in symbolic space. Experimental results demonstrate that both adaptive problem generation and symbolic representation modifications contribute to improving the model's math solving ability.
Uncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
ReasonIR: Training Retrievers for Reasoning Tasks
Apr 29, 2025We present ReasonIR-8B, the first retriever specifically trained for general reasoning tasks. Existing retrievers have shown limited gains on reasoning tasks, in part because existing training datasets focus on short factual queries tied to documents that straightforwardly answer them. We develop a synthetic data generation pipeline that, for each document, our pipeline creates a challenging and relevant query, along with a plausibly related but ultimately unhelpful hard negative. By training on a mixture of our synthetic data and existing public data, ReasonIR-8B achieves a new state-of-the-art of 29.9 nDCG@10 without reranker and 36.9 nDCG@10 with reranker on BRIGHT, a widely-used reasoning-intensive information retrieval (IR) benchmark. When applied to RAG tasks, ReasonIR-8B improves MMLU and GPQA performance by 6.4% and 22.6% respectively, relative to the closed-book baseline, outperforming other retrievers and search engines. In addition, ReasonIR-8B uses test-time compute more effectively: on BRIGHT, its performance consistently increases with longer and more information-rich rewritten queries; it continues to outperform other retrievers when combined with an LLM reranker. Our training recipe is general and can be easily extended to future LLMs; to this end, we open-source our code, data, and model.
Group-robust Sample Reweighting for Subpopulation Shifts via Influence Functions
Mar 10, 2025



Machine learning models often have uneven performance among subpopulations (a.k.a., groups) in the data distributions. This poses a significant challenge for the models to generalize when the proportions of the groups shift during deployment. To improve robustness to such shifts, existing approaches have developed strategies that train models or perform hyperparameter tuning using the group-labeled data to minimize the worst-case loss over groups. However, a non-trivial amount of high-quality labels is often required to obtain noticeable improvements. Given the costliness of the labels, we propose to adopt a different paradigm to enhance group label efficiency: utilizing the group-labeled data as a target set to optimize the weights of other group-unlabeled data. We introduce Group-robust Sample Reweighting (GSR), a two-stage approach that first learns the representations from group-unlabeled data, and then tinkers the model by iteratively retraining its last layer on the reweighted data using influence functions. Our GSR is theoretically sound, practically lightweight, and effective in improving the robustness to subpopulation shifts. In particular, GSR outperforms the previous state-of-the-art approaches that require the same amount or even more group labels.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024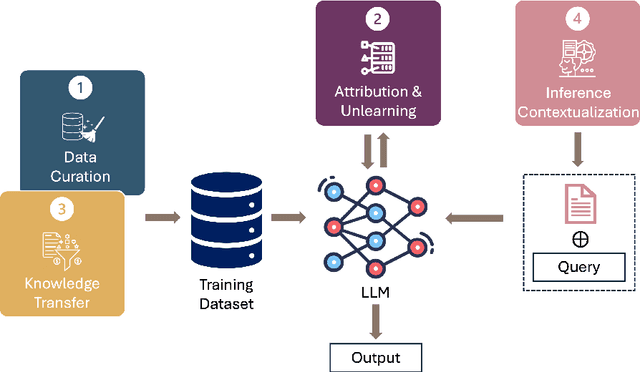
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Helpful or Harmful Data? Fine-tuning-free Shapley Attribution for Explaining Language Model Predictions
Jun 07, 2024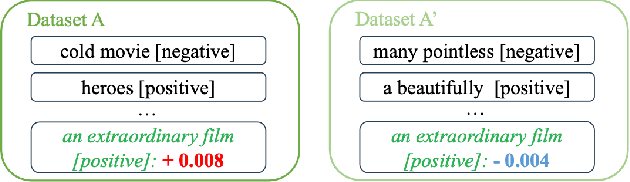
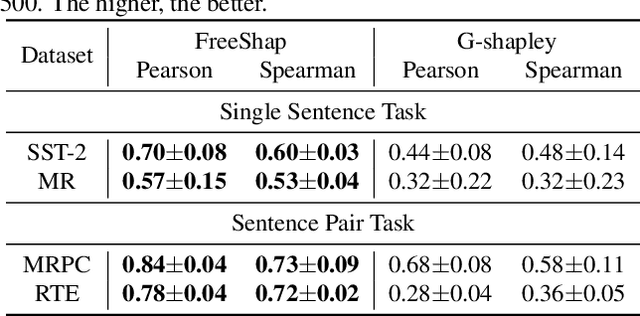
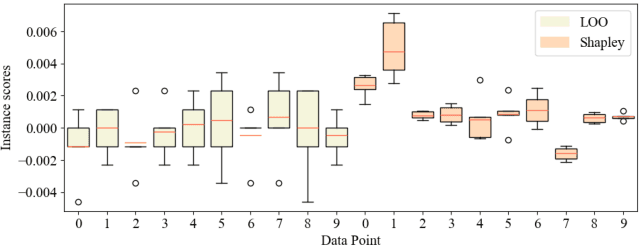

The increasing complexity of foundational models underscores the necessity for explainability, particularly for fine-tuning, the most widely used training method for adapting models to downstream tasks. Instance attribution, one type of explanation, attributes the model prediction to each training example by an instance score. However, the robustness of instance scores, specifically towards dataset resampling, has been overlooked. To bridge this gap, we propose a notion of robustness on the sign of the instance score. We theoretically and empirically demonstrate that the popular leave-one-out-based methods lack robustness, while the Shapley value behaves significantly better, but at a higher computational cost. Accordingly, we introduce an efficient fine-tuning-free approximation of the Shapley value (FreeShap) for instance attribution based on the neural tangent kernel. We empirically demonstrate that FreeShap outperforms other methods for instance attribution and other data-centric applications such as data removal, data selection, and wrong label detection, and further generalize our scale to large language models (LLMs). Our code is available at https://github.com/JTWang2000/FreeShap.
Cross-Domain Feature Augmentation for Domain Generalization
May 14, 2024



Domain generalization aims to develop models that are robust to distribution shifts. Existing methods focus on learning invariance across domains to enhance model robustness, and data augmentation has been widely used to learn invariant predictors, with most methods performing augmentation in the input space. However, augmentation in the input space has limited diversity whereas in the feature space is more versatile and has shown promising results. Nonetheless, feature semantics is seldom considered and existing feature augmentation methods suffer from a limited variety of augmented features. We decompose features into class-generic, class-specific, domain-generic, and domain-specific components. We propose a cross-domain feature augmentation method named XDomainMix that enables us to increase sample diversity while emphasizing the learning of invariant representations to achieve domain generalization. Experiments on widely used benchmark datasets demonstrate that our proposed method is able to achieve state-of-the-art performance. Quantitative analysis indicates that our feature augmentation approach facilitates the learning of effective models that are invariant across different domains.
Understanding Domain Generalization: A Noise Robustness Perspective
Jan 26, 2024Despite the rapid development of machine learning algorithms for domain generalization (DG), there is no clear empirical evidence that the existing DG algorithms outperform the classic empirical risk minimization (ERM) across standard benchmarks. To better understand this phenomenon, we investigate whether there are benefits of DG algorithms over ERM through the lens of label noise. Specifically, our finite-sample analysis reveals that label noise exacerbates the effect of spurious correlations for ERM, undermining generalization. Conversely, we illustrate that DG algorithms exhibit implicit label-noise robustness during finite-sample training even when spurious correlation is present. Such desirable property helps mitigate spurious correlations and improve generalization in synthetic experiments. However, additional comprehensive experiments on real-world benchmark datasets indicate that label-noise robustness does not necessarily translate to better performance compared to ERM. We conjecture that the failure mode of ERM arising from spurious correlations may be less pronounced in practice.
On Orderings of Probability Vectors and Unsupervised Performance Estimation
Jun 16, 2023



Unsupervised performance estimation, or evaluating how well models perform on unlabeled data is a difficult task. Recently, a method was proposed by Garg et al. [2022] which performs much better than previous methods. Their method relies on having a score function, satisfying certain properties, to map probability vectors outputted by the classifier to the reals, but it is an open problem which score function is best. We explore this problem by first showing that their method fundamentally relies on the ordering induced by this score function. Thus, under monotone transformations of score functions, their method yields the same estimate. Next, we show that in the binary classification setting, nearly all common score functions - the $L^\infty$ norm; the $L^2$ norm; negative entropy; and the $L^2$, $L^1$, and Jensen-Shannon distances to the uniform vector - all induce the same ordering over probability vectors. However, this does not hold for higher dimensional settings. We conduct numerous experiments on well-known NLP data sets and rigorously explore the performance of different score functions. We conclude that the $L^\infty$ norm is the most appropriate.
Uncovering Main Causalities for Long-tailed Information Extraction
Sep 11, 2021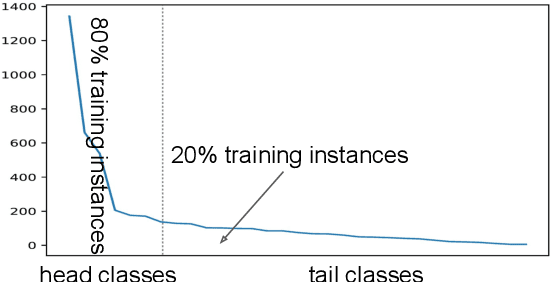
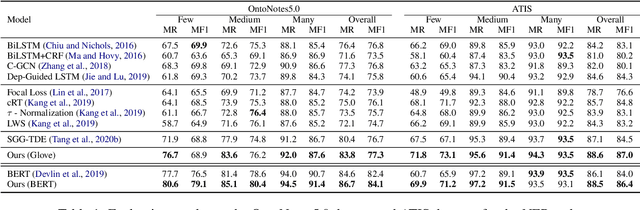
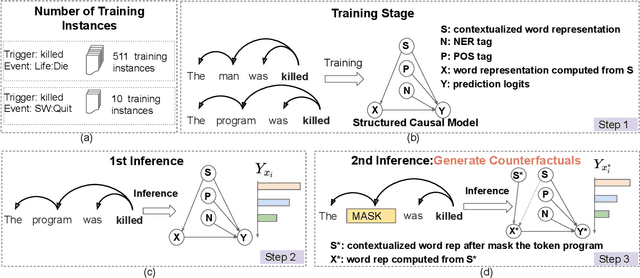
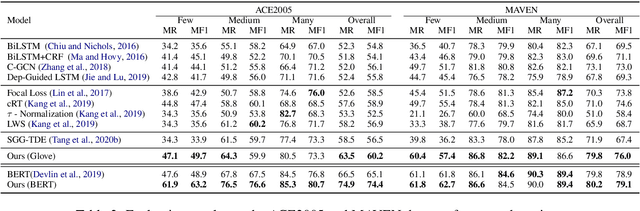
Information Extraction (IE) aims to extract structural information from unstructured texts. In practice, long-tailed distributions caused by the selection bias of a dataset, may lead to incorrect correlations, also known as spurious correlations, between entities and labels in the conventional likelihood models. This motivates us to propose counterfactual IE (CFIE), a novel framework that aims to uncover the main causalities behind data in the view of causal inference. Specifically, 1) we first introduce a unified structural causal model (SCM) for various IE tasks, describing the relationships among variables; 2) with our SCM, we then generate counterfactuals based on an explicit language structure to better calculate the direct causal effect during the inference stage; 3) we further propose a novel debiasing approach to yield more robust predictions. Experiments on three IE tasks across five public datasets show the effectiveness of our CFIE model in mitigating the spurious correlation issues.