 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeW&D:Scaling Parallel Tool Calling for Efficient Deep Research Agents
Feb 07, 2026Deep research agents have emerged as powerful tools for automating complex intellectual tasks through multi-step reasoning and web-based information seeking. While recent efforts have successfully enhanced these agents by scaling depth through increasing the number of sequential thinking and tool calls, the potential of scaling width via parallel tool calling remains largely unexplored. In this work, we propose the Wide and Deep research agent, a framework designed to investigate the behavior and performance of agents when scaling not only depth but also width via parallel tool calling. Unlike existing approaches that rely on complex multi-agent orchestration to parallelize workloads, our method leverages intrinsic parallel tool calling to facilitate effective coordination within a single reasoning step. We demonstrate that scaling width significantly improves performance on deep research benchmarks while reducing the number of turns required to obtain correct answers. Furthermore, we analyze the factors driving these improvements through case studies and explore various tool call schedulers to optimize parallel tool calling strategy. Our findings suggest that optimizing the trade-off between width and depth is a critical pathway toward high-efficiency deep research agents. Notably, without context management or other tricks, we obtain 62.2% accuracy with GPT-5-Medium on BrowseComp, surpassing the original 54.9% reported by GPT-5-High.
Uncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
ActiveDPO: Active Direct Preference Optimization for Sample-Efficient Alignment
May 25, 2025
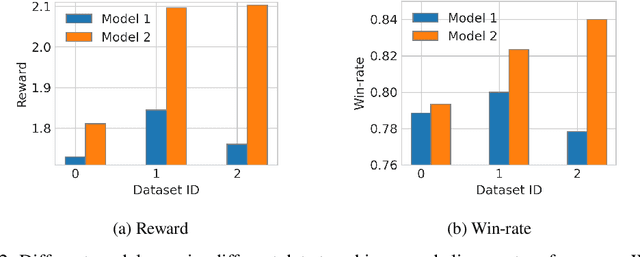

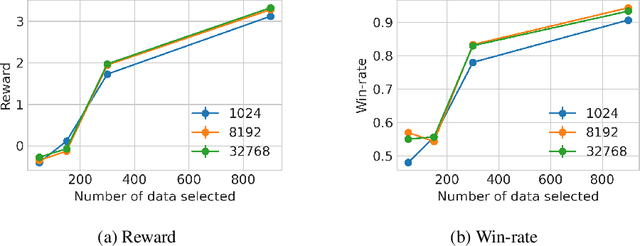
The recent success of using human preferences to align large language models (LLMs) has significantly improved their performance in various downstream tasks like question answering, mathematical reasoning, and code generation. However,3 achieving effective LLM alignment depends on high-quality human preference datasets. Collecting these datasets requires human preference annotation, which is costly and resource-intensive, necessitating efficient active data selection methods. Existing methods either lack a strong theoretical foundation or depend on restrictive reward function assumptions (e.g., linearity). To this end, we propose an algorithm, ActiveDPO, that uses a theoretically grounded data selection criterion for non-linear reward functions while directly leveraging the LLM itself to parameterize the reward model that is used for active data selection. As a result, ActiveDPO explicitly accounts for the influence of LLM on data selection, unlike methods that select the data without considering the LLM that is being aligned, thereby leading to more effective and efficient data collection. Extensive experiments show that ActiveDPO outperforms existing methods across various models and datasets.
Active Human Feedback Collection via Neural Contextual Dueling Bandits
Apr 16, 2025Collecting human preference feedback is often expensive, leading recent works to develop principled algorithms to select them more efficiently. However, these works assume that the underlying reward function is linear, an assumption that does not hold in many real-life applications, such as online recommendation and LLM alignment. To address this limitation, we propose Neural-ADB, an algorithm based on the neural contextual dueling bandit framework that provides a principled and practical method for collecting human preference feedback when the underlying latent reward function is non-linear. We theoretically show that when preference feedback follows the Bradley-Terry-Luce model, the worst sub-optimality gap of the policy learned by Neural-ADB decreases at a sub-linear rate as the preference dataset increases. Our experimental results on problem instances derived from synthetic preference datasets further validate the effectiveness of Neural-ADB.
Neural Dueling Bandits
Jul 24, 2024Contextual dueling bandit is used to model the bandit problems, where a learner's goal is to find the best arm for a given context using observed noisy preference feedback over the selected arms for the past contexts. However, existing algorithms assume the reward function is linear, which can be complex and non-linear in many real-life applications like online recommendations or ranking web search results. To overcome this challenge, we use a neural network to estimate the reward function using preference feedback for the previously selected arms. We propose upper confidence bound- and Thompson sampling-based algorithms with sub-linear regret guarantees that efficiently select arms in each round. We then extend our theoretical results to contextual bandit problems with binary feedback, which is in itself a non-trivial contribution. Experimental results on the problem instances derived from synthetic datasets corroborate our theoretical results.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024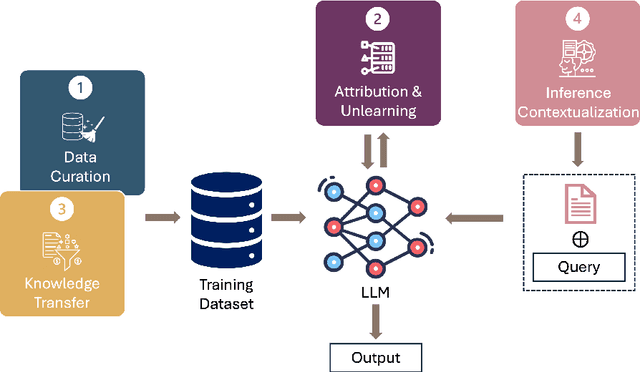
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Helpful or Harmful Data? Fine-tuning-free Shapley Attribution for Explaining Language Model Predictions
Jun 07, 2024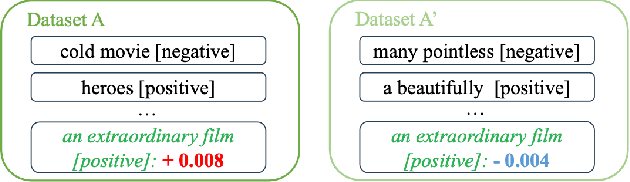
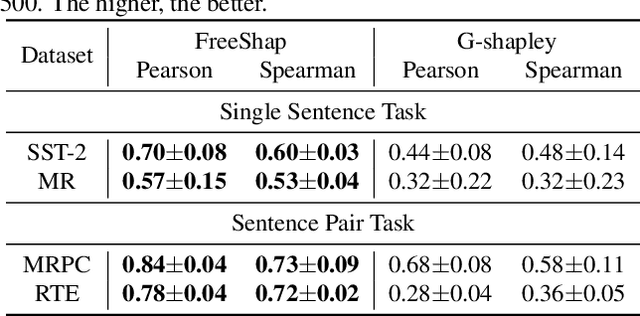
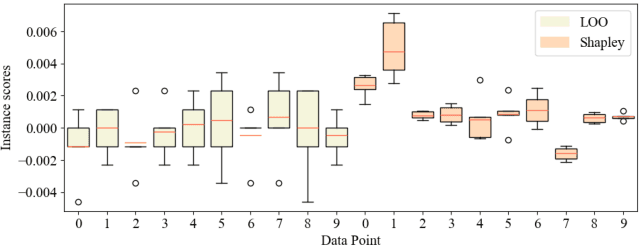

The increasing complexity of foundational models underscores the necessity for explainability, particularly for fine-tuning, the most widely used training method for adapting models to downstream tasks. Instance attribution, one type of explanation, attributes the model prediction to each training example by an instance score. However, the robustness of instance scores, specifically towards dataset resampling, has been overlooked. To bridge this gap, we propose a notion of robustness on the sign of the instance score. We theoretically and empirically demonstrate that the popular leave-one-out-based methods lack robustness, while the Shapley value behaves significantly better, but at a higher computational cost. Accordingly, we introduce an efficient fine-tuning-free approximation of the Shapley value (FreeShap) for instance attribution based on the neural tangent kernel. We empirically demonstrate that FreeShap outperforms other methods for instance attribution and other data-centric applications such as data removal, data selection, and wrong label detection, and further generalize our scale to large language models (LLMs). Our code is available at https://github.com/JTWang2000/FreeShap.
Prompt Optimization with Human Feedback
May 27, 2024



Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at \url{https://github.com/xqlin98/APOHF}.
Prompt Optimization with EASE? Efficient Ordering-aware Automated Selection of Exemplars
May 25, 2024



Large language models (LLMs) have shown impressive capabilities in real-world applications. The capability of in-context learning (ICL) allows us to adapt an LLM to downstream tasks by including input-label exemplars in the prompt without model fine-tuning. However, the quality of these exemplars in the prompt greatly impacts performance, highlighting the need for an effective automated exemplar selection method. Recent studies have explored retrieval-based approaches to select exemplars tailored to individual test queries, which can be undesirable due to extra test-time computation and an increased risk of data exposure. Moreover, existing methods fail to adequately account for the impact of exemplar ordering on the performance. On the other hand, the impact of the instruction, another essential component in the prompt given to the LLM, is often overlooked in existing exemplar selection methods. To address these challenges, we propose a novel method named EASE, which leverages the hidden embedding from a pre-trained language model to represent ordered sets of exemplars and uses a neural bandit algorithm to optimize the sets of exemplars while accounting for exemplar ordering. Our EASE can efficiently find an ordered set of exemplars that performs well for all test queries from a given task, thereby eliminating test-time computation. Importantly, EASE can be readily extended to jointly optimize both the exemplars and the instruction. Through extensive empirical evaluations (including novel tasks), we demonstrate the superiority of EASE over existing methods, and reveal practical insights about the impact of exemplar selection on ICL, which may be of independent interest. Our code is available at https://github.com/ZhaoxuanWu/EASE-Prompt-Optimization.
DETAIL: Task DEmonsTration Attribution for Interpretable In-context Learning
May 22, 2024In-context learning (ICL) allows transformer-based language models that are pre-trained on general text to quickly learn a specific task with a few "task demonstrations" without updating their parameters, significantly boosting their flexibility and generality. ICL possesses many distinct characteristics from conventional machine learning, thereby requiring new approaches to interpret this learning paradigm. Taking the viewpoint of recent works showing that transformers learn in context by formulating an internal optimizer, we propose an influence function-based attribution technique, DETAIL, that addresses the specific characteristics of ICL. We empirically verify the effectiveness of our approach for demonstration attribution while being computationally efficient. Leveraging the results, we then show how DETAIL can help improve model performance in real-world scenarios through demonstration reordering and curation. Finally, we experimentally prove the wide applicability of DETAIL by showing our attribution scores obtained on white-box models are transferable to black-box models in improving model performance.