 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
Dipper: Diversity in Prompts for Producing Large Language Model Ensembles in Reasoning tasks
Dec 12, 2024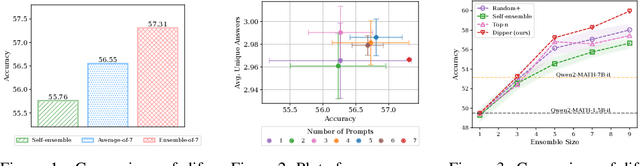



Large Language Models still encounter substantial challenges in reasoning tasks, especially for smaller models, which many users may be restricted to due to resource constraints (e.g. GPU memory restrictions). Inference-time methods to boost LLM performance, such as prompting methods to invoke certain reasoning pathways in responses, have been shown effective in past works, though they largely rely on sequential queries. The ensemble method, which consists of multiple constituent models running in parallel, is a promising approach to achieving better inference-time performance, especially given recent developments that enabled significant speed-ups in LLM batch inference. In this work, we propose a novel, training-free LLM ensemble framework where a single LLM model is fed an optimized, diverse set of prompts in parallel, effectively producing an ensemble at inference time to achieve performance improvement in reasoning tasks. We empirically demonstrate that our method leads to significant gains on math reasoning tasks, e.g., on MATH, where our ensemble consisting of a few small models (e.g., three Qwen2-MATH-1.5B-it models) can outperform a larger model (e.g., Qwen2-MATH-7B-it).
Ferret: Federated Full-Parameter Tuning at Scale for Large Language Models
Sep 11, 2024


Large Language Models (LLMs) have become indispensable in numerous real-world applications. Unfortunately, fine-tuning these models at scale, especially in federated settings where data privacy and communication efficiency are critical, presents significant challenges. Existing methods often resort to parameter-efficient fine-tuning (PEFT) to mitigate communication overhead, but this typically comes at the cost of model accuracy. To address these limitations, we propose federated full-parameter tuning at scale for LLMs (Ferret), the first first-order method with shared randomness to enable scalable full-parameter tuning of LLMs across decentralized data sources while maintaining competitive model accuracy. Ferret accomplishes this through three aspects: (1) it employs widely applied first-order methods for efficient local updates; (2) it projects these updates into a low-dimensional space to considerably reduce communication overhead; and (3) it reconstructs local updates from this low-dimensional space with shared randomness to facilitate effective full-parameter global aggregation, ensuring fast convergence and competitive final performance. Our rigorous theoretical analyses and insights along with extensive experiments, show that Ferret significantly enhances the scalability of existing federated full-parameter tuning approaches by achieving high computational efficiency, reduced communication overhead, and fast convergence, all while maintaining competitive model accuracy. Our implementation is available at https://github.com/allen4747/Ferret.
Classifier-Free Diffusion-Based Weakly-Supervised Approach for Health Indicator Derivation in Rotating Machines: Advancing Early Fault Detection and Condition Monitoring
Sep 03, 2024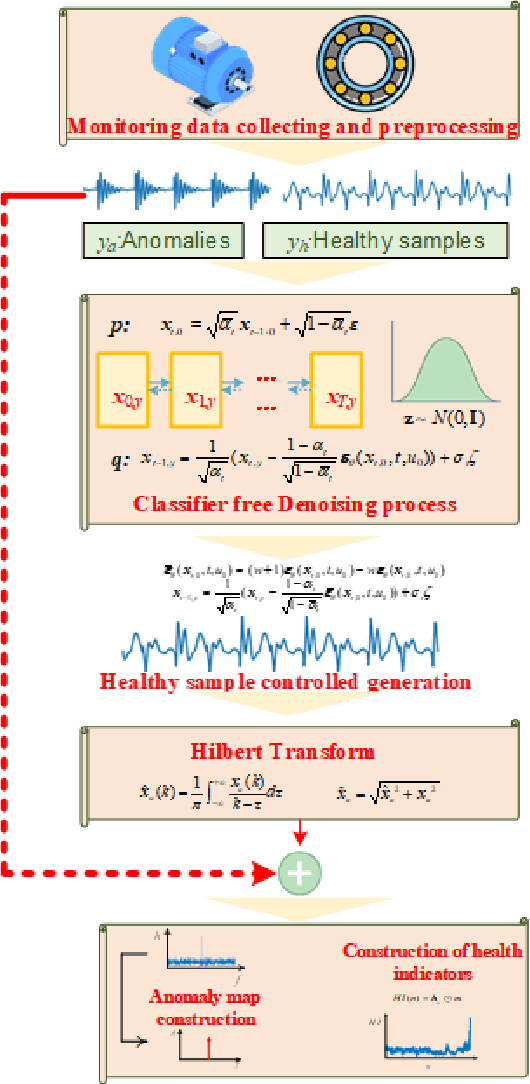

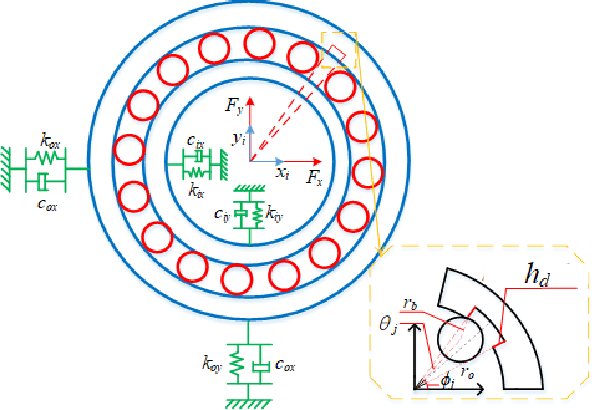
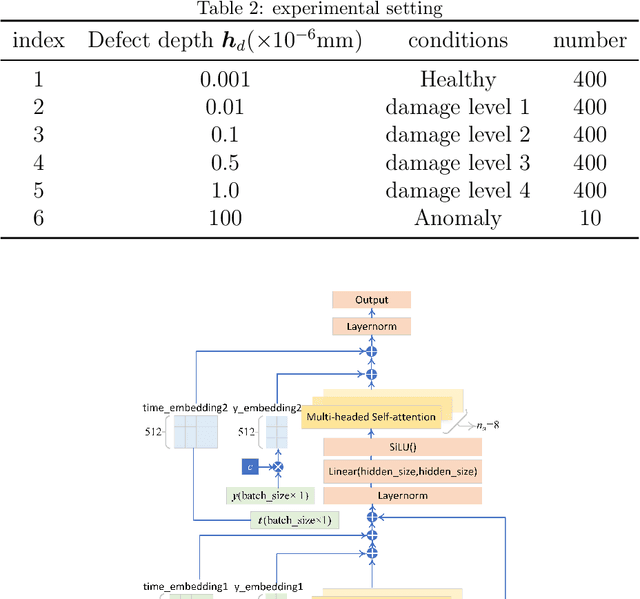
Deriving health indicators of rotating machines is crucial for their maintenance. However, this process is challenging for the prevalent adopted intelligent methods since they may take the whole data distributions, not only introducing noise interference but also lacking the explainability. To address these issues, we propose a diffusion-based weakly-supervised approach for deriving health indicators of rotating machines, enabling early fault detection and continuous monitoring of condition evolution. This approach relies on a classifier-free diffusion model trained using healthy samples and a few anomalies. This model generates healthy samples. and by comparing the differences between the original samples and the generated ones in the envelope spectrum, we construct an anomaly map that clearly identifies faults. Health indicators are then derived, which can explain the fault types and mitigate noise interference. Comparative studies on two cases demonstrate that the proposed method offers superior health monitoring effectiveness and robustness compared to baseline models.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024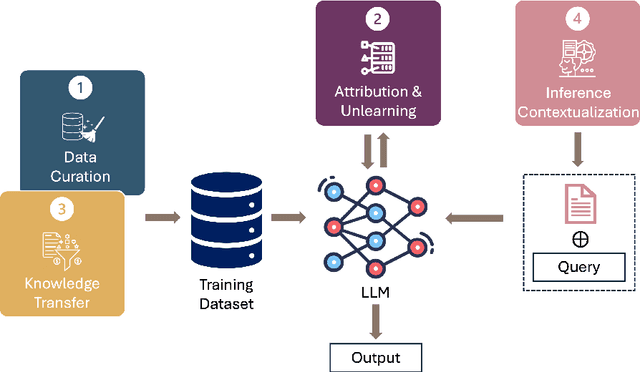
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Prompt Optimization with EASE? Efficient Ordering-aware Automated Selection of Exemplars
May 25, 2024



Large language models (LLMs) have shown impressive capabilities in real-world applications. The capability of in-context learning (ICL) allows us to adapt an LLM to downstream tasks by including input-label exemplars in the prompt without model fine-tuning. However, the quality of these exemplars in the prompt greatly impacts performance, highlighting the need for an effective automated exemplar selection method. Recent studies have explored retrieval-based approaches to select exemplars tailored to individual test queries, which can be undesirable due to extra test-time computation and an increased risk of data exposure. Moreover, existing methods fail to adequately account for the impact of exemplar ordering on the performance. On the other hand, the impact of the instruction, another essential component in the prompt given to the LLM, is often overlooked in existing exemplar selection methods. To address these challenges, we propose a novel method named EASE, which leverages the hidden embedding from a pre-trained language model to represent ordered sets of exemplars and uses a neural bandit algorithm to optimize the sets of exemplars while accounting for exemplar ordering. Our EASE can efficiently find an ordered set of exemplars that performs well for all test queries from a given task, thereby eliminating test-time computation. Importantly, EASE can be readily extended to jointly optimize both the exemplars and the instruction. Through extensive empirical evaluations (including novel tasks), we demonstrate the superiority of EASE over existing methods, and reveal practical insights about the impact of exemplar selection on ICL, which may be of independent interest. Our code is available at https://github.com/ZhaoxuanWu/EASE-Prompt-Optimization.
Localized Zeroth-Order Prompt Optimization
Mar 05, 2024



The efficacy of large language models (LLMs) in understanding and generating natural language has aroused a wide interest in developing prompt-based methods to harness the power of black-box LLMs. Existing methodologies usually prioritize a global optimization for finding the global optimum, which however will perform poorly in certain tasks. This thus motivates us to re-think the necessity of finding a global optimum in prompt optimization. To answer this, we conduct a thorough empirical study on prompt optimization and draw two major insights. Contrasting with the rarity of global optimum, local optima are usually prevalent and well-performed, which can be more worthwhile for efficient prompt optimization (Insight I). The choice of the input domain, covering both the generation and the representation of prompts, affects the identification of well-performing local optima (Insight II). Inspired by these insights, we propose a novel algorithm, namely localized zeroth-order prompt optimization (ZOPO), which incorporates a Neural Tangent Kernel-based derived Gaussian process into standard zeroth-order optimization for an efficient search of well-performing local optima in prompt optimization. Remarkably, ZOPO outperforms existing baselines in terms of both the optimization performance and the query efficiency, which we demonstrate through extensive experiments.
A Spatial-Temporal Transformer based Framework For Human Pose Assessment And Correction in Education Scenarios
Nov 01, 2023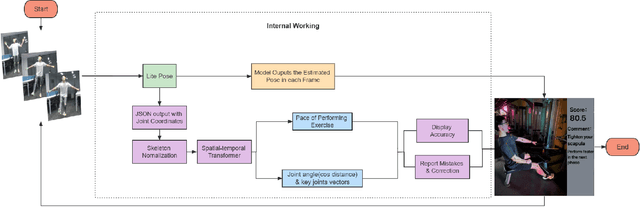
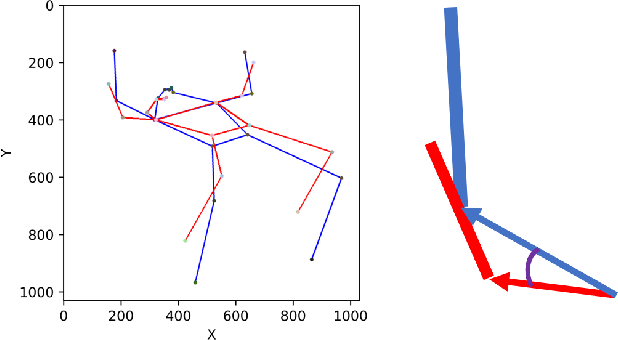

Human pose assessment and correction play a crucial role in applications across various fields, including computer vision, robotics, sports analysis, healthcare, and entertainment. In this paper, we propose a Spatial-Temporal Transformer based Framework (STTF) for human pose assessment and correction in education scenarios such as physical exercises and science experiment. The framework comprising skeletal tracking, pose estimation, posture assessment, and posture correction modules to educate students with professional, quick-to-fix feedback. We also create a pose correction method to provide corrective feedback in the form of visual aids. We test the framework with our own dataset. It comprises (a) new recordings of five exercises, (b) existing recordings found on the internet of the same exercises, and (c) corrective feedback on the recordings by professional athletes and teachers. Results show that our model can effectively measure and comment on the quality of students' actions. The STTF leverages the power of transformer models to capture spatial and temporal dependencies in human poses, enabling accurate assessment and effective correction of students' movements.
Use Your INSTINCT: INSTruction optimization usIng Neural bandits Coupled with Transformers
Oct 02, 2023Large language models (LLMs) have shown remarkable instruction-following capabilities and achieved impressive performances in various applications. However, the performances of LLMs depend heavily on the instructions given to them, which are typically manually tuned with substantial human efforts. Recent work has used the query-efficient Bayesian optimization (BO) algorithm to automatically optimize the instructions given to black-box LLMs. However, BO usually falls short when optimizing highly sophisticated (e.g., high-dimensional) objective functions, such as the functions mapping an instruction to the performance of an LLM. This is mainly due to the limited expressive power of the Gaussian process (GP) model which is used by BO as a surrogate to model the objective function. Meanwhile, it has been repeatedly shown that neural networks (NNs), especially pre-trained transformers, possess strong expressive power and can model highly complex functions. So, we adopt a neural bandit algorithm which replaces the GP in BO by an NN surrogate to optimize instructions for black-box LLMs. More importantly, the neural bandit algorithm allows us to naturally couple the NN surrogate with the hidden representation learned by a pre-trained transformer (i.e., an open-source LLM), which significantly boosts its performance. These motivate us to propose our INSTruction optimization usIng Neural bandits Coupled with Transformers} (INSTINCT) algorithm. We perform instruction optimization for ChatGPT and use extensive experiments to show that our INSTINCT consistently outperforms the existing methods in different tasks, such as in various instruction induction tasks and the task of improving the zero-shot chain-of-thought instruction.
GTC: Guided Training of CTC Towards Efficient and Accurate Scene Text Recognition
Feb 04, 2020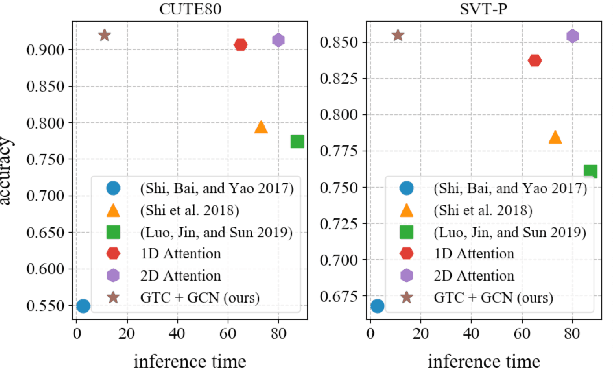


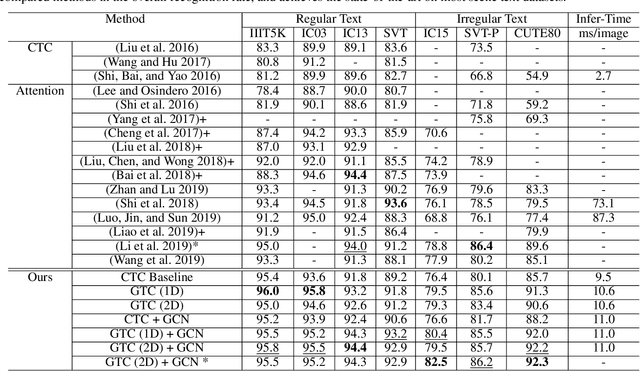
Connectionist Temporal Classification (CTC) and attention mechanism are two main approaches used in recent scene text recognition works. Compared with attention-based methods, CTC decoder has a much shorter inference time, yet a lower accuracy. To design an efficient and effective model, we propose the guided training of CTC (GTC), where CTC model learns a better alignment and feature representations from a more powerful attentional guidance. With the benefit of guided training, CTC model achieves robust and accurate prediction for both regular and irregular scene text while maintaining a fast inference speed. Moreover, to further leverage the potential of CTC decoder, a graph convolutional network (GCN) is proposed to learn the local correlations of extracted features. Extensive experiments on standard benchmarks demonstrate that our end-to-end model achieves a new state-of-the-art for regular and irregular scene text recognition and needs 6 times shorter inference time than attentionbased methods.