 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
WaterDrum: Watermarking for Data-centric Unlearning Metric
May 08, 2025Large language model (LLM) unlearning is critical in real-world applications where it is necessary to efficiently remove the influence of private, copyrighted, or harmful data from some users. However, existing utility-centric unlearning metrics (based on model utility) may fail to accurately evaluate the extent of unlearning in realistic settings such as when (a) the forget and retain set have semantically similar content, (b) retraining the model from scratch on the retain set is impractical, and/or (c) the model owner can improve the unlearning metric without directly performing unlearning on the LLM. This paper presents the first data-centric unlearning metric for LLMs called WaterDrum that exploits robust text watermarking for overcoming these limitations. We also introduce new benchmark datasets for LLM unlearning that contain varying levels of similar data points and can be used to rigorously evaluate unlearning algorithms using WaterDrum. Our code is available at https://github.com/lululu008/WaterDrum and our new benchmark datasets are released at https://huggingface.co/datasets/Glow-AI/WaterDrum-Ax.
Broaden your SCOPE! Efficient Multi-turn Conversation Planning for LLMs using Semantic Space
Mar 14, 2025Large language models (LLMs) are used in chatbots or AI assistants to hold conversations with a human user. In such applications, the quality (e.g., user engagement, safety) of a conversation is important and can only be exactly known at the end of the conversation. To maximize its expected quality, conversation planning reasons about the stochastic transitions within a conversation to select the optimal LLM response at each turn. Existing simulation-based conversation planning algorithms typically select the optimal response by simulating future conversations with a large number of LLM queries at every turn. However, this process is extremely time-consuming and hence impractical for real-time conversations. This paper presents a novel approach called Semantic space COnversation Planning with improved Efficiency (SCOPE) that exploits the dense semantic representation of conversations to perform conversation planning efficiently. In particular, SCOPE models the stochastic transitions in conversation semantics and their associated rewards to plan entirely within the semantic space. This allows us to select the optimal LLM response at every conversation turn without needing additional LLM queries for simulation. As a result, SCOPE can perform conversation planning 70 times faster than conventional simulation-based planning algorithms when applied to a wide variety of conversation starters and two reward functions seen in the real world, yet achieving a higher reward within a practical planning budget. Our code can be found at: https://github.com/chenzhiliang94/convo-plan-SCOPE.
Cross-Patient Pseudo Bags Generation and Curriculum Contrastive Learning for Imbalanced Multiclassification of Whole Slide Image
Nov 18, 2024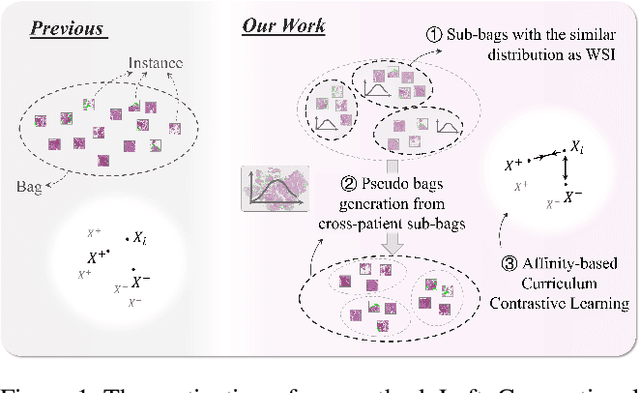
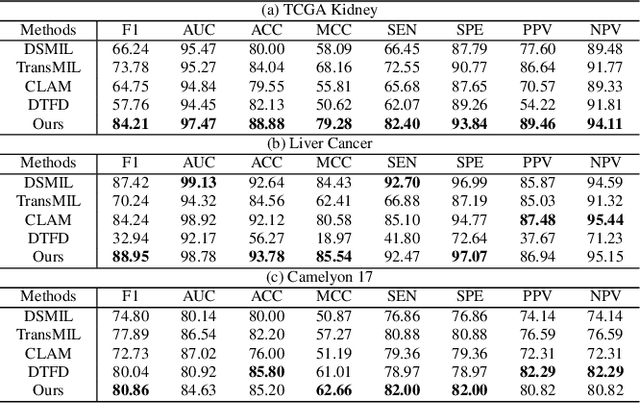
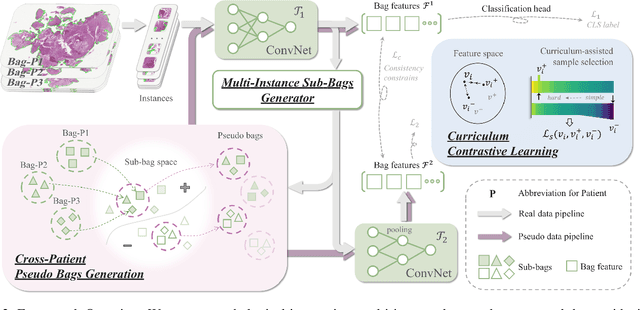
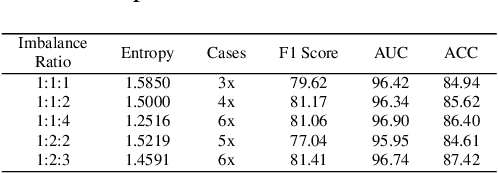
Pathology computing has dramatically improved pathologists' workflow and diagnostic decision-making processes. Although computer-aided diagnostic systems have shown considerable value in whole slide image (WSI) analysis, the problem of multi-classification under sample imbalance remains an intractable challenge. To address this, we propose learning fine-grained information by generating sub-bags with feature distributions similar to the original WSIs. Additionally, we utilize a pseudo-bag generation algorithm to further leverage the abundant and redundant information in WSIs, allowing efficient training in unbalanced-sample multi-classification tasks. Furthermore, we introduce an affinity-based sample selection and curriculum contrastive learning strategy to enhance the stability of model representation learning. Unlike previous approaches, our framework transitions from learning bag-level representations to understanding and exploiting the feature distribution of multi-instance bags. Our method demonstrates significant performance improvements on three datasets, including tumor classification and lymph node metastasis. On average, it achieves a 4.39-point improvement in F1 score compared to the second-best method across the three tasks, underscoring its superior performance.
Waterfall: Framework for Robust and Scalable Text Watermarking
Jul 05, 2024Protecting intellectual property (IP) of text such as articles and code is increasingly important, especially as sophisticated attacks become possible, such as paraphrasing by large language models (LLMs) or even unauthorized training of LLMs on copyrighted text to infringe such IP. However, existing text watermarking methods are not robust enough against such attacks nor scalable to millions of users for practical implementation. In this paper, we propose Waterfall, the first training-free framework for robust and scalable text watermarking applicable across multiple text types (e.g., articles, code) and languages supportable by LLMs, for general text and LLM data provenance. Waterfall comprises several key innovations, such as being the first to use LLM as paraphrasers for watermarking along with a novel combination of techniques that are surprisingly effective in achieving robust verifiability and scalability. We empirically demonstrate that Waterfall achieves significantly better scalability, robust verifiability, and computational efficiency compared to SOTA article-text watermarking methods, and also showed how it could be directly applied to the watermarking of code.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024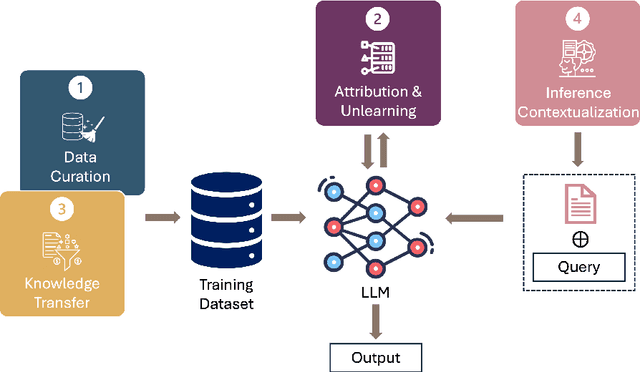
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.