 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Patient Pseudo Bags Generation and Curriculum Contrastive Learning for Imbalanced Multiclassification of Whole Slide Image
Nov 18, 2024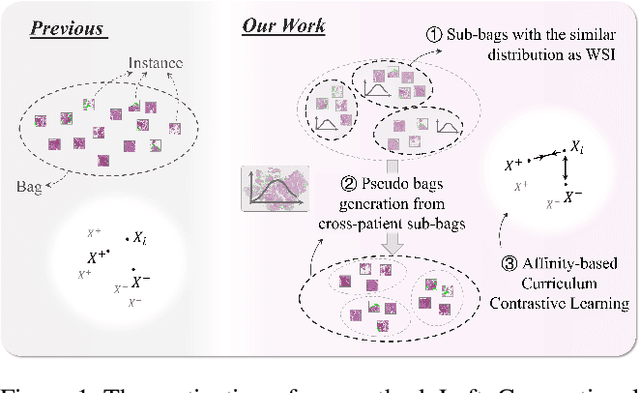
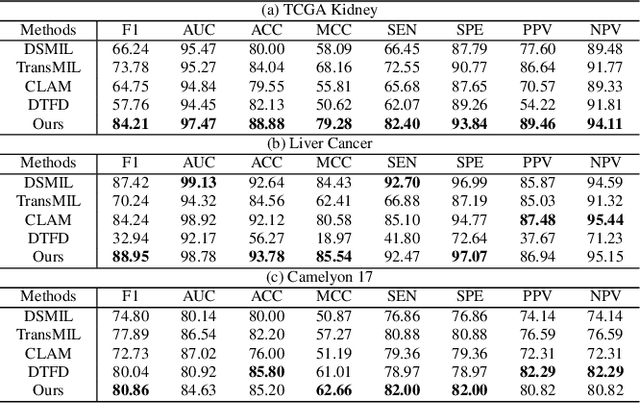
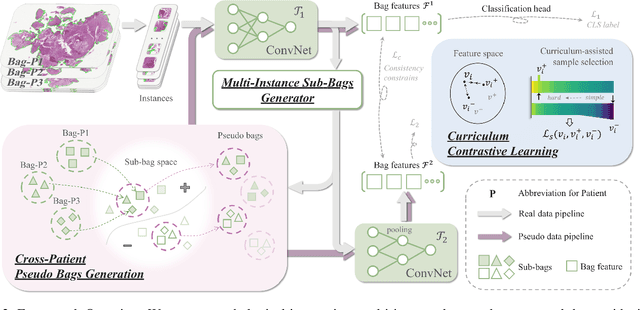
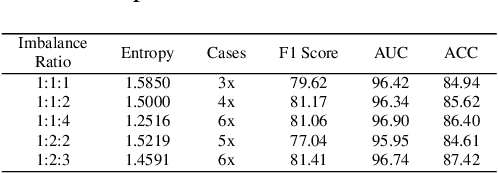
Pathology computing has dramatically improved pathologists' workflow and diagnostic decision-making processes. Although computer-aided diagnostic systems have shown considerable value in whole slide image (WSI) analysis, the problem of multi-classification under sample imbalance remains an intractable challenge. To address this, we propose learning fine-grained information by generating sub-bags with feature distributions similar to the original WSIs. Additionally, we utilize a pseudo-bag generation algorithm to further leverage the abundant and redundant information in WSIs, allowing efficient training in unbalanced-sample multi-classification tasks. Furthermore, we introduce an affinity-based sample selection and curriculum contrastive learning strategy to enhance the stability of model representation learning. Unlike previous approaches, our framework transitions from learning bag-level representations to understanding and exploiting the feature distribution of multi-instance bags. Our method demonstrates significant performance improvements on three datasets, including tumor classification and lymph node metastasis. On average, it achieves a 4.39-point improvement in F1 score compared to the second-best method across the three tasks, underscoring its superior performance.
A Heterogeneous Graph Neural Network Fusing Functional and Structural Connectivity for MCI Diagnosis
Nov 13, 2024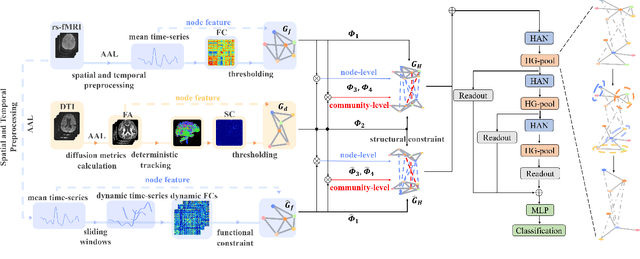
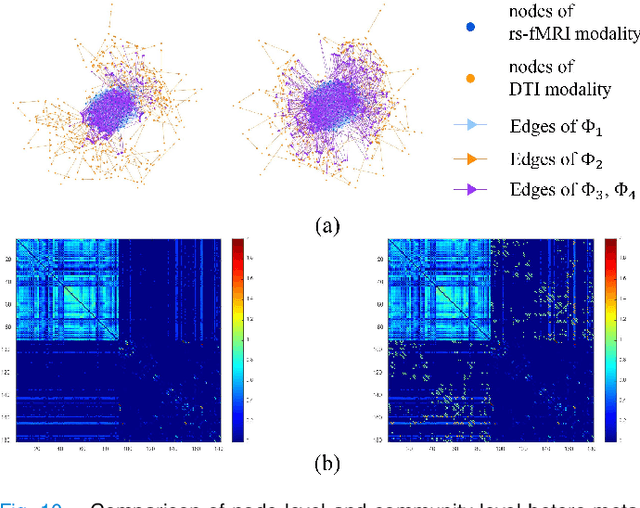
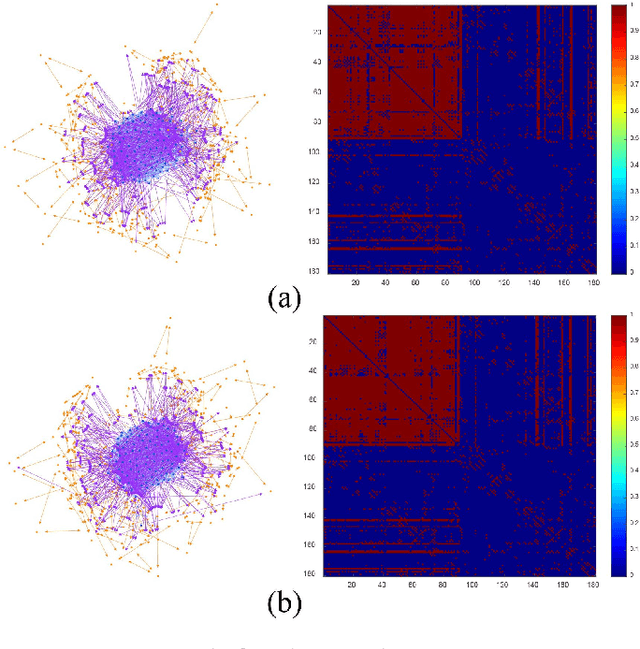
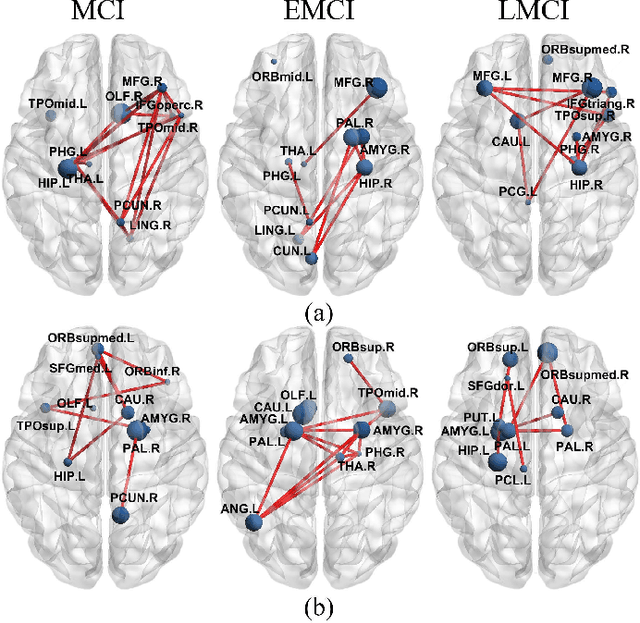
Brain connectivity alternations associated with brain disorders have been widely reported in resting-state functional imaging (rs-fMRI) and diffusion tensor imaging (DTI). While many dual-modal fusion methods based on graph neural networks (GNNs) have been proposed, they generally follow homogenous fusion ways ignoring rich heterogeneity of dual-modal information. To address this issue, we propose a novel method that integrates functional and structural connectivity based on heterogeneous graph neural networks (HGNNs) to better leverage the rich heterogeneity in dual-modal images. We firstly use blood oxygen level dependency and whiter matter structure information provided by rs-fMRI and DTI to establish homo-meta-path, capturing node relationships within the same modality. At the same time, we propose to establish hetero-meta-path based on structure-function coupling and brain community searching to capture relations among cross-modal nodes. Secondly, we further introduce a heterogeneous graph pooling strategy that automatically balances homo- and hetero-meta-path, effectively leveraging heterogeneous information and preventing feature confusion after pooling. Thirdly, based on the flexibility of heterogeneous graphs, we propose a heterogeneous graph data augmentation approach that can conveniently address the sample imbalance issue commonly seen in clinical diagnosis. We evaluate our method on ADNI-3 dataset for mild cognitive impairment (MCI) diagnosis. Experimental results indicate the proposed method is effective and superior to other algorithms, with a mean classification accuracy of 93.3%.
TASL-Net: Tri-Attention Selective Learning Network for Intelligent Diagnosis of Bimodal Ultrasound Video
Sep 03, 2024In the intelligent diagnosis of bimodal (gray-scale and contrast-enhanced) ultrasound videos, medical domain knowledge such as the way sonographers browse videos, the particular areas they emphasize, and the features they pay special attention to, plays a decisive role in facilitating precise diagnosis. Embedding medical knowledge into the deep learning network can not only enhance performance but also boost clinical confidence and reliability of the network. However, it is an intractable challenge to automatically focus on these person- and disease-specific features in videos and to enable networks to encode bimodal information comprehensively and efficiently. This paper proposes a novel Tri-Attention Selective Learning Network (TASL-Net) to tackle this challenge and automatically embed three types of diagnostic attention of sonographers into a mutual transformer framework for intelligent diagnosis of bimodal ultrasound videos. Firstly, a time-intensity-curve-based video selector is designed to mimic the temporal attention of sonographers, thus removing a large amount of redundant information while improving computational efficiency of TASL-Net. Then, to introduce the spatial attention of the sonographers for contrast-enhanced video analysis, we propose the earliest-enhanced position detector based on structural similarity variation, on which the TASL-Net is made to focus on the differences of perfusion variation inside and outside the lesion. Finally, by proposing a mutual encoding strategy that combines convolution and transformer, TASL-Net possesses bimodal attention to structure features on gray-scale videos and to perfusion variations on contrast-enhanced videos. These modules work collaboratively and contribute to superior performance. We conduct a detailed experimental validation of TASL-Net's performance on three datasets, including lung, breast, and liver.
UrBench: A Comprehensive Benchmark for Evaluating Large Multimodal Models in Multi-View Urban Scenarios
Aug 30, 2024Recent evaluations of Large Multimodal Models (LMMs) have explored their capabilities in various domains, with only few benchmarks specifically focusing on urban environments. Moreover, existing urban benchmarks have been limited to evaluating LMMs with basic region-level urban tasks under singular views, leading to incomplete evaluations of LMMs' abilities in urban environments. To address these issues, we present UrBench, a comprehensive benchmark designed for evaluating LMMs in complex multi-view urban scenarios. UrBench contains 11.6K meticulously curated questions at both region-level and role-level that cover 4 task dimensions: Geo-Localization, Scene Reasoning, Scene Understanding, and Object Understanding, totaling 14 task types. In constructing UrBench, we utilize data from existing datasets and additionally collect data from 11 cities, creating new annotations using a cross-view detection-matching method. With these images and annotations, we then integrate LMM-based, rule-based, and human-based methods to construct large-scale high-quality questions. Our evaluations on 21 LMMs show that current LMMs struggle in the urban environments in several aspects. Even the best performing GPT-4o lags behind humans in most tasks, ranging from simple tasks such as counting to complex tasks such as orientation, localization and object attribute recognition, with an average performance gap of 17.4%. Our benchmark also reveals that LMMs exhibit inconsistent behaviors with different urban views, especially with respect to understanding cross-view relations. UrBench datasets and benchmark results will be publicly available at https://opendatalab.github.io/UrBench/.
Fine-Grained Building Function Recognition from Street-View Images via Geometry-Aware Semi-Supervised Learning
Aug 18, 2024



In this work, we propose a geometry-aware semi-supervised method for fine-grained building function recognition. This method leverages the geometric relationships between multi-source data to improve the accuracy of pseudo labels in semi-supervised learning, extending the task's scope and making it applicable to cross-categorization systems of building function recognition. Firstly, we design an online semi-supervised pre-training stage, which facilitates the precise acquisition of building facade location information in street-view images. In the second stage, we propose a geometry-aware coarse annotation generation module. This module effectively combines GIS data and street-view data based on the geometric relationships, improving the accuracy of pseudo annotations. In the third stage, we combine the newly generated coarse annotations with the existing labeled dataset to achieve fine-grained functional recognition of buildings across multiple cities at a large scale. Extensive experiments demonstrate that our proposed framework exhibits superior performance in fine-grained functional recognition of buildings. Within the same categorization system, it achieves improvements of 7.6% and 4.8% compared to fully-supervised methods and state-of-the-art semi-supervised methods, respectively. Additionally, our method also performs well in cross-city tasks, i.e., extending the model trained on OmniCity (New York) to new areas (i.e., Los Angeles and Boston). This study provides a novel solution for the fine-grained function recognition of large-scale buildings across multiple cities, offering essential data for understanding urban infrastructure planning, human activity patterns, and the interactions between humans and buildings.
Cross-view image geo-localization with Panorama-BEV Co-Retrieval Network
Aug 10, 2024Cross-view geolocalization identifies the geographic location of street view images by matching them with a georeferenced satellite database. Significant challenges arise due to the drastic appearance and geometry differences between views. In this paper, we propose a new approach for cross-view image geo-localization, i.e., the Panorama-BEV Co-Retrieval Network. Specifically, by utilizing the ground plane assumption and geometric relations, we convert street view panorama images into the BEV view, reducing the gap between street panoramas and satellite imagery. In the existing retrieval of street view panorama images and satellite images, we introduce BEV and satellite image retrieval branches for collaborative retrieval. By retaining the original street view retrieval branch, we overcome the limited perception range issue of BEV representation. Our network enables comprehensive perception of both the global layout and local details around the street view capture locations. Additionally, we introduce CVGlobal, a global cross-view dataset that is closer to real-world scenarios. This dataset adopts a more realistic setup, with street view directions not aligned with satellite images. CVGlobal also includes cross-regional, cross-temporal, and street view to map retrieval tests, enabling a comprehensive evaluation of algorithm performance. Our method excels in multiple tests on common cross-view datasets such as CVUSA, CVACT, VIGOR, and our newly introduced CVGlobal, surpassing the current state-of-the-art approaches. The code and datasets can be found at \url{https://github.com/yejy53/EP-BEV}.
SkyDiffusion: Street-to-Satellite Image Synthesis with Diffusion Models and BEV Paradigm
Aug 03, 2024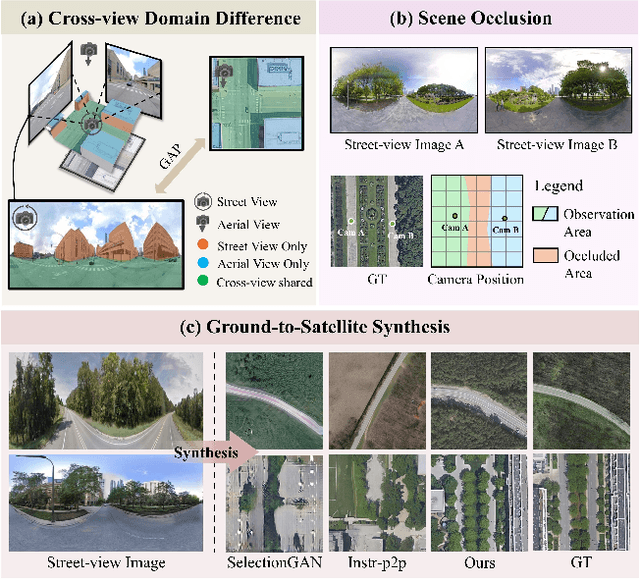



Street-to-satellite image synthesis focuses on generating realistic satellite images from corresponding ground street-view images while maintaining a consistent content layout, similar to looking down from the sky. The significant differences in perspectives create a substantial domain gap between the views, making this cross-view generation task particularly challenging. In this paper, we introduce SkyDiffusion, a novel cross-view generation method for synthesizing satellite images from street-view images, leveraging diffusion models and Bird's Eye View (BEV) paradigm. First, we design a Curved-BEV method to transform street-view images to the satellite view, reformulating the challenging cross-domain image synthesis task into a conditional generation problem. Curved-BEV also includes a "Multi-to-One" mapping strategy for combining multiple street-view images within the same satellite coverage area, effectively solving the occlusion issues in dense urban scenes. Next, we design a BEV-controlled diffusion model to generate satellite images consistent with the street-view content, which also incorporates a light manipulation module to optimize the lighting condition of the synthesized image using a reference satellite. Experimental results demonstrate that SkyDiffusion outperforms state-of-the-art methods on both suburban (CVUSA & CVACT) and urban (VIGOR-Chicago) cross-view datasets, with an average SSIM increase of 14.5% and a FID reduction of 29.6%, achieving realistic and content-consistent satellite image generation. The code and models of this work will be released at https://opendatalab.github.io/skydiffusion/.
SG-BEV: Satellite-Guided BEV Fusion for Cross-View Semantic Segmentation
Apr 03, 2024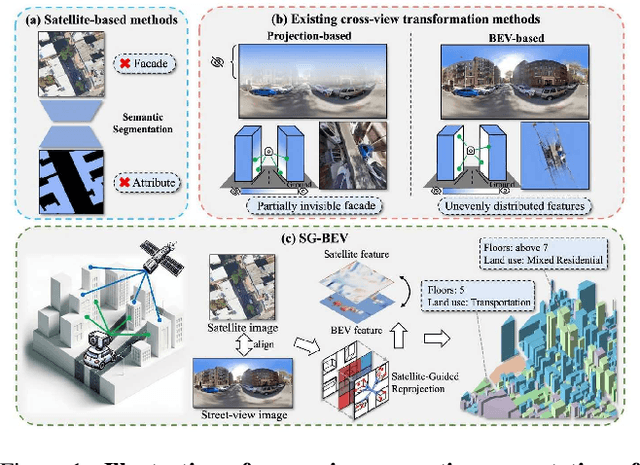

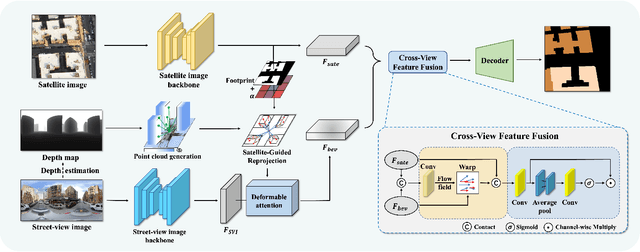

This paper aims at achieving fine-grained building attribute segmentation in a cross-view scenario, i.e., using satellite and street-view image pairs. The main challenge lies in overcoming the significant perspective differences between street views and satellite views. In this work, we introduce SG-BEV, a novel approach for satellite-guided BEV fusion for cross-view semantic segmentation. To overcome the limitations of existing cross-view projection methods in capturing the complete building facade features, we innovatively incorporate Bird's Eye View (BEV) method to establish a spatially explicit mapping of street-view features. Moreover, we fully leverage the advantages of multiple perspectives by introducing a novel satellite-guided reprojection module, optimizing the uneven feature distribution issues associated with traditional BEV methods. Our method demonstrates significant improvements on four cross-view datasets collected from multiple cities, including New York, San Francisco, and Boston. On average across these datasets, our method achieves an increase in mIOU by 10.13% and 5.21% compared with the state-of-the-art satellite-based and cross-view methods. The code and datasets of this work will be released at https://github.com/yejy53/SG-BEV.
PainSeeker: An Automated Method for Assessing Pain in Rats Through Facial Expressions
Nov 06, 2023In this letter, we aim to investigate whether laboratory rats' pain can be automatically assessed through their facial expressions. To this end, we began by presenting a publicly available dataset called RatsPain, consisting of 1,138 facial images captured from six rats that underwent an orthodontic treatment operation. Each rat' facial images in RatsPain were carefully selected from videos recorded either before or after the operation and well labeled by eight annotators according to the Rat Grimace Scale (RGS). We then proposed a novel deep learning method called PainSeeker for automatically assessing pain in rats via facial expressions. PainSeeker aims to seek pain-related facial local regions that facilitate learning both pain discriminative and head pose robust features from facial expression images. To evaluate the PainSeeker, we conducted extensive experiments on the RatsPain dataset. The results demonstrate the feasibility of assessing rats' pain from their facial expressions and also verify the effectiveness of the proposed PainSeeker in addressing this emerging but intriguing problem. The RasPain dataset can be freely obtained from https://github.com/xhzongyuan/RatsPain.
OmniCity: Omnipotent City Understanding with Multi-level and Multi-view Images
Aug 04, 2022



This paper presents OmniCity, a new dataset for omnipotent city understanding from multi-level and multi-view images. More precisely, the OmniCity contains multi-view satellite images as well as street-level panorama and mono-view images, constituting over 100K pixel-wise annotated images that are well-aligned and collected from 25K geo-locations in New York City. To alleviate the substantial pixel-wise annotation efforts, we propose an efficient street-view image annotation pipeline that leverages the existing label maps of satellite view and the transformation relations between different views (satellite, panorama, and mono-view). With the new OmniCity dataset, we provide benchmarks for a variety of tasks including building footprint extraction, height estimation, and building plane/instance/fine-grained segmentation. Compared with the existing multi-level and multi-view benchmarks, OmniCity contains a larger number of images with richer annotation types and more views, provides more benchmark results of state-of-the-art models, and introduces a novel task for fine-grained building instance segmentation on street-level panorama images. Moreover, OmniCity provides new problem settings for existing tasks, such as cross-view image matching, synthesis, segmentation, detection, etc., and facilitates the developing of new methods for large-scale city understanding, reconstruction, and simulation. The OmniCity dataset as well as the benchmarks will be available at https://city-super.github.io/omnicity.